






需要抓取网页上面的指定元素:
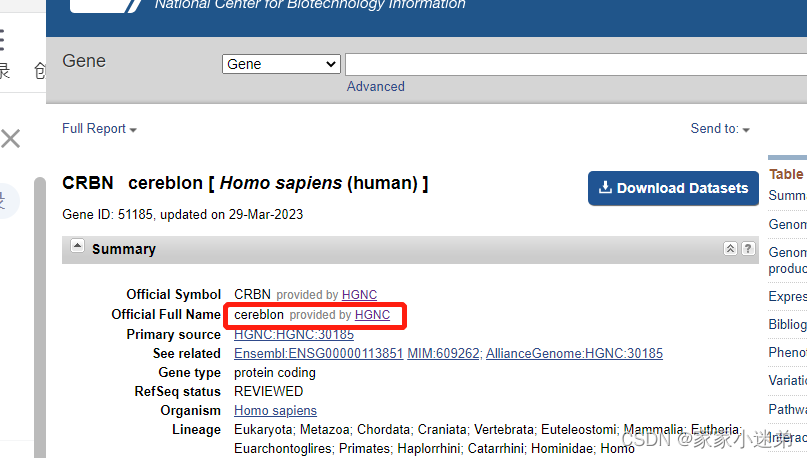
本来考虑使用webMagic,但是那个感觉有点复杂了,这里直接使用Jsoup来抓取:
1、导入依赖:
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.14.1</version>
</dependency>
2、创建连接,解析页面元素
首先定义url:
String url="https://ncbi.nlm.nih.gov/gene/51185";
再创建连接,通过get请求,拿到网页的document对象:
简单版的:
Document document = Jsoup.connect(url).get();
但是需要在类上抛出异常,这里使用捕获的方式以便处理错误:
Connection conn = Jsoup.connect(url);
Document document = null;
try {
document = conn.get();
} catch (IOException e) {
e.printStackTrace();
// handle error
}
分析页面元素:
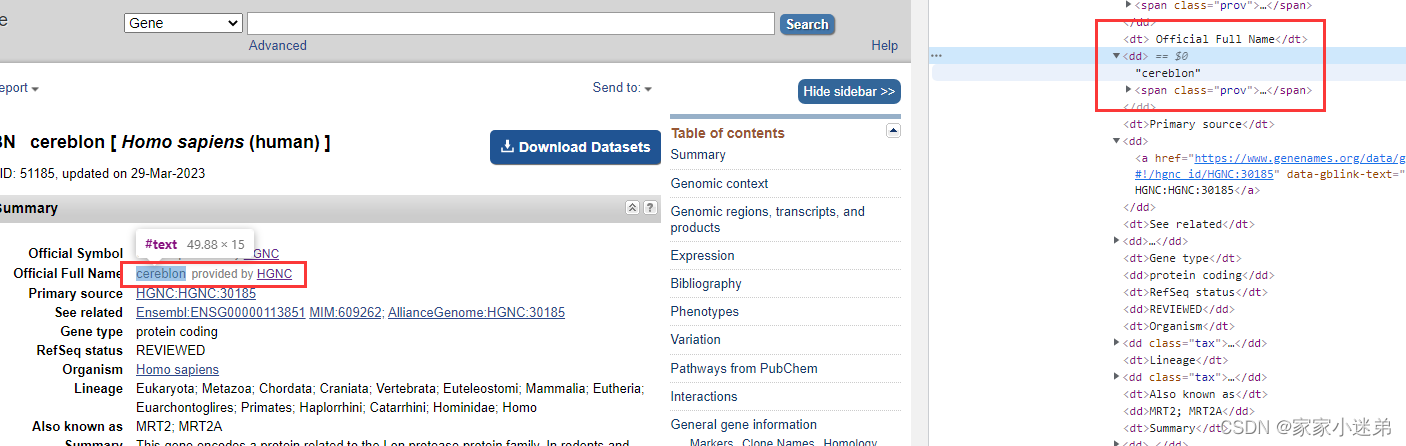
选择到对应的元素:这里jsoup的语法就不贴了
Element firstHeading = document.getElementsByClass("rprt-section gene-summary").first();
Elements noline = firstHeading.getElementsByTag("dd");
String element = noline.get(1).text();
但是抓取的内容有点多了:
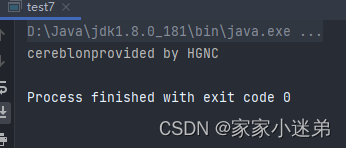
这里只需要cereblon,可以查出provided在结果中第一次出现的位置,然后使用字符串截取的方式,拿到需要的结果:
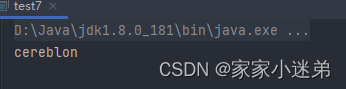
完整代码如下:
public static void main(String[] args) {
String url="https://ncbi.nlm.nih.gov/gene/51185";
Connection conn = Jsoup.connect(url);
Document document = null;
try {
document = conn.get();
} catch (IOException e) {
e.printStackTrace();
// handle error
}
Element firstHeading = document.getElementsByClass("rprt-section gene-summary").first();
Elements noline = firstHeading.getElementsByTag("dd");
String element = noline.get(1).text();
int provided = element.indexOf("provided");
String fullName = element.substring(0, provided);
System.out.println(fullName);
}

















 1658
1658

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









