




 本文介绍Scrapy-Redis组件如何实现增量式与分布式爬虫功能。增量式爬虫通过Redis实现调度器队列和指纹集合,确保请求持久化;分布式爬虫则利用Redis共享数据,使得多台计算机能够协同工作。文中详细说明了Scrapy-Redis的工作流程及其配置。
本文介绍Scrapy-Redis组件如何实现增量式与分布式爬虫功能。增量式爬虫通过Redis实现调度器队列和指纹集合,确保请求持久化;分布式爬虫则利用Redis共享数据,使得多台计算机能够协同工作。文中详细说明了Scrapy-Redis的工作流程及其配置。
scrapy_redis
介绍
scarpy_redis,是scrapy的一个组件,实现增量式爬虫与分布式爬虫。
- 增量式爬虫:通过redis实现调度器的队列和指纹集合,判断dont_filter和requests对象决定请求持久化,持续发起请求。
- 分布式爬虫:通过redis共享数据,多台计算机发起爬虫。
- redis指纹集合通过哈希关系映射数据集合实现数据的去重。
scrapy_redis流程
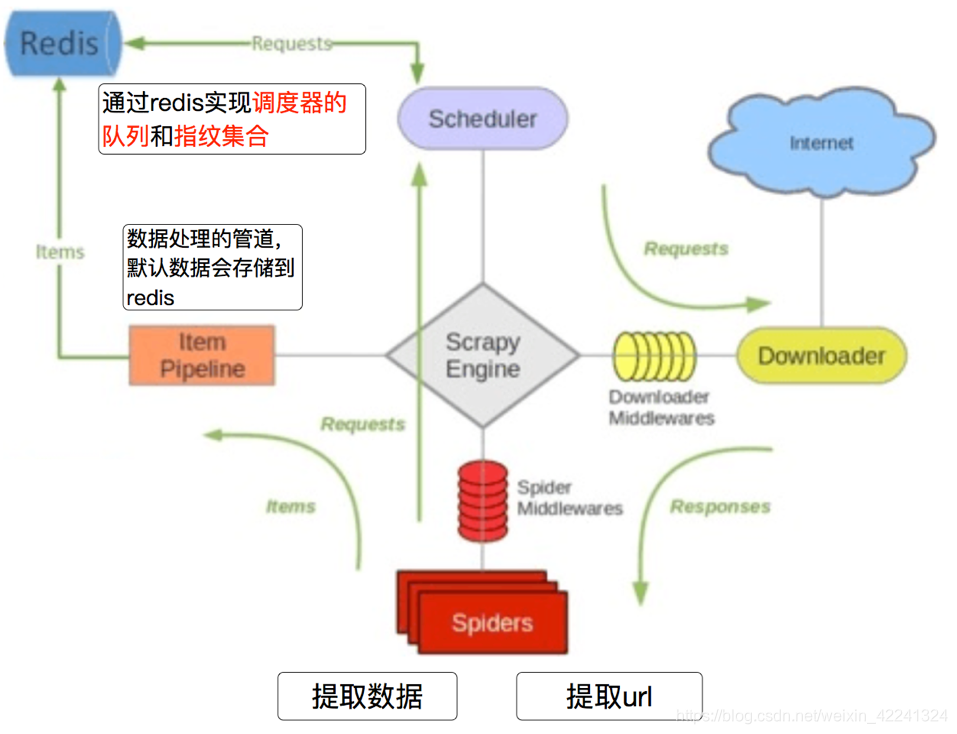
流程:
- 带抓取的对象和去重的指纹都存在所有服务器的公用redis中
- 所有服务器公用一个redis中request对象
- 所有request对象存入redis前,会在同一个redis中进行判断之前是否存入过
- 默认情况下所有数据保存在redis中
增量式爬虫
实现方式:
在settings.py中增加代码:
# 指定了去重的类
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 指定了调度器的类
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 调度器的内容是否持久化
SCHEDULER_PERSIST = True
# redis的url
REDIS_URL = "redis://127.0.0.1:6379"
# 如果数据需要保存到redis中,选配的
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 400,
}
- RFPDupeFilter 实现了对request对象的排序并判断是否存在,及对请求方法、请求体、请求地址进行sha1加密

2.Scheduler调度器决定了什么时候加入带抓取的队列,同时把请求过的request对象过滤掉
3.调度器进行request请求及经过流程返回数据,然后RedisPipeline进行数据保存,并存入redis中

分布式爬虫
RedisSpider
- 继承自父类为RedisSpider
- 增加了一个redis_key的键,没有start_urls,因为分布式中,如果每台电脑都请求一次start_url就会重复
- 多了__init__方法,该方法不是必须的,可以手动指定allow_domains

RedisCrawlSpider
和crawlspider的区别:继承的父类不同


















 476
476

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









