






 本文通过分析电商平台上防脱发洗发水的销售数据,进行了数据采集、清洗和可视化分析。研究发现大部分商品价格在250元以内,评论集中在5000+至100万+之间,其中霸王旗舰店和爱茉莉官方旗舰店销量领先。针对不同头皮和发质,推荐了相应的洗发水选择策略。
本文通过分析电商平台上防脱发洗发水的销售数据,进行了数据采集、清洗和可视化分析。研究发现大部分商品价格在250元以内,评论集中在5000+至100万+之间,其中霸王旗舰店和爱茉莉官方旗舰店销量领先。针对不同头皮和发质,推荐了相应的洗发水选择策略。

就在前段时间,一项由卫健委发起的脱发人群调查数据显示:中国受脱发问题困扰的人群高达2.5亿。听到这儿,远在韩国的各家媒体又开始出来搞事情了。

根据他们的计算,这些人完全脱发时的总脱发面积大约可达5900平方公里,相当于首尔市面积(605平方公里)的十倍,那么今天小编就以一个数据分析师的身份来为这些人群出出主意,挑几款相对合适的防脱发洗发水给他们来使用。



1. 聊聊脱发困扰
脱发其实分为很多种情况,如脂溢性脱发,表现为头屑增多、头皮痛痒、头发油脂分泌旺盛。还有营养性脱发,当饮食作息不规律时,脱发情况就会愈发地严重,以及物理性脱发,有时头发扎太紧、扯伤毛囊,都会造成脱发。

不过大家也不用太过于担心,有研究表明,一个正常人每天脱落80-100根头发属于正常情况,但是如果超过100根就要提高警惕了,极大可能是头发的生长跟不上脱发的速度了。而有一款合适的洗发水,保持头皮的清洁卫生,对于防脱生发也有着极大的帮助,而对于不同头皮发质、不同年龄段的人来说,使用的洗发水也是不尽相同的。



2. 数据采集
数据采集是数据可视化分析的第一步,也是最基础的一步,本文主要是基于从电商平台上抓取一些防脱发类型的洗发水,采集过程如下



2.1 页面分析与程序的编写
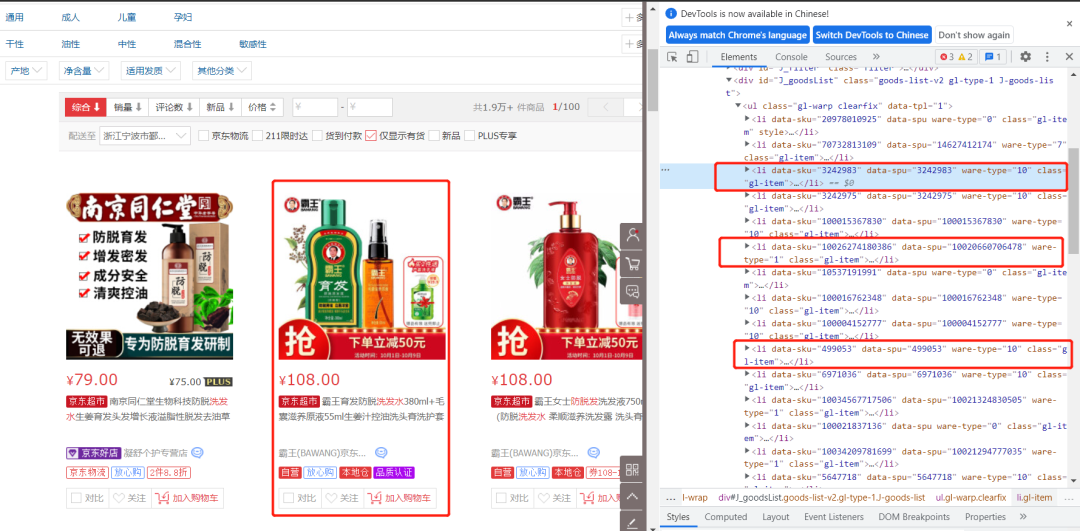
该页面的总共60件商品由两个子页面构成的,每一个子页面分别包含30件商品,通过page参数来进行调节,那么我们请求的构造方式就变得相当简单了,
def get_xxx_html(page):
params = (
('keyword', '\u9632\u8131\u53D1\u6D17\u53D1\u6C34'),
('qrst', '1'),
('suggest', '1.def.0.base'),
('wq', '\u9632\u8131\u53D1\u6D17\u53D1\u6C34'),
('stock', '1'),
('pvid', '4d8b661510984fb5ae2bf68fac6c50c7'),
('page', str(page)),
('s', '27'),
('scrolling', 'y'),
('log_id', '1633307411833.8939'),
('tpl', '1_M'),
('isList', '0'),
)
response = requests.get('https://search.xxxx.com/s_new.php', headers=headers, params=params, proxies=proxies)
response_beau = BeautifulSoup(response.text, 'lxml')
return response_beau通过这个请求,可以获取到的商品信息如下

而针对评论方面的内容,则是以json数据形式存在,比较好解析,而且接口api非常明确,可以直接通过商品id这个参数即可进行请求的获取
params = (
('callback', 'fetchJSON_comment98'),
('productId', str(productId)),
('score', '0'),
('sortType', '5'),
('page', '0'),
('pageSize', '10'),
('isShadowSku', '0'),
('fold', '1'),
)
response = requests.get('https://club.xxxxx.com/comment/productPageComments.action', headers=headers, params=params, cookies=cookies)
response_jsonified = response.text.replace("fetchJSON_comment98", "")[1:-2]
response_jsonified_again = json.loads(response_jsonified)
productCommentSummary = response_jsonified_again.get("productCommentSummary")
commentSum = productCommentSummary.get("commentCountStr")
goodRate = productCommentSummary.get("goodRate")


3.数据清洗
数据采集后,接下来便对其进行数据清洗,去除重复值与脏数据,有助于提高可视化分析的准确性。

导入商品数据
import pandas as pd
df = pd.read_excel("jd_product_info.xlsx")
df.info()

删除重复数据
df.drop_duplicates()
特殊字符处理
df["product_name"] = df["product_name"].str.replace(r'\s','',regex=True)
df["commentSum"] = df["commentSum"].str.replace('+','',regex=True).str.replace('万','0000',regex=True)
df.describe()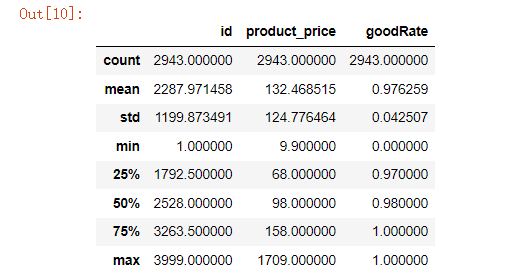



4. 可视化分析
以下我们将从商品的价格分布、评论分布、商品产地分布、旗舰店所卖商品分布,商品功效等维度来进行数据的可视化分析

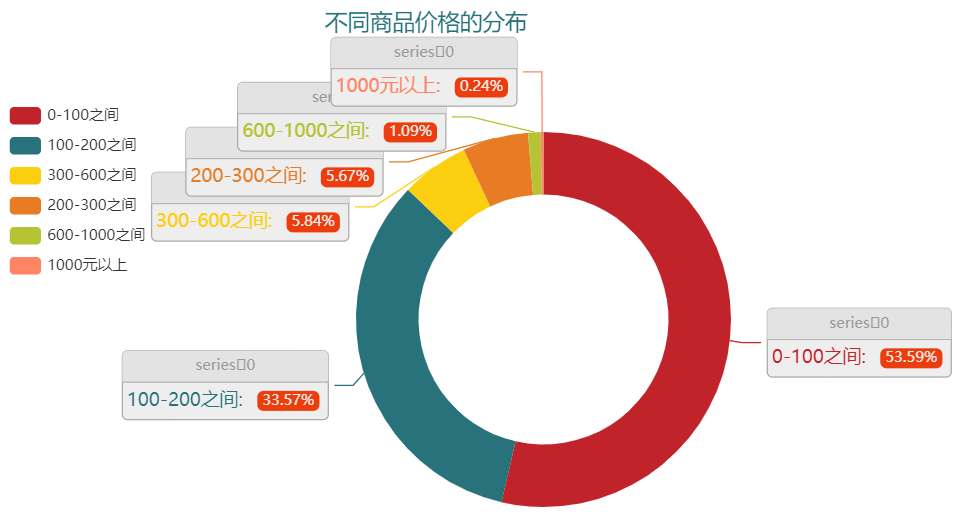
商品价格分布
df["product_price"].plot.hist(stacked = True, bins=20)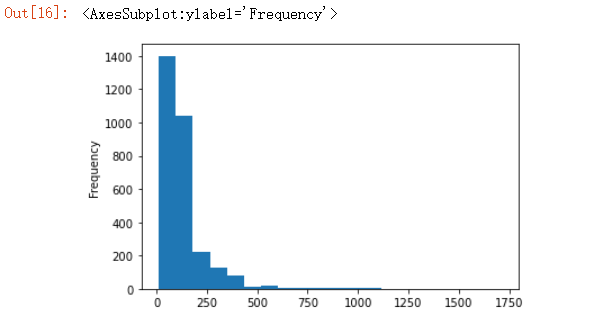
可以看到大部分的商品价格都在250元以内,然后我们对商品的价格区间做一个统计分析
df["product_price_range"] = df["product_price"].apply(lambda x: range_price(x))
df["product_price_range"].value_counts()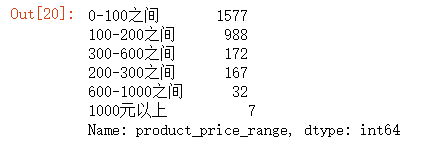

评论数分布
大部分的商品评论数都是在5000+或者是2000+左右,或者是在200以及500左右的评论量,而评论数在50万以上以及100万以上的分别有22个和17个,我们可以基本认定这些类的商品,它的购买量是最多的,我们
df["commentSum"].value_counts().head(8)而评论量在100万以上的基本上都是霸王旗舰店或者是爱茉莉官方旗舰店所售卖的商品
df[df["commentSum"] == "1000000"]["product_shop_name"].value_counts()

哪些旗舰店的商品最多
那么从总体上来看,哪家店铺卖的防脱发的洗发水更多呢,其中“霸王旗舰店”总体上来看也是售卖防脱发类型的产品最多的,其次便是“华贸美妆专营店”和“滋源官方旗舰店”等
df["product_shop_name"].value_counts().head(20)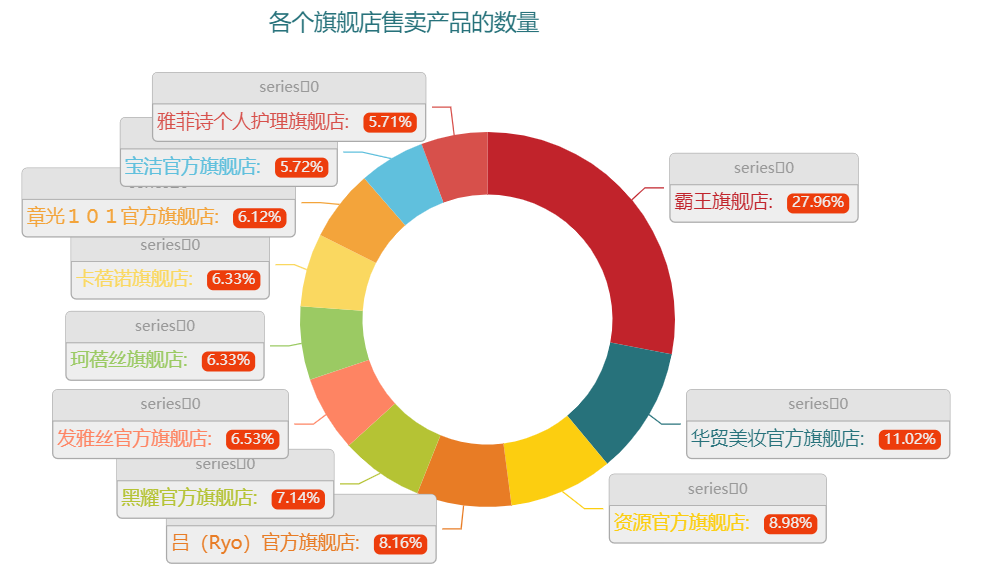

不同头皮与不同发质对应的洗发水
不同头皮、不同发质所对应使用的洗发水不同,例如对于油性头皮,想要“去屑、控油、防脱”功效的洗发水,可以这么来搜索
df_1 = df[df["product_head"] == "适合头皮:油性"]
df_1["commentSum"] = df_1["commentSum"].astype("int")
df_1[df_1["product_function"].str.contains("去屑")].sort_values("commentSum", ascending = False)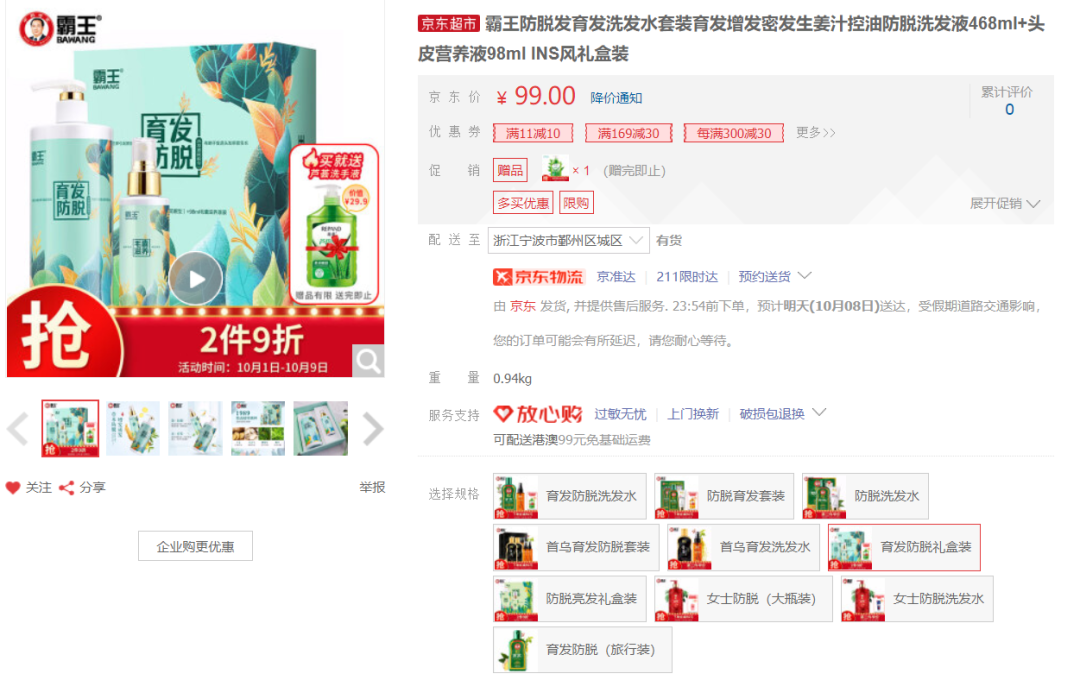
例如对于中性头皮,想要达到控油效果的洗发水,则可以这么来搜索
df_1 = df[df["product_head"] == "适合头皮:中性"]
df_1["commentSum"] = df_1["commentSum"].astype("int")
df_1[df_1["product_function"].str.contains("控油")].sort_values("commentSum", ascending = False)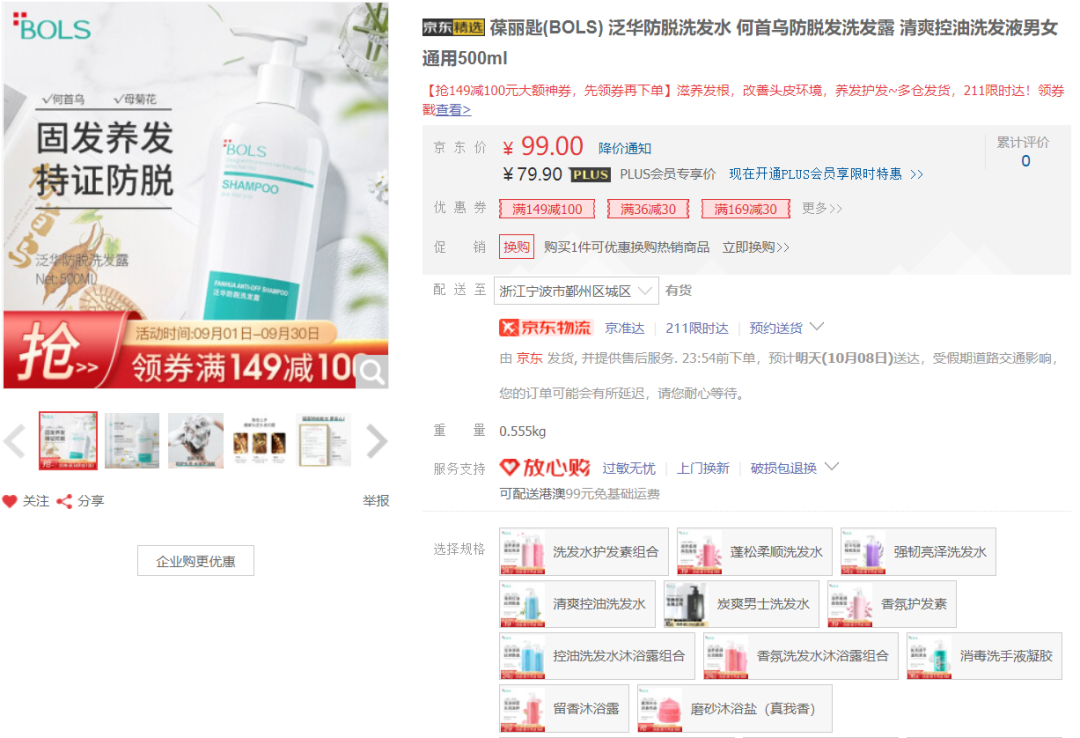

小结
本文仅供学习研究使用,提供的评论仅供参考。如有不妥之处请及时告知作者。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









