




简介:LabVIEW是一种图形编程环境,其中多循环应用程序架构常用于实现复杂系统或多任务并行处理。该DEMO示例演示了如何利用LabVIEW的多循环特性构建高效和可扩展的应用程序。介绍了主循环与子循环的结构、事件和队列结构在循环间通信的作用,以及同步、性能优化和用户界面设计的最佳实践。通过此DEMO,开发者可以学习如何在LabVIEW中设计模块化的多循环应用程序,以应对实时系统和大数据分析的挑战。
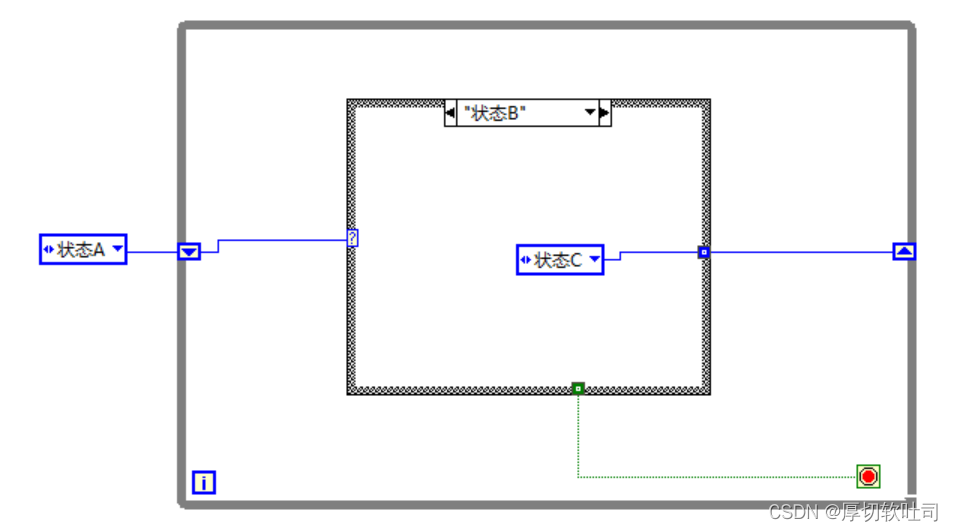
1. LabVIEW多循环架构应用
LabVIEW多循环架构为复杂系统的设计与实现提供了强大的支持。通过使用多个循环,能够更加有效地管理程序中不同任务的并发执行。在多循环架构中,数据的流经、处理和同步成为了保证程序稳定和高效运行的关键。接下来的章节将详细探讨如何设计并优化这些循环架构,以提高系统的性能和响应速度。
- 循环的定义与意义 :在LabVIEW中,循环是一种基本的程序结构,它允许代码块重复执行,直到满足终止条件。循环可以是顺序的,也可以是并行的,基于需求的不同而选择不同的循环类型。
-
多循环架构的优势 :相较于单一循环架构,多循环设计允许程序的各个部分独立运行,互不干扰。例如,在数据采集应用中,主循环可以负责数据的持续采集,而子循环则可以专注于数据的实时分析。这种分离不仅提高了程序的模块化,还利于资源的高效利用和性能的提升。
-
架构设计的考量 :在设计多循环架构时,需要考虑到循环之间的数据通信、同步机制以及如何避免竞争条件等并发编程问题。正确的设计方法可以确保数据的一致性,减少不必要的延迟,提升整体系统的可靠性。
在本章中,我们将针对多循环架构的应用进行深入分析,探索其在实际项目中如何发挥最大效能。后续章节将分别从循环结构、事件结构、队列结构同步与数据传递、性能优化策略以及用户界面设计等方面,进一步展开详述。
2. 主循环与子循环设计
2.1 循环结构的基本概念和分类
循环结构是程序中实现重复任务处理的核心机制。在LabVIEW中,主循环和子循环的设计尤为关键,它们在保持程序架构清晰和运行效率上扮演着重要角色。
2.1.1 主循环的功能和设计方法
主循环是程序的主体部分,它负责整个应用程序的流程控制和数据处理。设计一个有效的主循环需要注意以下几点:
- 确定主循环的结构:主循环通常负责程序的主要功能,包括用户输入、数据处理、设备控制等。
- 控制循环的退出:在LabVIEW中,通过条件结构来判断是否退出循环,例如可以设置布尔标志来控制循环的结束。
- 循环中数据的管理:主循环内需要有效管理数据,包括数据的采集、处理、存储和传递。
示例代码块展示如何在LabVIEW中设计一个简单的主循环:
// 主循环结构的LabVIEW代码块
While Loop // 主循环开始
// 执行主要任务
// 比如读取用户输入、进行数据处理等
// 检查退出条件
// 例如使用一个布尔控件来控制循环
If Stop = TRUE Then
Exit // 满足退出条件时退出循环
End If
End While // 主循环结束
在设计主循环时,要考虑到程序的可扩展性和可维护性,主循环应该足够简单以便于后期的维护和升级。
2.1.2 子循环的作用和应用场景
子循环用于执行更具体和更频繁的任务,它从属于主循环,并在主循环的控制下运行。子循环常见的应用场景包括:
- 数据采集:对于需要周期性读取的传感器数据,可以使用子循环进行高效处理。
- 算法实现:某些特定的算法处理,比如滤波器、数学变换等,可以封装在子循环中。
子循环的设计需要遵循以下原则:
- 保持子循环功能单一,易于理解和维护。
- 确保子循环能够响应主循环的信号,实现任务的同步执行。
- 子循环不应该无限运行,它应该在完成特定任务后返回主循环。
示例代码块展示如何在LabVIEW中设计一个子循环:
// 子循环结构的LabVIEW代码块
For Loop // 子循环开始
// 执行子循环任务
// 比如数据处理算法的实现
End For // 子循环结束
子循环是提高程序效率和管理程序结构的有效手段,因此在设计循环架构时要充分考虑子循环的合理运用。
2.2 循环间的嵌套和同步机制
2.2.1 嵌套循环的设计原则和影响
在LabVIEW中,循环可以嵌套使用,以实现更为复杂的控制流程。嵌套循环的设计原则如下:
- 确保内层循环的独立性,避免内层循环对外层循环产生干扰。
- 控制循环的嵌套深度,过多的嵌套可能导致程序难以理解和维护。
- 优先考虑使用流水线结构来优化循环,以提高程序的运行效率。
嵌套循环的运行效率可能会受到内层循环的复杂度影响。在设计嵌套循环时,需要对循环的各个层次进行性能分析和优化。
示例代码块展示如何在LabVIEW中设计一个嵌套循环:
// 嵌套循环结构的LabVIEW代码块
While Loop // 主循环开始
// 执行主要任务和子循环的初始化
For Loop // 子循环开始
// 执行子循环任务
End For // 子循环结束
// 更新主循环状态和数据
End While // 主循环结束
2.2.2 同步机制的选择与实现
循环间的同步是确保数据正确处理和避免竞争条件的关键。在LabVIEW中实现同步机制的常见方法有:
- 使用同步控件,例如事件结构、条件变量等。
- 通过队列实现循环间的数据传递和同步。
同步机制的选择应该基于应用程序的具体需求和性能目标。正确的同步可以显著提高程序的稳定性和效率。
示例代码块展示如何在LabVIEW中实现循环间的同步:
// 循环间同步的LabVIEW代码块
Event Structure // 事件结构用于循环间通信和同步
// 检测和处理事件
// 例如:使用事件控制循环的启动和停止
同步机制需要根据实际应用进行详细设计,以确保循环的流畅执行和数据的正确同步。
3. 事件结构在循环间通信的作用
3.1 事件驱动编程模型分析
3.1.1 事件的定义和分类
在LabVIEW中,事件驱动编程模型是一种允许程序响应来自用户或其他来源信号的模型。事件可以看作是一个消息,指出了一件需要程序注意的事情,比如用户界面操作、数据变化、错误发生等。LabVIEW的事件可以分为两大类:用户界面事件和程序事件。
用户界面事件是与用户直接交互产生的事件,例如按钮点击、菜单选择等。程序事件则是由程序的某些操作产生的,如定时器事件、数据变化事件、错误事件等。通过这些事件,可以实现程序的异步控制和不同循环间的数据通信。
3.1.2 事件结构的内部机制
事件结构是LabVIEW中用于处理事件的主要控件。它在执行流程中等待事件的发生,并根据发生的事件类型执行不同的分支路径(事件分支)。事件结构由一个事件生成器和一个或多个事件分支构成,事件生成器负责捕获事件,而事件分支则用于处理这些事件。
事件结构内部包含了多种机制来确保正确的分支按顺序执行。它通过一个内部队列来管理等待中的事件,当事件结构进入运行状态时,它将检查队列中的事件,并选择最前面的事件执行对应的事件分支。若分支中包含新的事件生成,则这些新事件会被添加到队列中,待当前事件分支执行完毕后再进行处理。
3.2 事件结构与循环交互的实现方式
3.2.1 触发事件的条件和时机
事件可以通过多种方式触发,比如前面提到的用户界面事件或程序事件。在循环间通信中,事件可以作为同步点,用来控制数据流动和程序的执行流程。触发事件的条件和时机十分关键,它决定了程序将如何响应事件并继续执行。
例如,在一个主循环中,可能需要在特定条件下向子循环发送一个事件,子循环中的事件结构接收到该事件后执行相应的分支处理数据。事件的触发时机依赖于程序设计的需求,它可以是即时的,也可以是周期性的,或者是基于特定状态的。
3.2.2 循环间事件通信的设计技巧
循环间利用事件进行通信时,设计上需要注意避免死锁和确保事件的响应效率。一个设计良好的事件通信机制应该具备清晰的事件触发条件,且事件分支的处理逻辑应当尽量简短以避免阻塞事件队列。
在主循环与子循环之间的事件通信设计中,可以采用如下技巧:
- 确保事件处理逻辑尽量不涉及复杂的计算,尤其是避免在事件分支中再次进入循环结构。
- 使用标志位或者队列配合事件,实现对数据状态的非阻塞检查和处理。
- 在复杂的事件结构中,合理使用事件过滤器,避免不必要的事件分支被触发。
- 在可能的情况下,将事件处理逻辑抽取到单独的子VI中,以简化事件结构的内部逻辑,并提高代码的可维护性。
代码示例1:
// 主循环中的代码示例
While True
// 检查事件
Select Case Event Structure
Event Case [Some User Click]:
// 执行相应操作
Event Case [Data Ready Event from Sub Loop]:
// 处理来自子循环的数据
End Select
End While
代码逻辑分析:
上述代码展示了在主循环中使用事件结构的基本范式。这里使用了一个 While 循环作为主循环,内部有一个事件结构处理各种事件。当用户点击事件发生时,事件结构将进入对应的分支进行处理。另外,如果有一个事件表示子循环已经准备好数据,则主循环可以在这个分支中获取和处理数据。
通过这种结构,我们能够确保循环间的通信是通过事件来驱动的,而且保证了主循环可以按照特定的事件来响应和处理子循环的数据,实现有效的数据同步和任务协调。
在下文中,我们将进一步探讨队列结构在循环同步和数据传递中的应用,以及多循环性能优化和用户界面设计。
4. 队列结构同步与数据传递
4.1 队列结构的基本原理与应用
4.1.1 队列的数据结构特性
队列是一种先进先出(FIFO,First-In-First-Out)的数据结构,广泛应用于管理有序的元素集合。在编程和计算机科学中,队列作为数据结构可以处理同步和异步的任务队列,使得数据元素可以按照添加的顺序被访问。
队列的两个关键操作是“入队”(enqueue)和“出队”(dequeue)。入队操作把一个数据元素添加到队列的末尾,而出队操作则移除队列的第一个元素,并返回它。队列的这种特性确保了数据元素的访问顺序性和同步性,这在多循环同步和数据传递场景中尤为重要。
队列适用于多循环结构中,因为它们可以同步不同循环中的数据流。例如,在主循环和子循环之间,一个循环可以将数据项发送到队列中,而另一个循环可以从中提取数据项以进行处理。这种机制确保了循环间的通信不会发生冲突,并且可以根据元素到达的顺序来处理元素。
4.1.2 队列在循环同步中的作用
在多循环架构中,队列可以充当数据缓冲区的角色,允许数据在多个循环间流动,同时确保数据的有序性和同步性。队列结构在循环间同步中主要起以下作用:
- 数据缓冲: 队列作为缓冲区,可以吸收不同循环速率产生的数据流,平衡生产者和消费者之间的速度差异。
- 任务管理: 在多循环任务调度中,队列可以管理任务的执行顺序,确保按照特定顺序处理任务。
- 线程安全: 队列操作可以设计为线程安全的,这意味着多个循环(或线程)可以安全地访问队列,而不会导致数据不一致或竞争条件。
队列的一个重要优势是它能够简化多循环同步的复杂性。当循环间存在数据依赖关系时,队列提供了一种透明的方式来维持这种依赖关系,而不需要复杂的同步机制。
4.2 队列在数据传递中的应用实例
4.2.1 缓冲队列的设计与实现
缓冲队列是一种特殊的队列,它主要用于缓存两个或多个循环或线程间交换的数据项。设计缓冲队列时,需要考虑以下几个关键因素:
- 队列容量: 应确定队列的大小,以避免队列溢出或者资源浪费。容量的选择取决于数据项的大小、数据到达的速率和消费者处理数据的速度。
- 数据类型: 队列可以存储任意类型的数据项,因此需要明确队列中将存储哪些类型的数据。
- 线程安全: 如果队列将在多线程环境中使用,实现线程安全的队列至关重要,以避免数据竞争和条件竞争。
例如,在LabVIEW中,可以使用队列函数来创建缓冲队列。可以利用队列初始化函数来定义队列的大小和类型,然后使用入队和出队函数来管理数据。
Queue Create Queue (Size as U32, Element as Type)
4.2.2 队列与循环数据同步的优化策略
优化队列和循环数据同步的关键在于调整队列的大小,以及合理安排生产者和消费者的处理速率。以下是一些优化策略:
- 动态调整队列大小: 根据运行时数据流的实际情况动态调整队列大小,可以在不丢失数据的情况下最小化资源使用。
- 优先级队列: 如果循环处理数据的优先级不同,使用优先级队列可以确保高优先级的数据项先被处理。
- 监控队列状态: 实时监控队列的状态,如长度和是否满等,可以有效防止数据丢失和性能瓶颈。
利用LabVIEW中的事件结构,可以实现对队列状态变化的响应。例如,可以创建一个事件来监控队列的“队列非空”事件,并据此触发相应的循环处理过程。
Event Structure
- Queue Not Empty Event
--> Code Block for Processing Data from Queue
队列结构在LabVIEW多循环架构中的应用,展示了如何有效地同步多个循环间的数据流,同时保持数据流的有序性和可预测性。通过合理地设计和实现队列,可以实现多循环系统的高效和稳定运行。
5. 多循环性能优化策略
在LabVIEW的多循环架构中,性能优化是一项关键任务,尤其是在复杂或实时性要求高的应用中。优化的目的在于提高应用程序的执行效率,减少资源消耗,并确保系统的稳定性和响应性。本章将探讨多循环性能优化的策略和实践。
5.1 多循环性能瓶颈的分析
5.1.1 循环结构对性能的影响
在多循环架构中,循环结构是性能瓶颈的常见来源。主循环控制整个程序的流程,而子循环负责特定任务的执行。如果设计不当,它们可能会导致程序运行缓慢,甚至造成资源耗尽。
例子:
// 伪代码展示循环结构
for main_loop {
for sub_loop {
// 执行特定任务
}
// 检查条件,决定是否继续
}
在上面的伪代码示例中,如果子循环中的任务处理速度无法跟上主循环的频率,那么子循环就会成为瓶颈。
5.1.2 常见性能瓶颈的识别与诊断
识别性能瓶颈的常用方法包括代码剖析(profiling)、资源监视器的使用、以及日志记录。代码剖析工具能够提供程序运行时的时间消耗分析,帮助开发者了解哪些函数或循环执行得最慢。
代码剖析工具输出示例:
Function Name | Calls | Self Time | Total Time
Main Loop | 1000 | 25ms | 500ms
Sub Loop | 20000 | 10ms | 480ms
Other Functions | 5000 | 5ms | 100ms
通过剖析数据,可以发现Sub Loop虽然调用次数最多,但Self Time(自身执行时间)相对较短,而Total Time(总执行时间)却很长,这表明瓶颈可能在于Sub Loop和其他函数的交互过程。
5.2 多循环优化技巧与案例分析
5.2.1 循环优化的基本原则
循环优化的基本原则包括减少循环次数、简化循环内的计算、使用高效的循环结构和数据结构、以及避免不必要的循环依赖。
循环优化操作示例:
// 优化前
for i from 1 to 1000 {
// 计算密集型任务
}
// 优化后
for i from 1 to 100 by 2 {
// 等效计算任务,减少循环次数
}
在优化后,通过调整循环增量,我们将执行次数从1000次减少到了500次,节省了执行时间。
5.2.2 实际应用中的优化案例
实际应用中的优化案例通常涉及对特定算法的调整。以数组元素求和为例,优化前可能采用简单的循环,优化后可以考虑使用向量化操作或其他内置函数来减少计算时间。
优化前后代码对比:
// 优化前
sum = 0
for i from 1 to length(array) {
sum += array[i]
}
// 优化后
sum = sumOfArray(array)
在优化后使用了 sumOfArray 这一内置函数,它能够更高效地完成同样的任务,从而提高了性能。
接下来的章节,我们将探讨如何在LabVIEW中设计高效的用户界面,并确保其与多循环架构的平滑交互。
简介:LabVIEW是一种图形编程环境,其中多循环应用程序架构常用于实现复杂系统或多任务并行处理。该DEMO示例演示了如何利用LabVIEW的多循环特性构建高效和可扩展的应用程序。介绍了主循环与子循环的结构、事件和队列结构在循环间通信的作用,以及同步、性能优化和用户界面设计的最佳实践。通过此DEMO,开发者可以学习如何在LabVIEW中设计模块化的多循环应用程序,以应对实时系统和大数据分析的挑战。

















 419
419

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









