







 本文深入解析Python Numpy库中的关键函数,如shape、tile、sum、argsort及内置函数range和字典方法get。详细介绍了各函数的参数、返回值及应用场景,帮助读者掌握Numpy高效数据处理技巧。
本文深入解析Python Numpy库中的关键函数,如shape、tile、sum、argsort及内置函数range和字典方法get。详细介绍了各函数的参数、返回值及应用场景,帮助读者掌握Numpy高效数据处理技巧。
dataSetSize = dataSet.shape[0]1.python Numpy的shape
shape函数是numpy.core.fromnumeric中的函数,它的功能是读取矩阵的长度,比如shape[0]就是读取矩阵第一维度的长度。它的输入参数可以是一个整数表示维度,也可以是一个矩阵。
- 如果输入参数是一维矩阵,则返回1个数
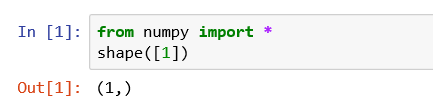
- 如果输入参数是二维矩阵,则返回2个数
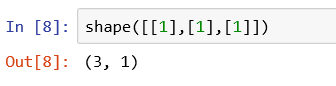
- 如果输入参数是多维矩阵,则返回多个数

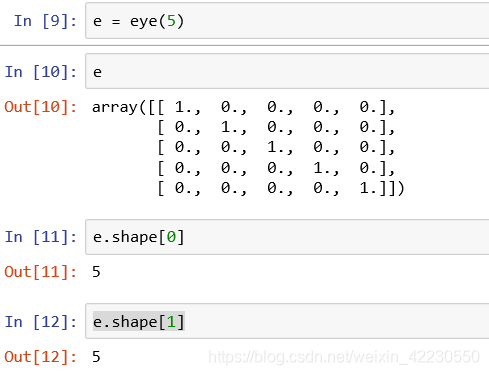
- shape也可以看作是矩阵的一个属性,可以用“ . ”来调用shape[i],( 读取第 i+1 维的矩阵长度)
diffMat = tile(inX, (dataSetSize, 1)) - dataSet2.python Numpy的tile
-
numpy.tile(A,reps):通过重复A重复给出的次数来构造数组。
-
A的类型众多,几乎所有类型都可以:array, list, tuple, dict, matrix以及基本数据类型int, string, float以及bool类型。
-
reps的类型也很多,可以是tuple,list, dict, array, int, bool.但不可以是float, string, matrix类型。
|
|
|---|---|
|
|
- eg:

sqDistances = sqDiffMat.sum(axis=1)3.python Numpy的sum
- 定义:numpy.sum(a, axis=None, dtype=None, out=None, keepdims=<class numpy._globals._NoValue>):给定轴上的数组元素的总和。
-
参数: a:array_like
总和的要素。
axis:无或 int 或 int 的元组,可选
沿轴或轴执行求和的轴。默认值axis = None将汇总输入数组的所有元素。如果轴为负,则从最后一个轴到第一个轴计数。
版本1.7.0中的新功能。
如果axis是int的元组,则对元组中指定的所有轴执行求和,而不是像以前那样对单个轴或所有轴执行求和。
dtype:dtype,可选
返回数组的类型以及元素求和的累加器的类型。的D型细胞一个默认使用,除非一个 具有比缺省平台整数精度以下的整数D型。在这种情况下,如果a是有符号的,则使用平台整数,而如果a是无符号的,则使用与平台整数具有相同精度的无符号整数。
out:ndarray,可选
替代输出数组,用于放置结果。它必须与预期输出具有相同的形状,但必要时将输出输出值的类型。
keepdims:bool,可选
如果将其设置为True,则缩小的轴将作为尺寸为1的尺寸保留在结果中。使用此选项,结果将针对输入数组正确广播。
如果传递了默认值,那么keepdims将不会传递给
sum子类的方法ndarray,但是任何非默认值都将是。如果子类sum方法没有实现keepdims,则会引发任何异常。返回: sum_along_axis:ndarray
与a相同形状的数组,删除指定的轴。如果a是0-d数组,或者如果axis是None,则返回标量。如果指定了输出数组,则返回对out的引用 。
- eg:

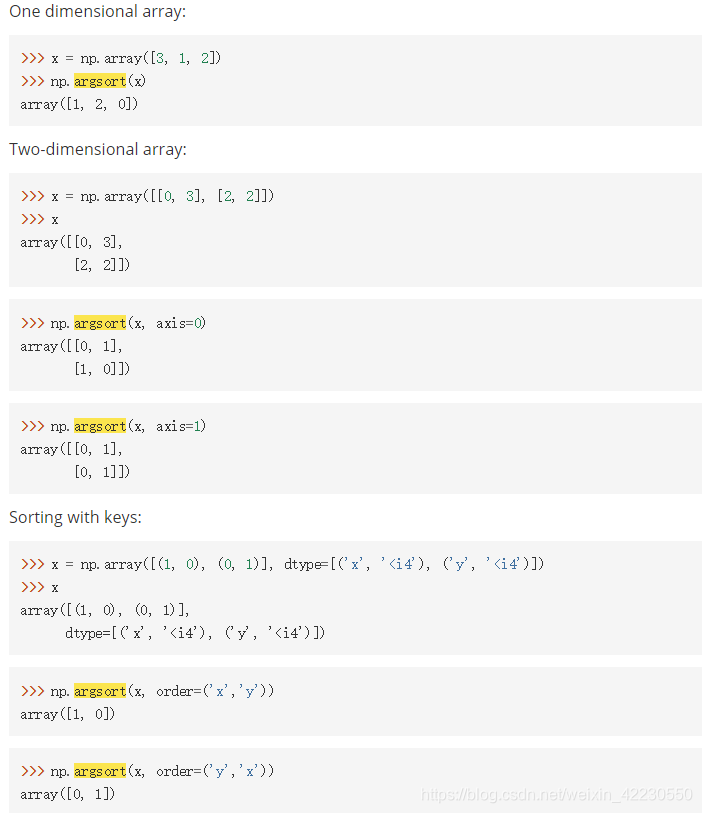
sortedDistIndicies = distances.argsort()4.python Numpy的argsort
- 定义:numpy.argsort(a, axis=-1, kind='quicksort', order=None):返回对数组进行排序的索引。
使用kind关键字指定的算法沿给定轴执行间接排序。它返回相同的形状的索引数组 一个沿着以排序的顺序给定的轴线索引数据。 -
参数: a:array_like
要排序的数组。
axis:int或None,可选
Axis沿着它排序。默认值为-1(最后一个轴)。如果为None,则使用扁平化阵列。
kind:{'quicksort','mergesort','heapsort'},可选
排序算法。
order:str或str的列表,可选
当a是一个定义了字段的数组时,此参数指定要比较哪些字段的第一个,第二个等。可以将单个字段指定为字符串,并且不需要指定所有字段,但仍将使用未指定的字段,他们在dtype中出现的顺序,以打破关系。
返回: index_array:ndarray,int
索引的阵列那种一个沿指定轴线。如果a是一维的,则
a[index_array]产生一个排序的a。 - eg:
for i in range(k):5.python 内置函数的range
- 定义:
range(start, stop[, step]) python range() 函数可创建一个整数列表,一般用在 for 循环中。
- 参数说明:
start: 计数从 start 开始。默认是从 0 开始。例如range(5)等价于range(0, 5);
stop: 计数到 stop 结束,但不包括 stop。例如:range(0, 5) 是[0, 1, 2, 3, 4]没有5
step:步长,默认为1。例如:range(0, 5) 等价于 range(0, 5, 1)
- eg:

classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 16.python 字典(dictionary)get()方法
- 语法:返回指定键的值,如果值不在字典中返回默认值。
dict.get(key, default=None)
- 参数
- key -- 字典中要查找的键。
- default -- 如果指定键的值不存在时,返回该默认值值。
- eg:
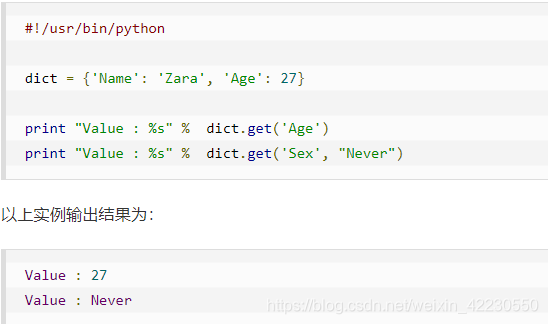
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)# 字典的 items() 方法,以列表返回可遍历的(键,值)元组数组。
# 例如:dict = {'Name': 'Zara', 'Age': 7} print "Value : %s" % dict.items() Value : [('Age', 7), ('Name', 'Zara')]
# sorted 中的第2个参数 key=operator.itemgetter(1) 这个参数的意思是先比较第几个元素
# 例如:a=[('b',2),('a',1),('c',0)]#b=sorted(a,key=operator.itemgetter(1)) >>>b=[('c',0),('a',1),('b',2)] 可以看到排序是按照后边的0,1,2进行排序的,而不 是a,b,c
# b=sorted(a,key=operator.itemgetter(0)) >>>b=[('a',1),('b',2),('c',0)] 这次比较的是前边的a,b,c而不是0,1,2
# b=sorted(a,key=opertator.itemgetter(1,0)) >>>b=[('c',0),('a',1),('b',2)] 这个是先比较第2个元素,然后对第一个元素进行 排序,形成多级排序。
7.python 内置函数的sorted()
- 语法:
sorted(iterable,*,key = None,reverse = False )
- 参数说明
- iterable -- 可迭代对象。
- cmp -- 比较的函数,这个具有两个参数,参数的值都是从可迭代对象中取出,此函数必须遵守的规则为,大于则返回1,小于则返回-1,等于则返回0。
- key -- 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。
- reverse -- 排序规则,reverse = True 降序 , reverse = False 升序(默认)。
- eg:


















 1010
1010

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









