










 本文详细介绍如何使用 Spark Streaming 处理实时数据流,包括基本的单词计数、数据累加、开窗函数应用以及热词统计。通过具体示例,演示如何配置 Spark 环境,实现数据接收、处理及输出。
本文详细介绍如何使用 Spark Streaming 处理实时数据流,包括基本的单词计数、数据累加、开窗函数应用以及热词统计。通过具体示例,演示如何配置 Spark 环境,实现数据接收、处理及输出。
这次我们演示使用使用SparkStreaming对不同数据流读取的简单操作,以单词统计为例
- 接受socket数据,实现单词计数和实现累加
- 使用开窗函数统计时间段内的热词语
1. 实现单词计数WordCount
1. 1架构
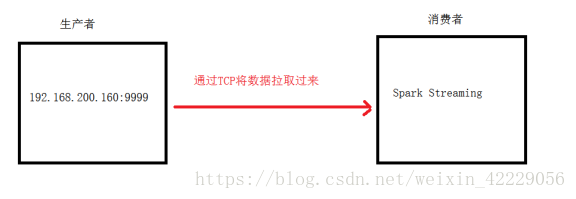
1.2 实现流程
(1)安装并启动生产者
首先在linux服务器上用YUM安装nc工具,nc命令是netcat命令的简称,它是用来设置路由器。我们可以利用它向某个端口发送数据。
yum install -y nc
(2)通过netcat工具向指定的端口发送数据
nc -lk 9999
1.3 编写代码
import org.apache.hadoop.hive.ql.parse.spark.SparkCompiler
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
//
object SparkStreamingTCP {
def main(args: Array[String]): Unit = {
//1.构建saprkConf参数
val sparkConf:SparkConf =
new SparkConf().setAppName("SparkStreamingTCP").setMaster("local[2]")
//2. 构建sparkContext对象
val sc : SparkContext = new SparkContext(sparkConf)
sc.setLogLevel("WARN")
//3. 构建StreamingContxt对象,批处理间隔时间
val ssc : StreamingContext = new StreamingContext(sc,Seconds(5))
//4. 注册一个监听的Ip和端口,用来采集数据
val lines: ReceiverInputDStream[String] = ssc.socketTextStream("192.168.25.101",9999)
//5. 做单词统计的逻辑
val words : DStream[String] = lines.flatMap(_.split(" "))
val wordAndOne : DStream[(String,Int)] = words.map((_,1))
val result :DStream[(String,Int)] = wordAndOne.reduceByKey(_+_)
//6. 打印结果
result.print()
//7. 开启服务
ssc.start()
ssc.awaitTermination()
}
}
由于使用的是本地模式"local[2]"所以可以直接在本地运行该程序
注意:要指定并行度,如在本地运行设置setMaster(“local[2]”),相当于启动两个线程,一个给receiver,一个给computer。如果是在集群中运行,必须要求集群中可用core数大于1。
1.4 执行结果
- 先在linux输入命令
nc -lk 9999 - 运行代码
- 在linux输入需要统计的单词
- 观察控制台的输出
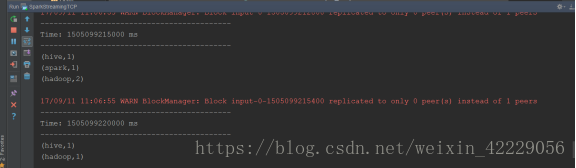
ps出现的结果没有进行累加
2. 单词统计的累加
其他命令和上面的相同,代码做一些的改写
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
object SparkStreamingTCPTotal {
//对结果进行累加的函数
//newValues 表示当前批次汇总成的(word,1)中相同单词的所有的1
//runningCount 历史的所有相同key的value总和
def updateFunc(newValues:Seq[Int] , runningCount:Option[Int]):Option[Int] = {
val newCount = newValues.sum+runningCount.getOrElse(0)
Some(newCount)
}
def main(args: Array[String]): Unit = {
//1.构建saprkConf参数
val sparkConf:SparkConf =
new SparkConf().setAppName("SparkStreamingTCP").setMaster("local[2]")
//2. 构建sparkContext对象
val sc : SparkContext = new SparkContext(sparkConf)
sc.setLogLevel("WARN")
//3. 构建StreamingContxt对象,批处理间隔时间
val ssc : StreamingContext = new StreamingContext(sc,Seconds(5))
ssc.checkpoint("./ck")
//4. 注册一个监听的Ip和端口,用来采集数据
val lines: ReceiverInputDStream[String] = ssc.socketTextStream("192.168.25.101",9999)
//5. 做单词统计的逻辑
val words : DStream[String] = lines.flatMap(_.split(" "))
val wordAndOne : DStream[(String,Int)] = words.map((_,1))
//val result :DStream[(String,Int)] = wordAndOne.reduceByKey(_+_)
//累加结果
val result :DStream[(String,Int)] = wordAndOne.updateStateByKey(updateFunc)
//6. 打印结果
result.print()
//7. 开启服务
ssc.start()
ssc.awaitTermination()
}
}
执行结果
按照上面的代码执行后,我们输入的单词,每隔5S,会进行一次单词的统计,已经可以进行累加了
3. 开窗函数ReduceByKeyAndWindow的实现
实现的步骤和前面的例子相同,代码需要重新改写
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
/**
* sparkStreming开窗函数---统计一定时间内单词出现的次数
*/
object SparkStreamingTCPWindow {
def main(args: Array[String]): Unit = {
//配置sparkConf参数
val sparkConf: SparkConf = new SparkConf().setAppName("SparkStreamingTCPWindow").setMaster("local[2]")
//构建sparkContext对象
val sc: SparkContext = new SparkContext(sparkConf)
sc.setLogLevel("WARN")
//构建StreamingContext对象,每个批处理的时间间隔
val scc: StreamingContext = new StreamingContext(sc,Seconds(5))
//注册一个监听的IP地址和端口 用来收集数据
val lines: ReceiverInputDStream[String] = scc.socketTextStream("192.168.25.101",9999)
//切分每一行记录
val words: DStream[String] = lines.flatMap(_.split(" "))
//每个单词记为1
val wordAndOne: DStream[(String, Int)] = words.map((_,1))
//reduceByKeyAndWindow函数参数意义:
// windowDuration:表示window框住的时间长度,如本例5秒切分一次RDD,框10秒,就会保留最近2次切分的RDD
//slideDuration: 表示window滑动的时间长度,即每隔多久执行本计算
val result: DStream[(String, Int)] = wordAndOne.reduceByKeyAndWindow((a:Int,b:Int)=>a+b,Seconds(10),Seconds(5))
result.print()
scc.start()
scc.awaitTermination()
}
}
输出结果
开窗函数有两个重要的参数,开窗的时间和移动的时间,要求开窗的时间是移动时间的整数被,数据才不会丢失问题,具体的参数在代码中体现。
具体的现象是:sparkStreaming每隔5s计算一次当前在窗口大小为10s内的数据,然后将结果数据输出。
4. 开窗函数计算某时间段的热词
代码改写
统计某时间排名前三的热词
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
/**
* sparkStreming开窗函数应用----统计一定时间内的热门词汇
*/
object SparkStreamingTCPWindowHotWords {
def main(args: Array[String]): Unit = {
//配置sparkConf参数
val sparkConf: SparkConf = new SparkConf().setAppName("SparkStreamingTCPWindowHotWords").setMaster("local[2]")
//构建sparkContext对象
val sc: SparkContext = new SparkContext(sparkConf)
sc.setLogLevel("WARN")
//构建StreamingContext对象,每个批处理的时间间隔
val scc: StreamingContext = new StreamingContext(sc,Seconds(5))
//注册一个监听的IP地址和端口 用来收集数据
val lines: ReceiverInputDStream[String] = scc.socketTextStream("192.168.25.101",9999)
//切分每一行记录
val words: DStream[String] = lines.flatMap(_.split(" "))
//每个单词记为1
val wordAndOne: DStream[(String, Int)] = words.map((_,1))
//reduceByKeyAndWindow函数参数意义:
// windowDuration:表示window框住的时间长度,如本例5秒切分一次RDD,框10秒,就会保留最近2次切分的RDD
//slideDuration: 表示window滑动的时间长度,即每隔多久执行本计算
val result: DStream[(String, Int)] = wordAndOne.reduceByKeyAndWindow((a:Int,b:Int)=>a+b,Seconds(10),Seconds(5))
val data=result.transform(rdd=>{
//降序处理后,取前3位
val dataRDD: RDD[(String, Int)] = rdd.sortBy(t=>t._2,false)
val sortResult: Array[(String, Int)] = dataRDD.take(3)
println("--------------print top 3 begin--------------")
sortResult.foreach(println)
println("--------------print top 3 end--------------")
dataRDD
})
scc.start()
scc.awaitTermination()
}
}
输出结果
sparkStreaming每隔5s计算一次当前在窗口大小为10s内的数据,然后将单词出现次数最多的前3位进行输出打印。

















 502
502

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









