







一个公司给的面试题,300特征预测Label的值,特征没有给任何具体的含义,label也没给
part 1 包的导入数据读入
`# -*- coding: utf-8 -*-
import pandas as pd
import numpy as np
import lightgbm as lgb
from sklearn.model_selection import KFold
from sklearn.metrics import r2_score
from sklearn.feature_selection import RFE
from sklearn.preprocessing import StandardScaler
from sklearn import preprocessing
from scipy import stats,special
from sklearn.ensemble import GradientBoostingRegressor
import math
from sklearn.linear_model import LinearRegression
data=pd.read_csv('data.csv',header=0)`part 2 数据清洗数据
1.原始数据存在大量的nan值(稍后处理)
2.存在’-’和”N”形式的数据,(转为nan,统一处理)
3.存在如”250,000+”用字符串表示的数据(转为float)
4.存在异常数据,如均值为200,却存在50000+的数(将大于列均值15倍的数转换为均值的15倍)
5.根据观察得,’f2’可能是一个分类变量,groupby(f2)进行分组均值填充nan值
def clean(x): #将-,n转换成nan值
if x=='-' or x=='N':
x=data['f16'][0]
return x
def str_float(x):
ss=x.split(',')
if ss[1][-1]=='-':
x=float(ss[0]+ss[1][:-1])*(-1)
else:
x=float(ss[0]+ss[1][:-1])
return x
def data_type(x): #将25,000+字符串数据转换成数值`
type(x)!=type(data.iloc[0][4])
try:
x=float(x)
except:
x=str_float(x)
return x
for name in data.columns:
data[name]=data[name].apply(lambda x: clean(x))
data[name]=data[name].apply(lambda x: data_type(x)) #
def abnormal_value(data_col): #异常值处理
data_max=15*np.mean(data_col) #大于均值15倍数据视为异常值
for i in range(len(data_col)):
if (data_col[i]>data_max):
data_col[i]=data_max
return data_col
for name in data.columns:
data[name]=abnormal_value(data[name])
#Nan值填充,按'f2'分组填充均值
def nan_fill(data_col,col_name):
group_mean=data.groupby('f2', as_index = False)[col_name].mean()
group_mean= dict(zip( group_mean['f2'], group_mean[col_name]))
for i in range(len(data_col)):
if not data_col[i]>-50:
data_col[i]= group_mean[data['f2'][i]]
return data_col
for name in data.columns:
if data[name].isnull().sum()>0:
data[name]=nan_fill(data[name],name)
data=data.fillna(method='backfill')
data_2=data
#零值替换成0.001,因为后面box-cox转换需求
for i in range(len(data)):
for j in range(301):
if data.iloc[i][j]==0:
data.iloc[i][j]=0.001part3 进一步数据观察与处理
1.检测数据是否服从正态分布(不服从)
2.检测各组数据与Label是否存在相关性(相关性低) 因为做回归,若原始数据服从正态分布,有利于回归准确性计算,在尝试使用log, √等数据平滑处理后,效果有所提升,但不理想,最后使用box-cox算法来处理数据。将处理过后,能尽量使数据服从正态分布。
#是否服从正态分布,——不服从正态分布
def u_check(data_col):
u = data_col.mean() # 计算均值
std =data_col.std() # 计算标准差
a= stats.kstest(data_col, 'norm', (u, std)) #D ,p
return a[1]
u_list=[] #不服从
for i in data.columns:
u_list.append(u_check(data[i]))
#是否和label存在线性关系——>不存在线性关系,不存在直接的因果关系
def p_check(dat):
return stats.pearsonr(dat,data['Label'])[0]
p_list=[] #基本不存在
for i in data.columns:
p_list.append(p_check(data[i]))
#box-cox转变
def box_cox(data_col):#将数据正态化
y = np.array(data_col)
lam_range = np.linspace(-2,5,100) # default nums=50
llf = np.zeros(lam_range.shape, dtype=float)
for i,lam in enumerate(lam_range):
llf[i] = stats.boxcox_llf(lam, y) # y 必须>0
lam_best = lam_range[llf.argmax()]
y_boxcox = special.boxcox1p(y, lam_best)
y_boxcox=pd.Series(y_boxcox)
return y_boxcox
for name in data.columns:
data[name]=box_cox(data[name])part4 回归特征消除(REF)
写了一个关于REF的函数,输入参数n就返回n个最适合的特征的名称+Label,理论和实践上来说,基特征选择器,用GradientBoostingRegressor()是更好的,但是特征筛选的速度太慢了,还是用了最快的LinearRegression()。 #lr =GradientBoostingRegressor(n_estimators=100, learning_rate=0.1,max_depth=1, random_state=0, loss='ls') lr = LinearRegression()
colName=list(data.columns[:300])
def refSelect(n):
data_X= np.array(data)
rfe = RFE(estimator=lr, n_features_to_select=n)
rfe.fit(data_X[:,:-1],data_X[:,-1])
feature=rfe.support_
col=[]
for i in range(len(feature)):
if feature[i]:
col.append(colName[i])
col.append('Label')
return colpart5 gbm模型预测 ##
因为不知道数据间和label的关系,相关性检测也相对较低,故应该用非线性的回归模型。选择了基于树的回归模型,用的是lightgbm框架。并且自己定义了一个R2_score=1-r2_score评价函数。 作为训练模型的评价函数。 gbm = lgb.LGBMRegressor(num_leaves=32, learning_rate=0.1, n_estimators=1000, )
#自定义评价函数 R2_score=1-r2_score
def R2_score(y_true, y_pred):
ssTot=sum(np.power((y_true-np.mean(y_true)),2))
ssRes=sum(np.power((y_pred -y_true),2))
r2=ssRes/ssTot
return 'R2_score', r2, False
kfold = KFold(n_splits=3, shuffle = False, random_state= 1)#三折交叉检验
r2_scores=[] #用来存储预测结果
for i in np.arange(1,301,1):
col=refSelect(i)
data_XX= np.array(data[col])
scores=[]
for train, test in kfold.split(data_XX):
data_train,data_test=(data_XX[train], data_XX[test])
X_train, y_train=np.array(data_train[:,:-1]),data_train[:,-1]
X_test, y_test=np.array(data_test[:,:-1]),data_test[:,-1]
gbm.fit(X_train, y_train,
eval_set=[(X_test, y_test)],
eval_metric=R2_score,
verbose=200,
early_stopping_rounds=50)
y_pred = gbm.predict(X_test, num_iteration=gbm.best_iteration_)
score=r2_score(y_test, y_pred)
scores.append(score)
r2_scores.append(np.mean(scores)) #将三折均值纳入r2_score中来
r2_scores_csv=pd.DataFrame(r2_scores,columns=['score'])
r2_scores_csv.to_csv("r2_score.csv")part6 可视化
当特征数量达到50左右就稳定了,不再波动了,稳定在0.6左右的r2值
import matplotlib.pyplot as plt
plt_x=range(1,len(r2_scores)+1)
plt_y=r2_scores
plt.plot(plt_x, plt_y)
plt.show()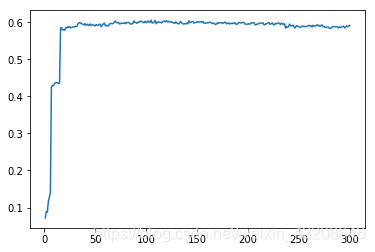
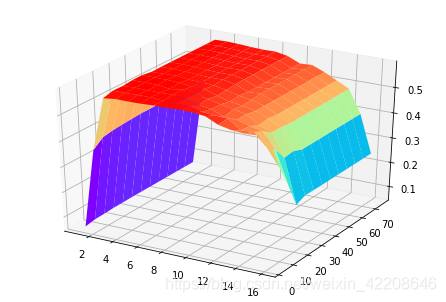
part7 三维调参图
选择学习率和叶子数进行调参 理论上来说,叶子数量太少,欠拟合,过多容易过拟合。最好等于2^max_depth,最大树深最为合适。学习率太低容易陷在局部最优点,过高容易跳过全局具优点。
叶子的取值范围为 X=np.arange(3,80,6) 学习率的取值需要灵活选择。 Y=array([1.00000000e-04, 1.00000000e-03, 6.49801917e-03, 1.94190235e-02, 4.22242531e-02, 7.71292328e-02, 1.26185187e-01, 1.91321910e-01, 2.74374006e-01, 3.77098474e-01, 5.01187234e-01, 6.48276457e-01, 8.19953765e-01, 1.01776392e+00, 1.24321344e+00, 1.49777439e+00])
结果表明学习效果基本不受叶子数量的影响(叶子数调节到20000,也基本无影响,),学习效果很容易受到学习率的影响。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









