







此笔记来源于李宏毅老师的机器学习视频,以下属于自己的理解以及老师上课的内容,由于公式过多,不便于直接打字,故用手写笔记替代。
Github的链接(pdf):https://github.com/Bessie-Lee/Deep-Learning-Recodes-LiHongyi
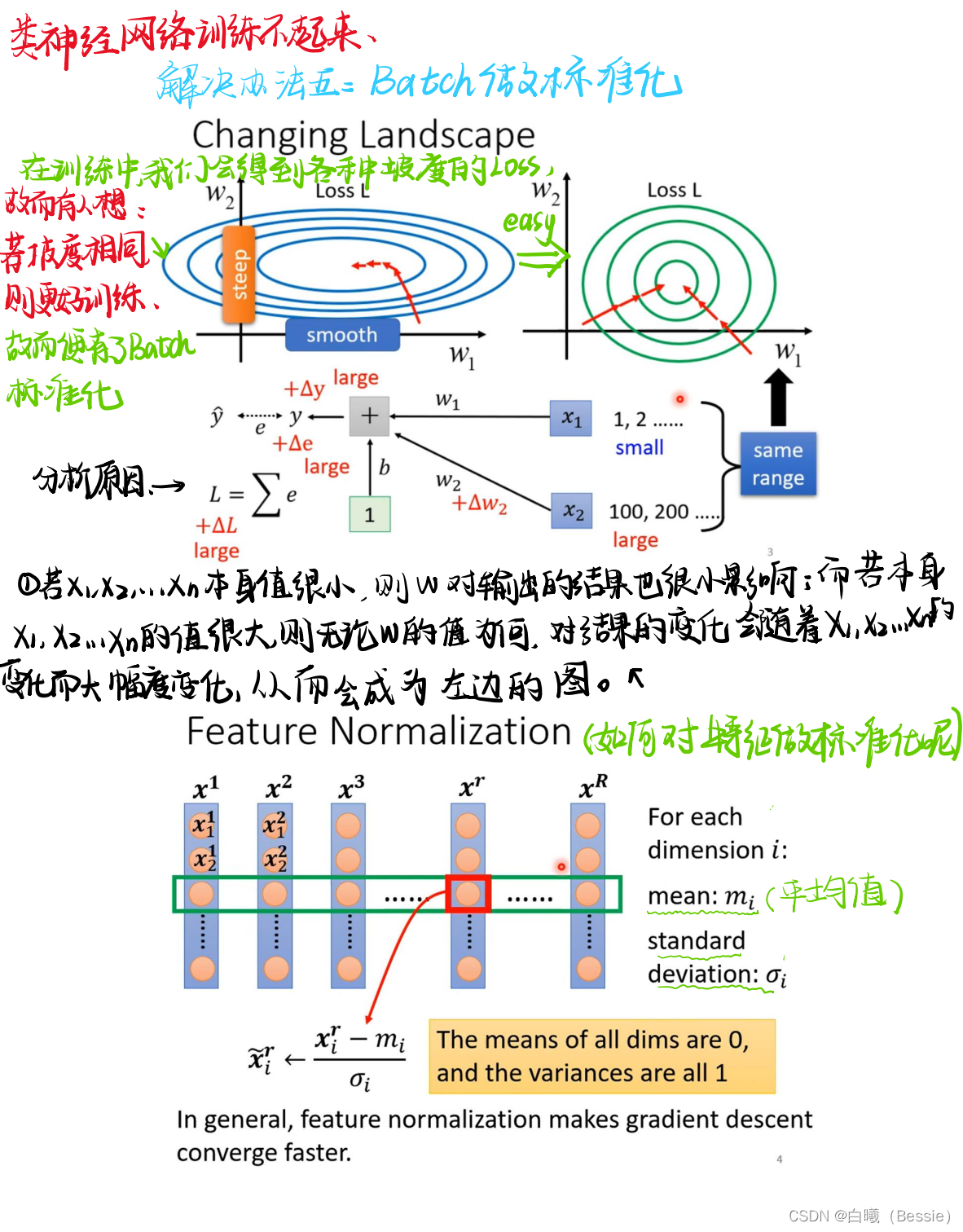
类神经网络训练不起来,解决办法五
在计算梯度的时候,遇到各种崎岖陡峭的梯度,使得训练无法再进行下去或者在一个范围波动,此时科学家们想到愚公移山,要不直接把崎岖的地方给铲平,变成一个平地或者一个斜坡,这样子避免了陡峭,故而从源头上对数据进行了处理。
处理的方式就是我们常见的正则化(归一化),将输入的参数归一化为一个-1-1区间范围内的值,这样子确保加入参数weight和bais时,不会出现梯度时大时小的现象,从而更好的使梯度下降到minima的位置。
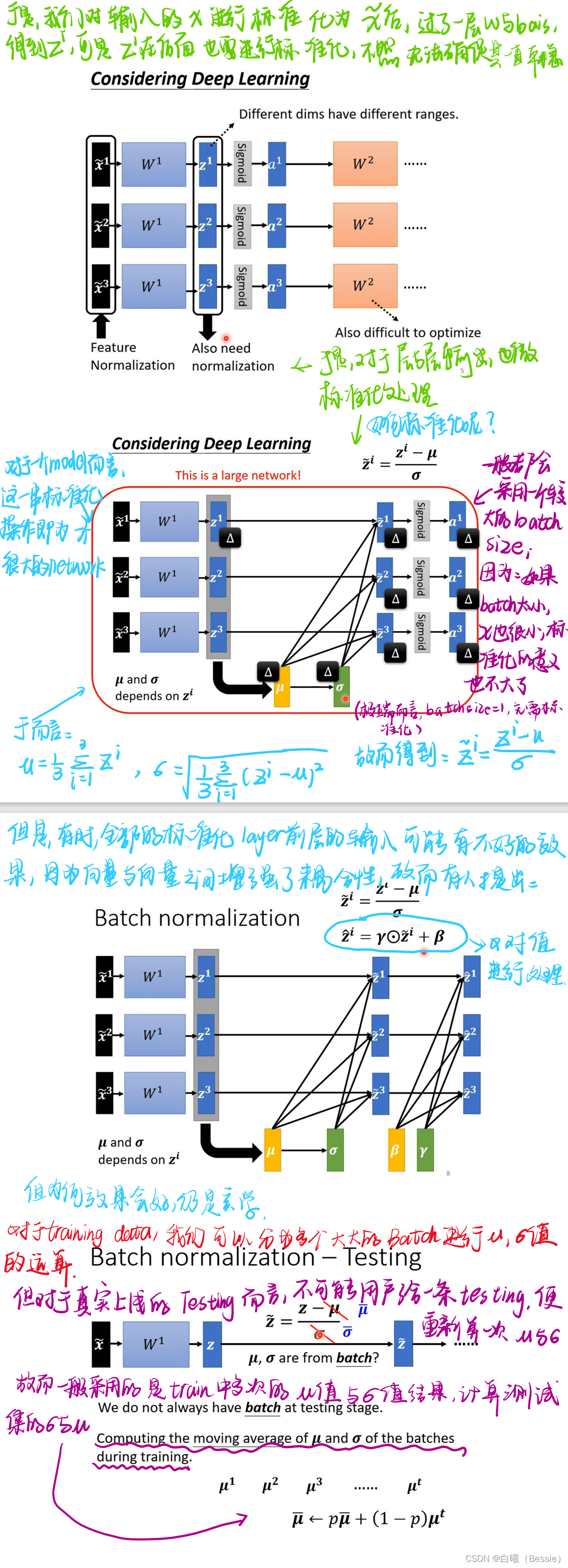
但是常见的神经网络都不止一层,对于多层的神经网络而言,如果只是对输入的input向量进行正则化,后面经过权重变化得到的新的参数将也会面临崎岖的现象,故而会对后面的输出结果进行再次标准化,可是过度的标准化也会导致向量之间的耦合度过高,从而影响最终的output,所以我们需要适当的进行标准化(此步骤可以简称:玄学调参)
[注:一般我们采用的batch尽量大一点,因为小的batch标准化没有什么意义(例如对一个只有1batch的进行标准化,无论是否标准化的结果都是他本身的值,数量过小标准化的意义便不大,反而会导致结果的输出不准确)]
其他类神经网络训练不起来的原因以及解决办法见之前博客:[李宏毅老师深度学习视频] 类神经网络训练不起来的四大原因 【手写笔记】
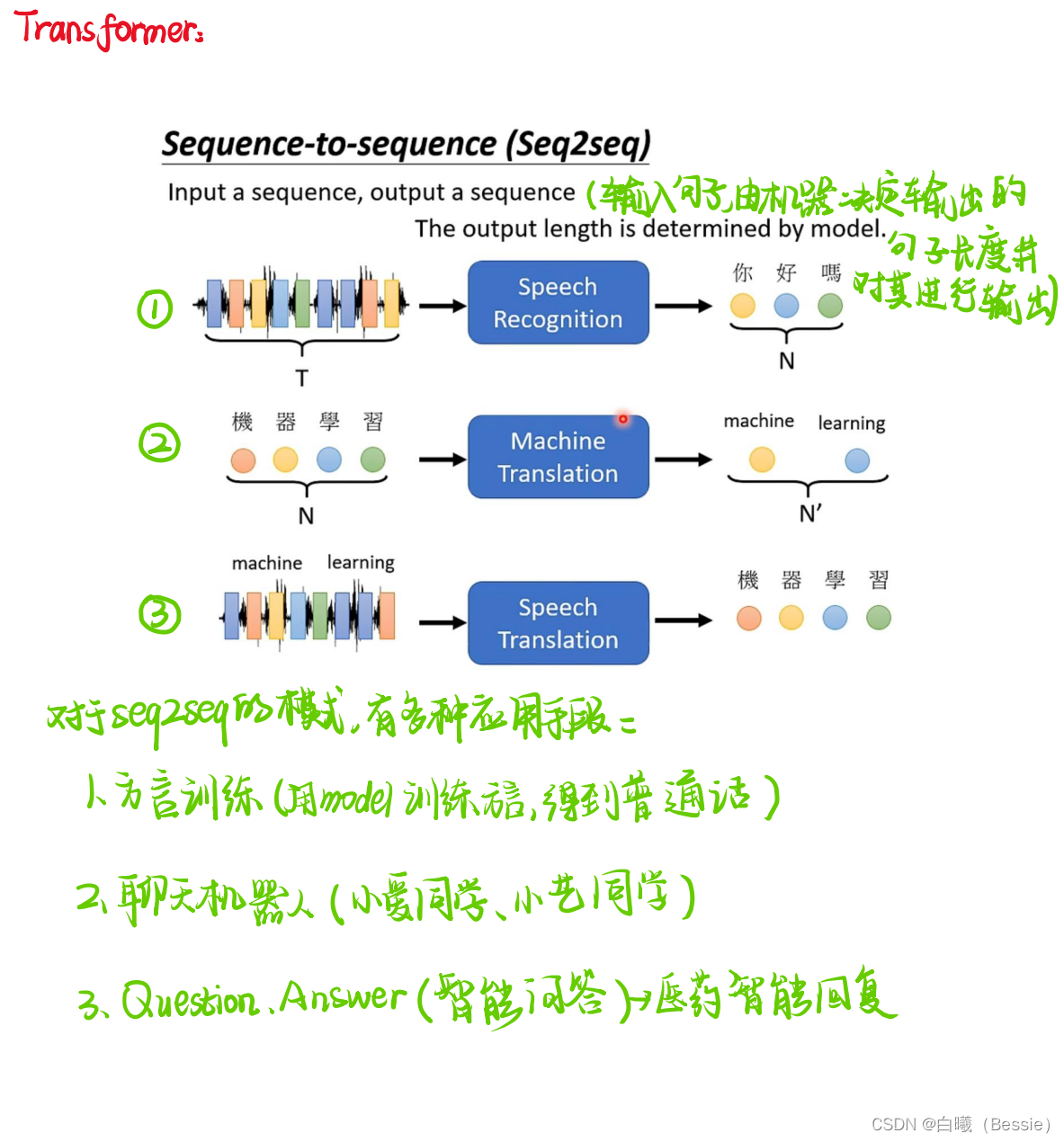
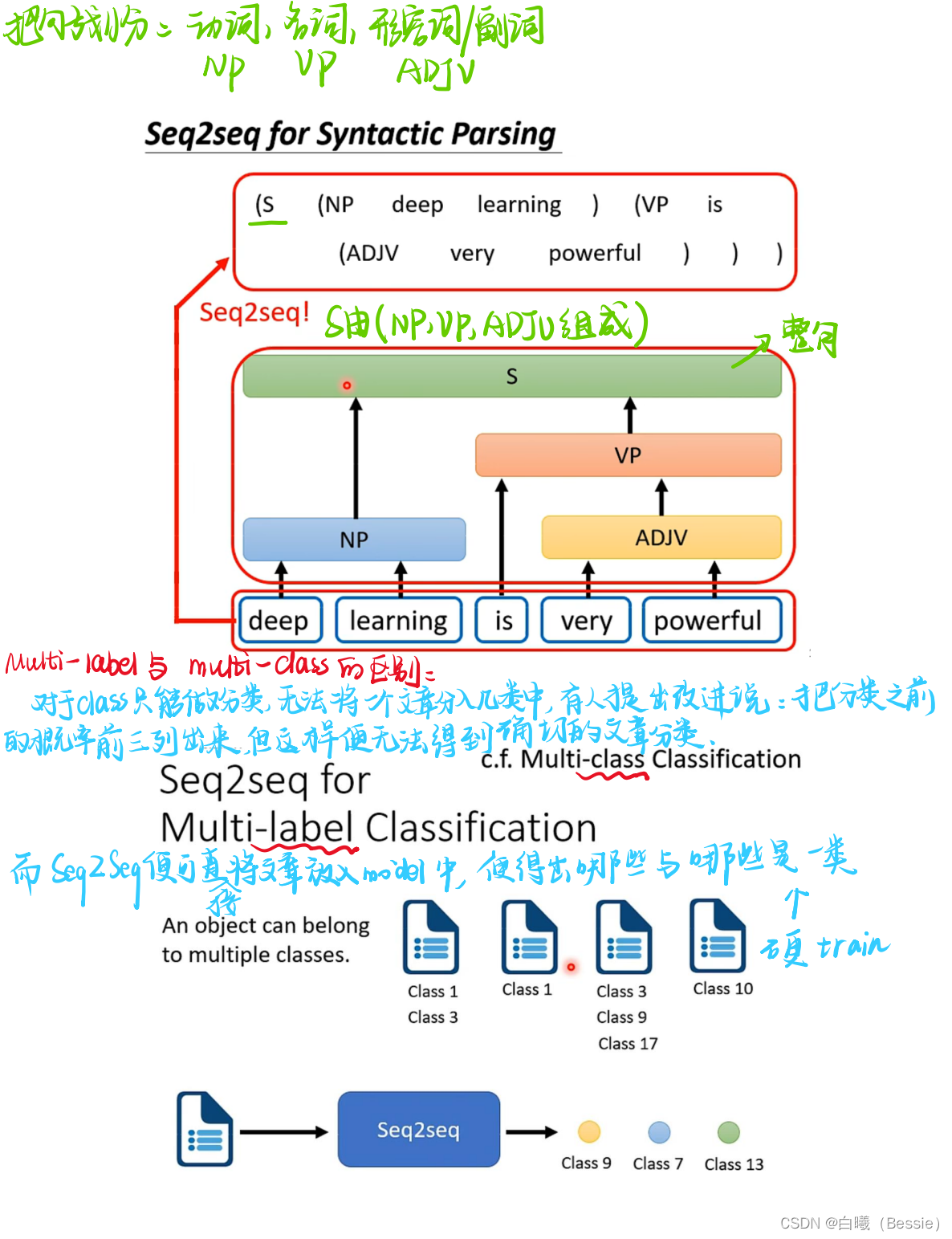
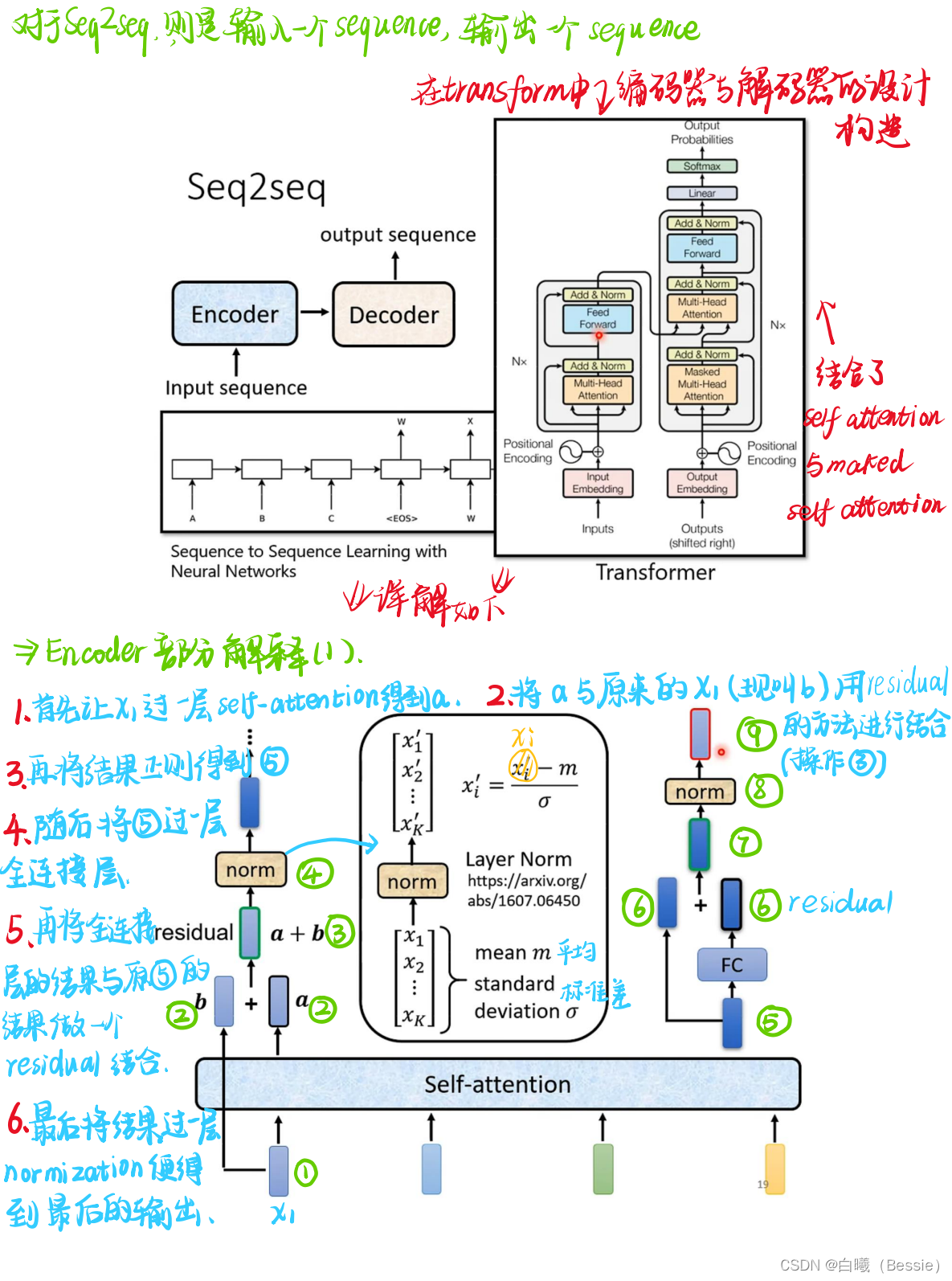
transformer
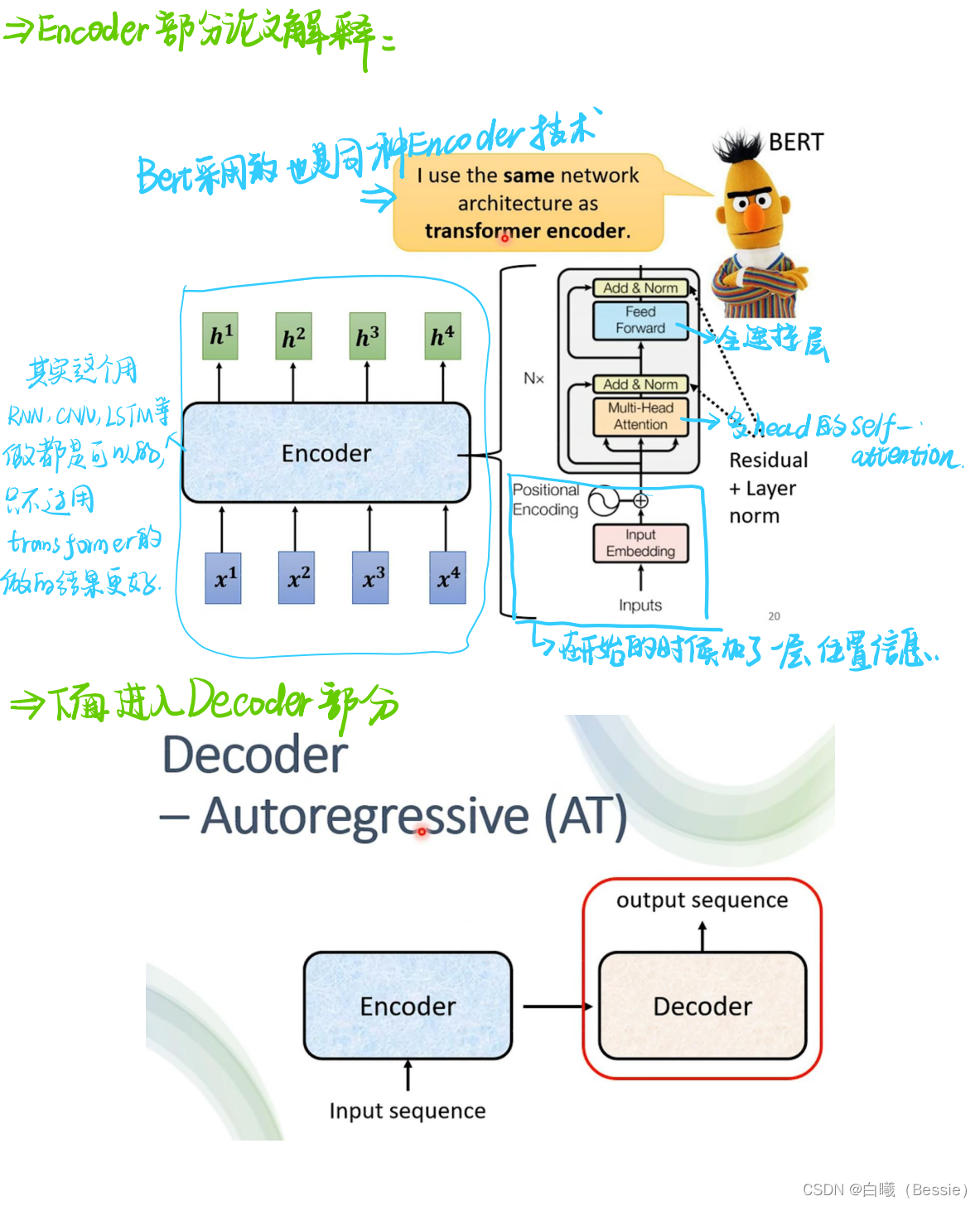
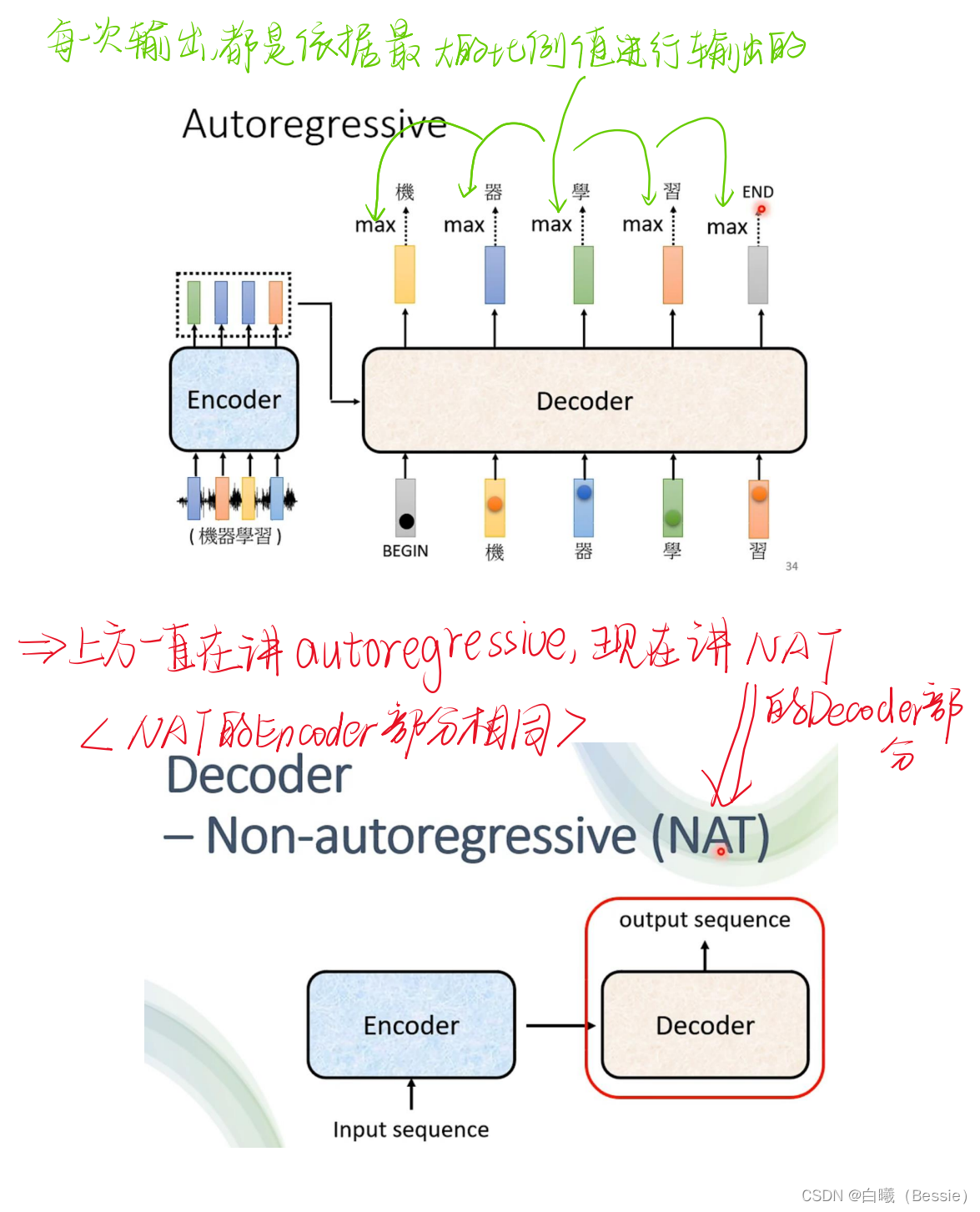
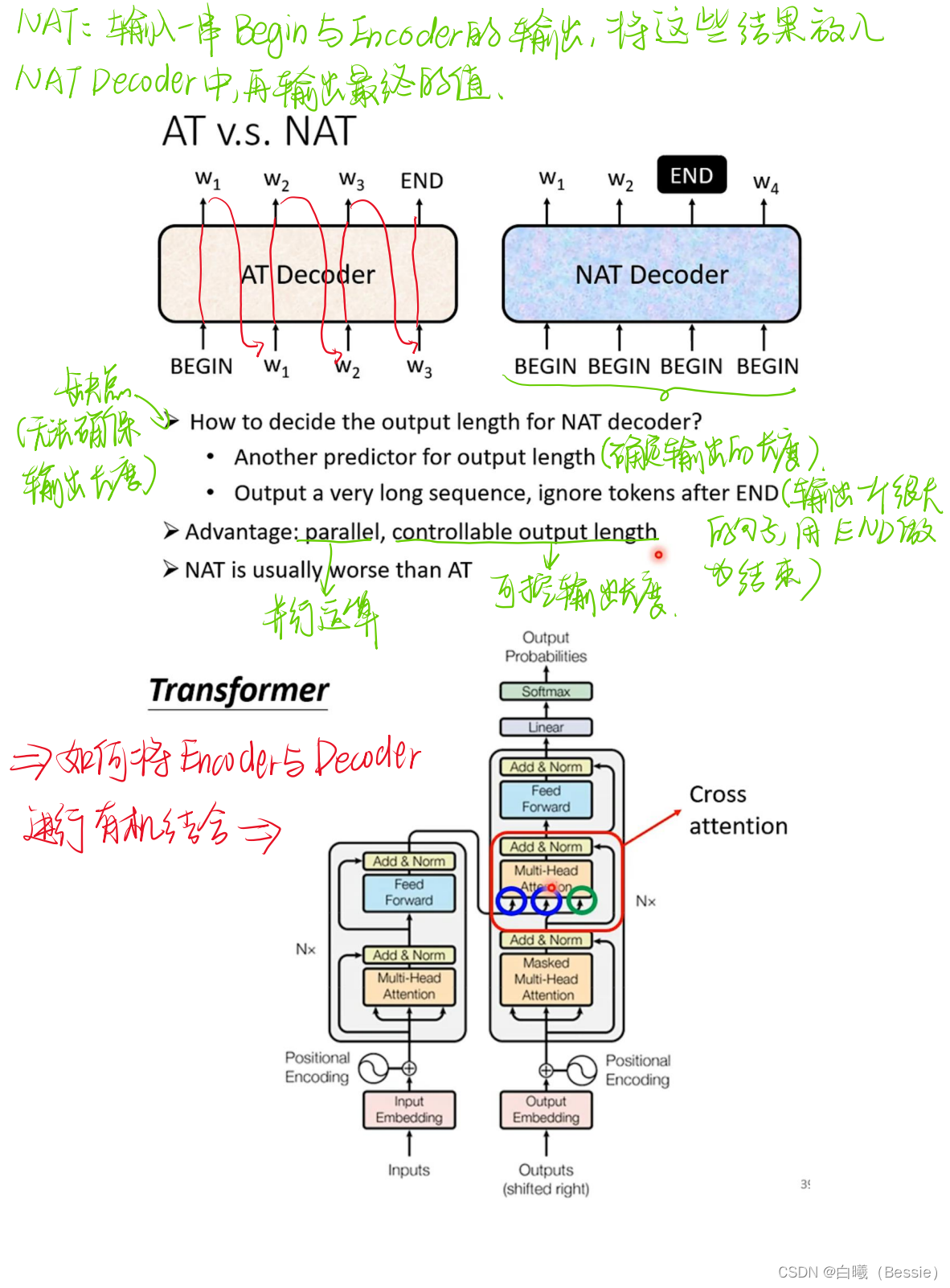
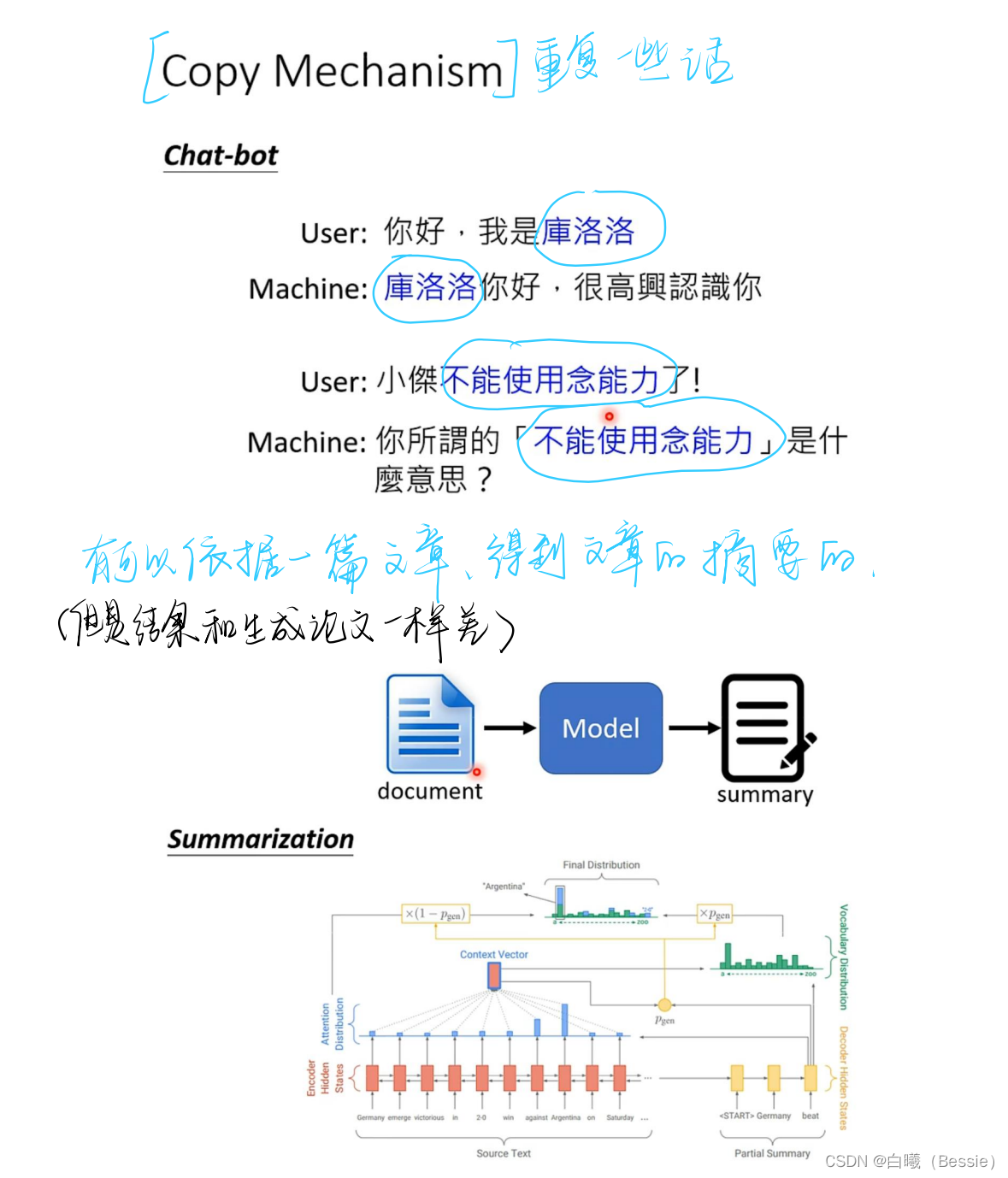
主要也就是encoder和decoder(编码器与解码器)
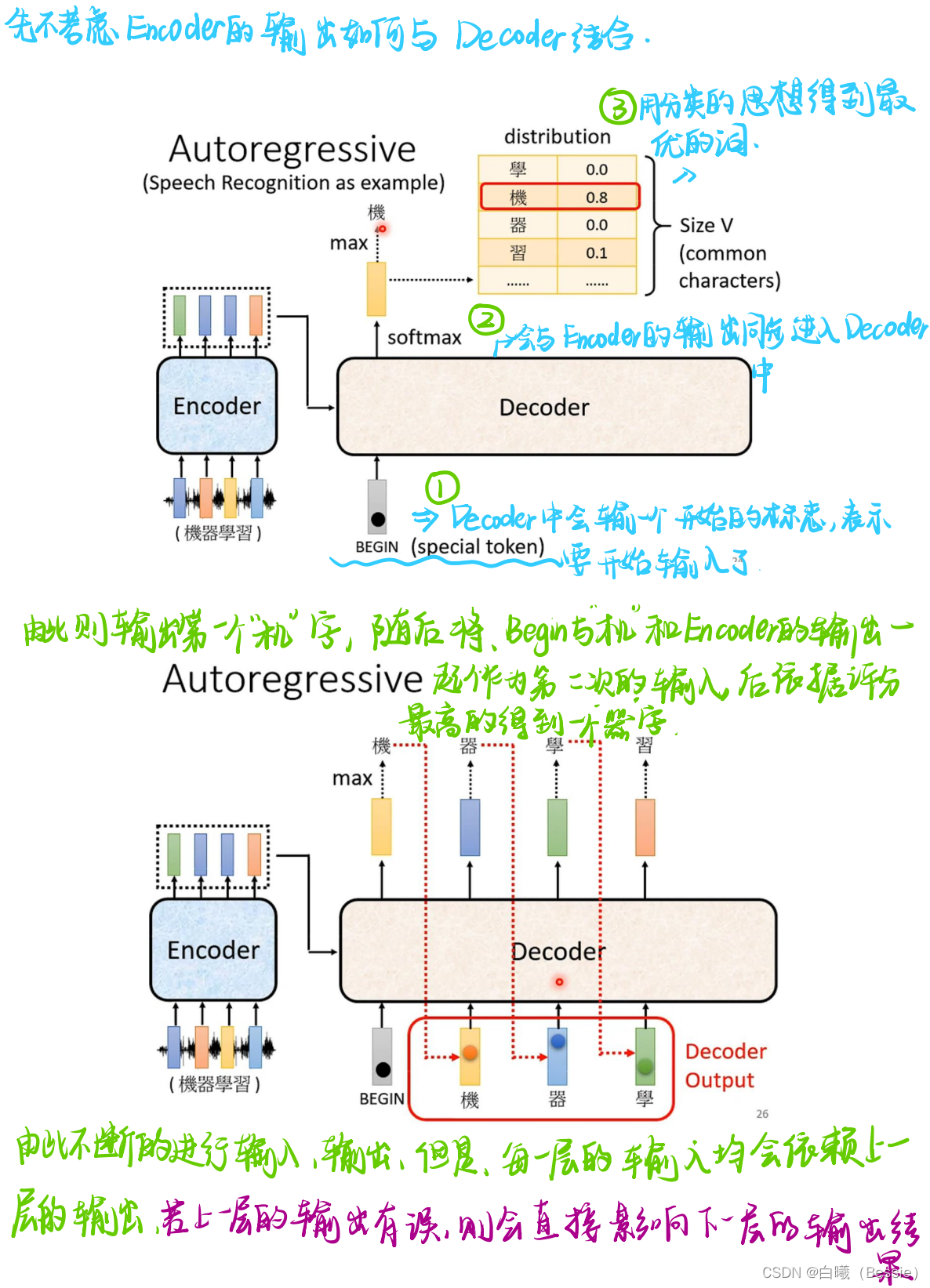
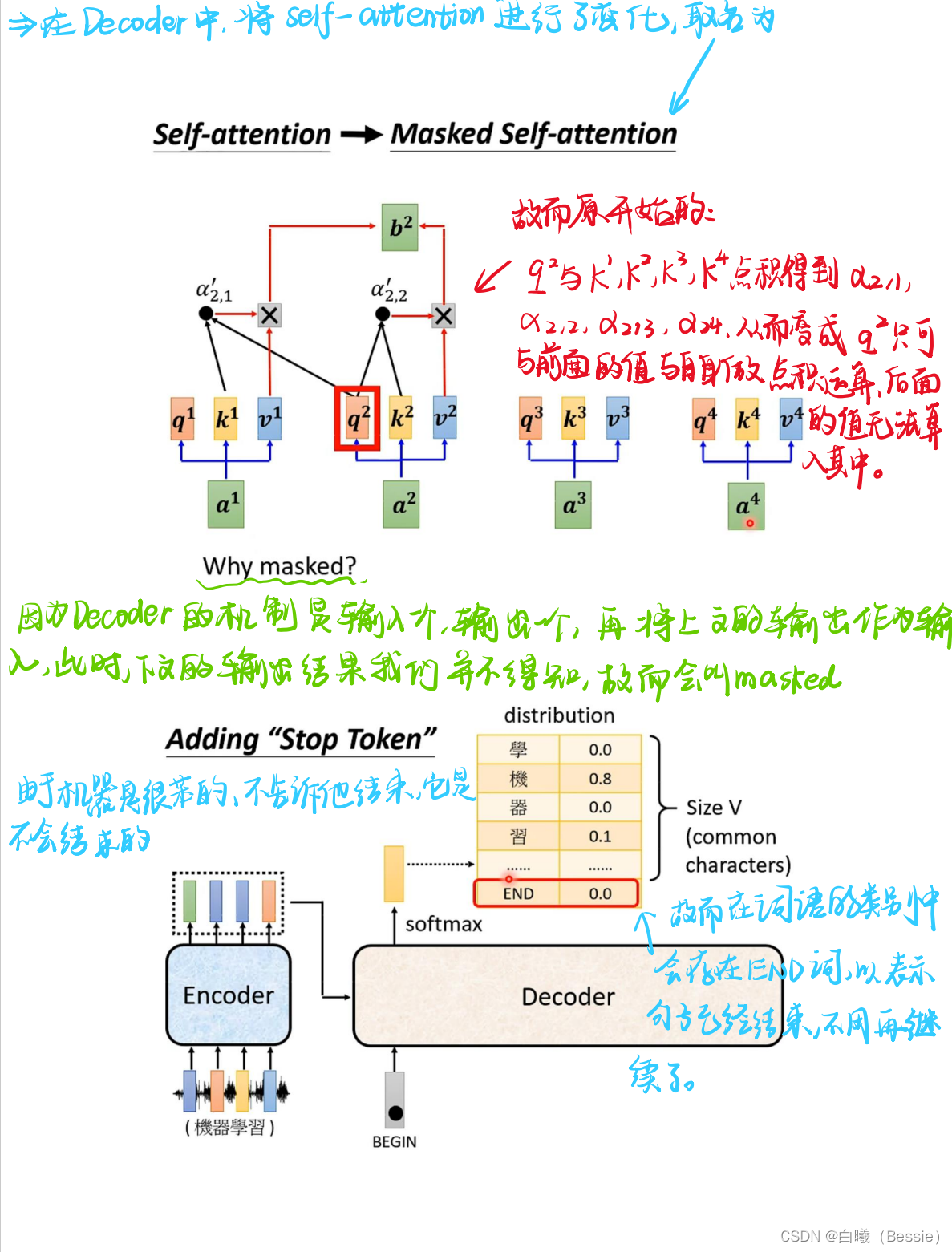
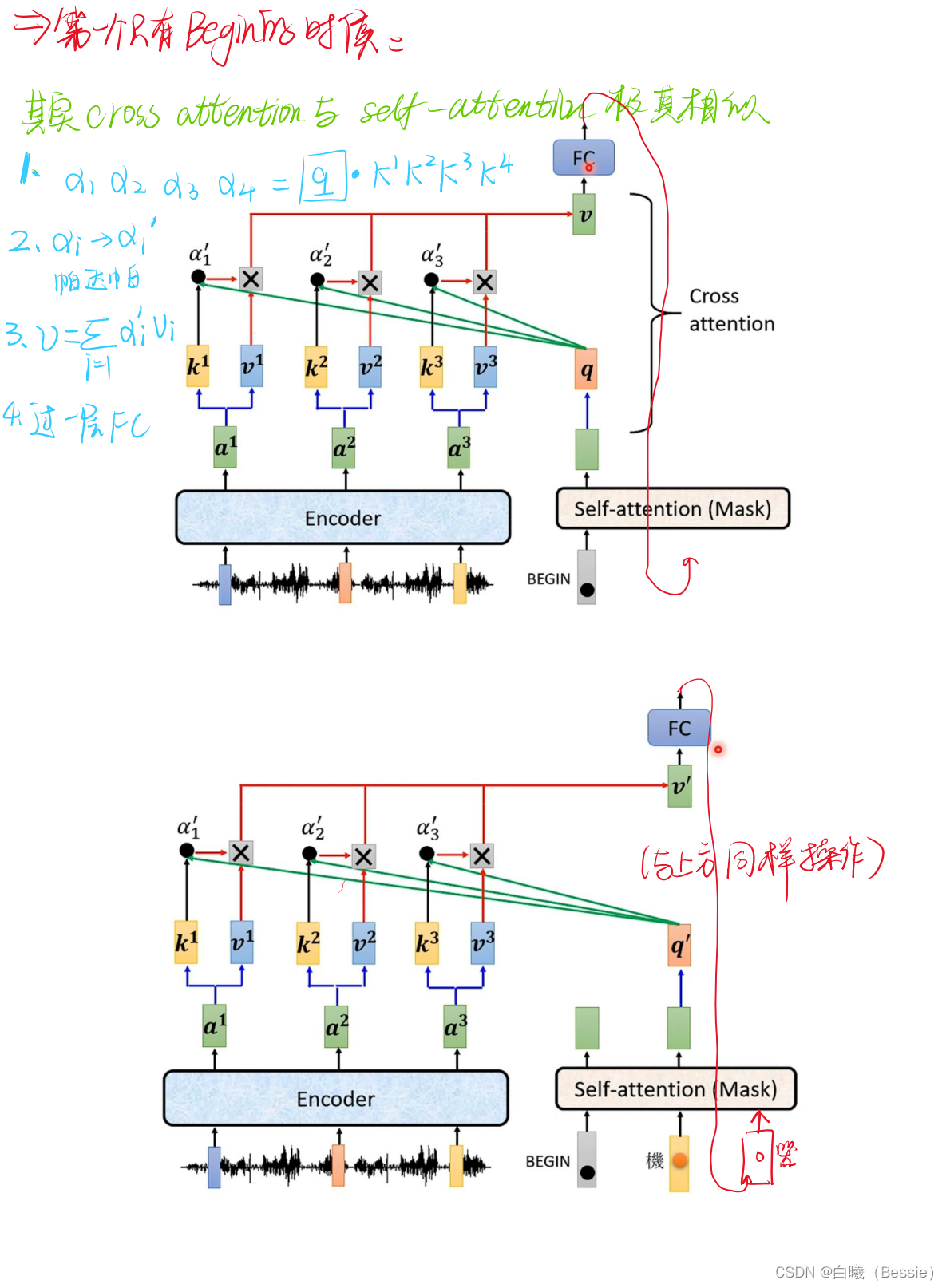
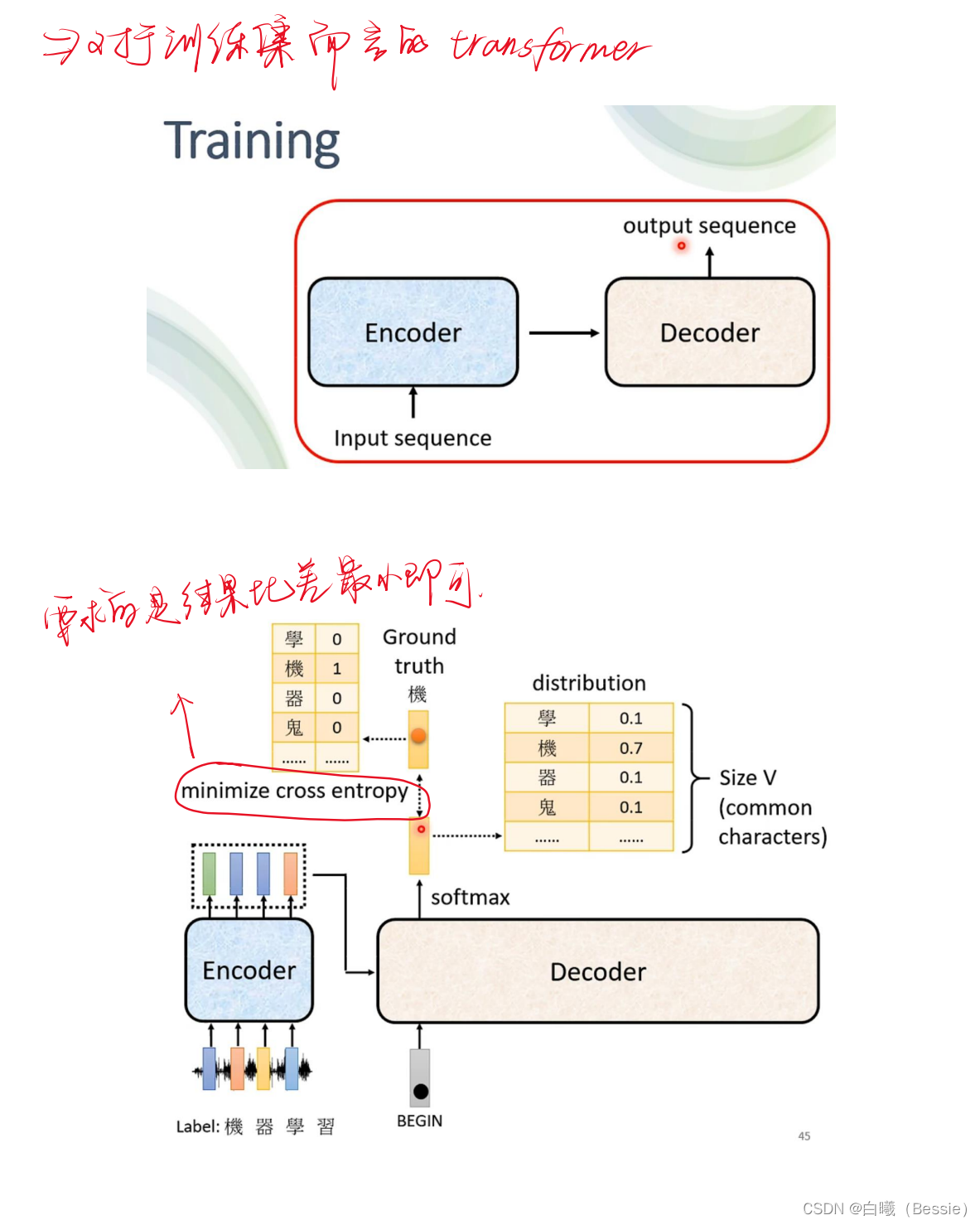
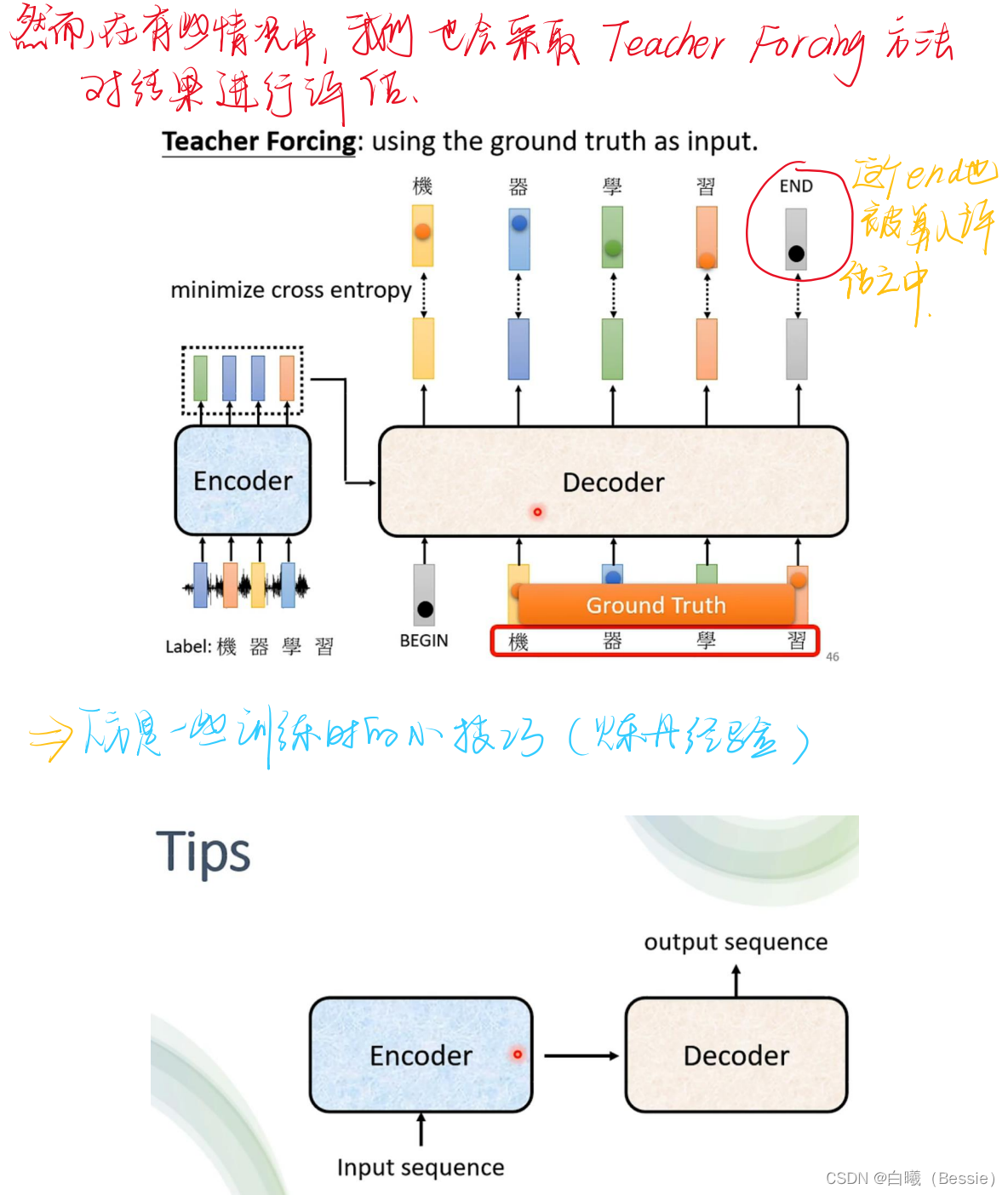
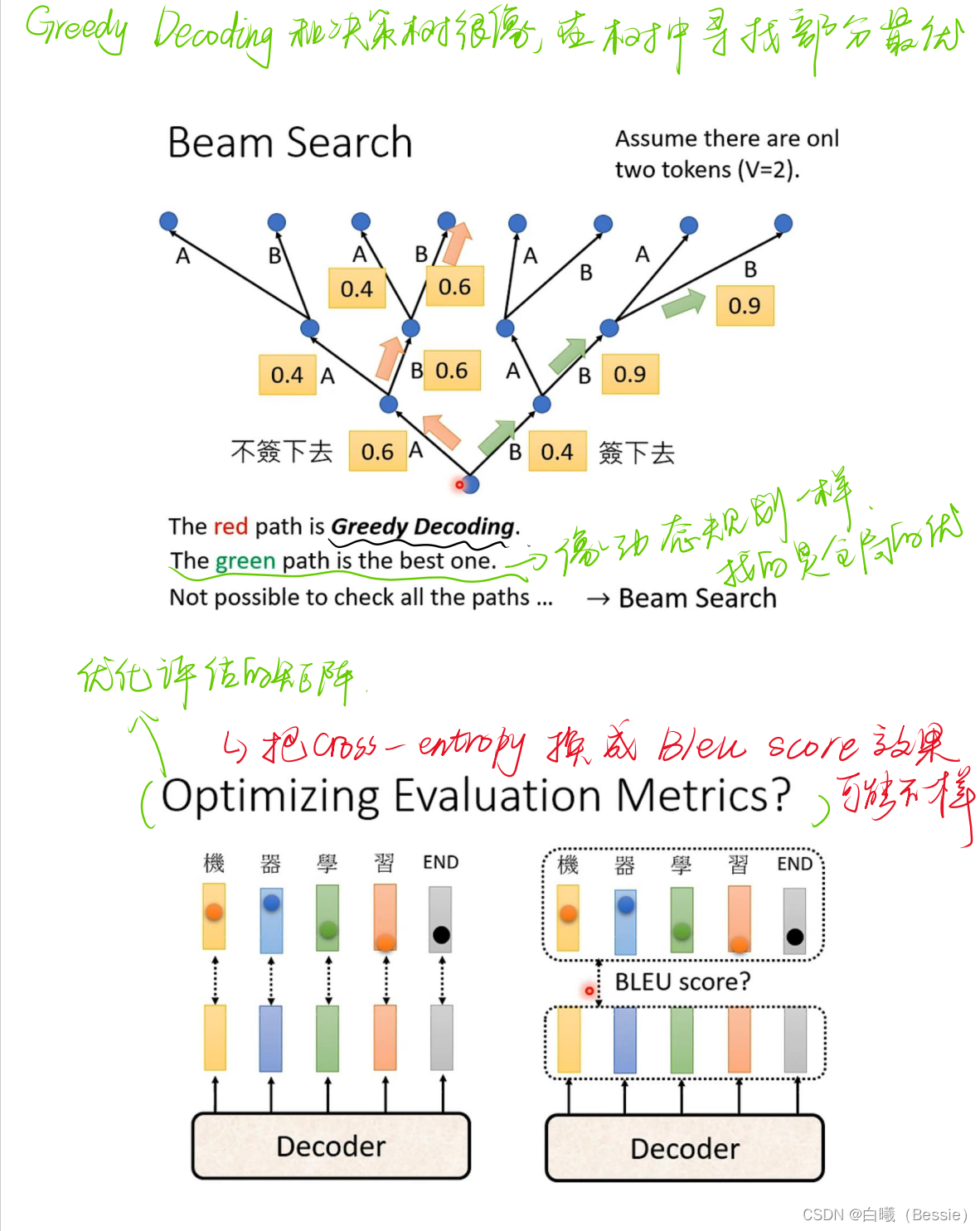
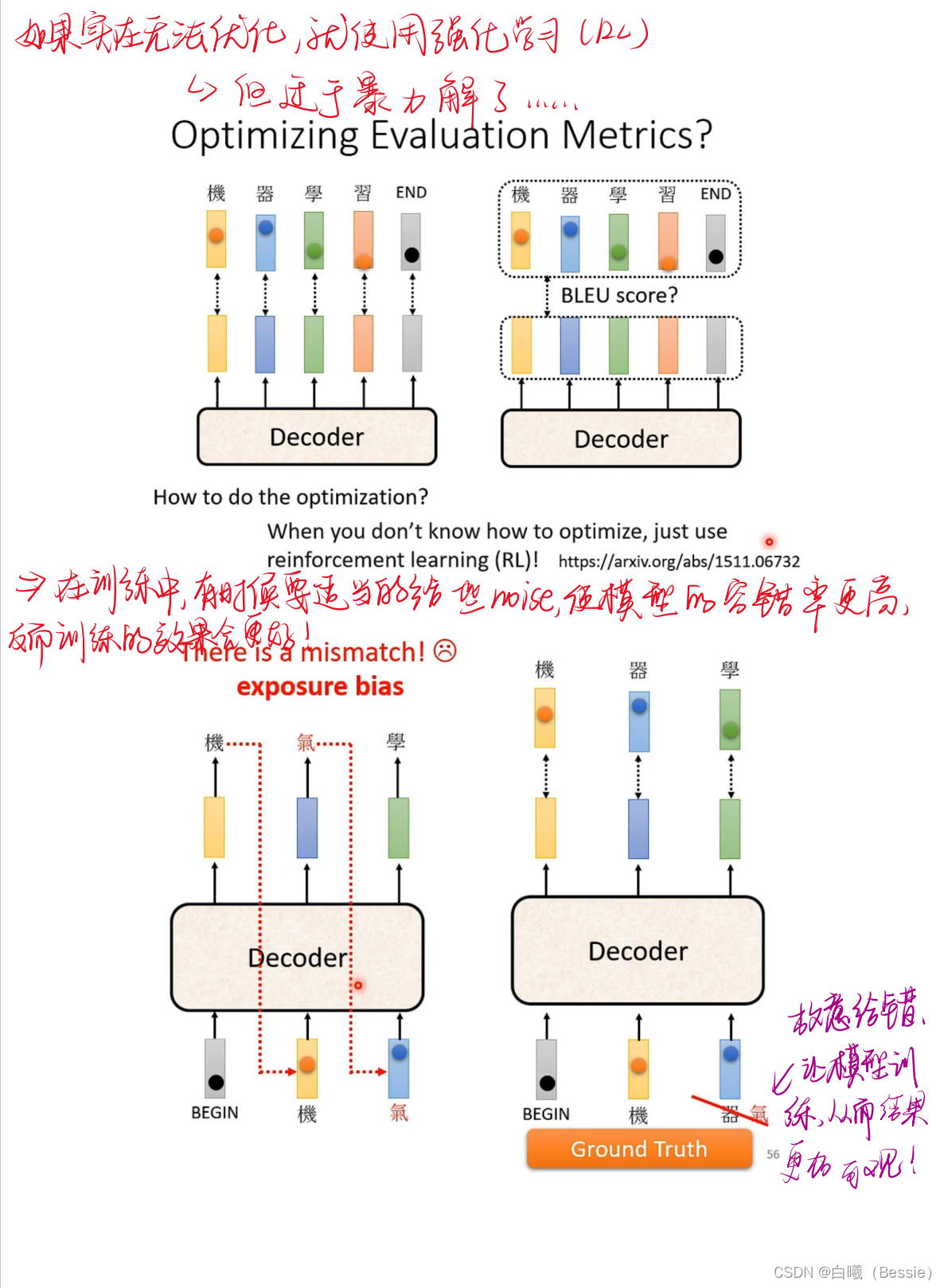
encoder比较简单,采用的是传统的self-attention的技术加上residual进行搭配,decoder是将begin作为原始输入,采用的是masked-self-attention,然后采用类似于self-attention的手段将encoder的结果与decoder的进行融合,然后再过一层酷似encoder的区域,最后过一层全连接以及归一化得到最终结果。
decoder的起始步骤是依赖begin的最初结果得到的最后值,这个值再放入decoder的步骤中进行求得结果,所以说每一个输出都是会与下一个输出有紧密联系的。
手写笔记部分



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











