






这篇论文建立了image regions, caption words 以及RNN state三者之间的相互联系。相较于之前的方法,这篇论文建立了image regions, caption words 之间的直接联系。
通过三种不同的方式实现了区域注意,并对比了三者的性能
Introduction
引言部分先对先前的工作进行了一个简单的回顾,之后引出了论文的方法,并阐述了这篇论文的贡献。
先前的工作
- 基于encoder-decoder的基本方法,用CNN将图片编码成一个向量表达,然后用RNN逐词解码。受限于图像分析是(i)static,不能随着描述生成的时间步骤改变;(ii)不能spatially localized,将图片描述为一个整体,instead of focousing on local aspects relevant to parts of the description。
- Attention机制通过动态的关注图像区域解决了上述限制。 For some tasks the definition of parts of the input to attend to are clear and limited in number.For other tasks with complex inputs, such as image captioning, the notion of parts is less clear.
本论文的贡献
- 新的attention mechanism:建立了models the interplay between the RNN state, image region descriptors, and word embedding vectors by means of three pairwise interactions.相较于之前的一些方法 本文的模型 in a single end-to-end trainable system.在每一个时间步骤预测下一个词和相关的图像区域。
- integrate a localization subnetwork in our model—similar to spatial transformer networks.先前基于CNN grids的注意机制中的regions不能随着图像内容调整,基于object proposals,proposal模型与caption模型训练是分离的。
- 成体系的实验研究,验证了三种不同的注意生成方式对性能提升的作用。
Related work
encoder-decoder模型
- 基本模型
- 注意机制
- 属性检测
Visual grounding of natural language expressions
object proposal
Attention in encoder-decoder captioning

Baseline CNN-RNN encoderdecoder model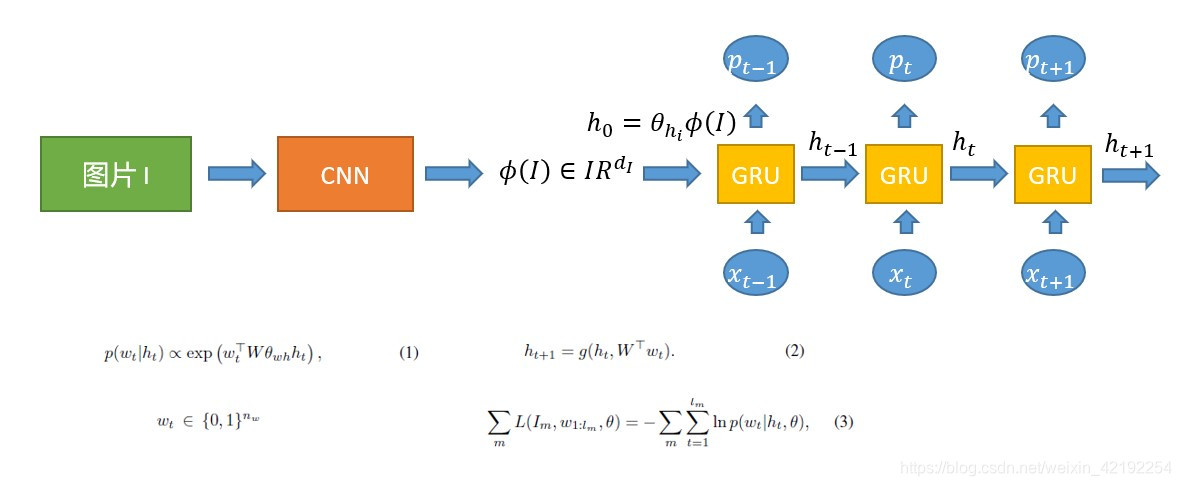
Attention for prediction and feedback
随着图像的生成动态的关注image regions.

Inspired by weakly supervised object localization methods, we score region-word pairs and aggregate these scores by marginalization to obtain a predictive distribution over the next word in the caption.
如路径1所示
we maintain the word-state interaction in Eq. (1) of the baseline model, to ensure temporal coherence in the generated word sequence by recursive conditioning on all previous words.
如路径2所示
a region-state interaction term allows the model to highlight and suppress image regions based on their appearance and the state, implementing a dynamic salience mechanism.
如路径3所示

定义了一个联合分布,在每个时间步骤可以同时生成下一个单词的预测(w)和image-regions(v)

The first scores state-word combinations, as in the baseline model.
The second scores the compatibility between words and region appearances, as in weakly supervised object localization.
The third scores region appearances given the current state, and acts as a dynamic salience term.
The last two unary terms implement linear bias terms for words and regions respectively.
几个公式:




Areas of attention
Activation grid
Object proposals
Spatial transformers


















 380
380

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









