







 本文介绍如何使用线性回归来拟合一组数据,并通过梯度下降算法优化参数,以最小化预测值与实际值之间的差距。文章详细展示了Python代码实现过程。
本文介绍如何使用线性回归来拟合一组数据,并通过梯度下降算法优化参数,以最小化预测值与实际值之间的差距。文章详细展示了Python代码实现过程。
原理
我们得到一系列数据,最先试用的方法一般就是尝试用一条直线进行拟合,也就是线性回归。寻找一条直线,可以描述这一系列点的关系。
我们有采样得到的实际值y和根据回归直线方程计算得到的wx+b。那么目标就是使这两个值的差距最小化
l
o
s
s
=
(
w
x
+
b
−
y
)
2
loss=(wx+b-y)^2
loss=(wx+b−y)2
在本次实验中,在直线方程中引入一个高斯噪声生成了100个随机点。如下:
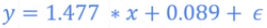
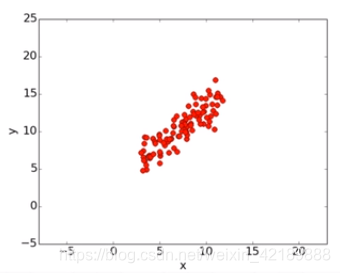
具体来说,优化函数如下:

利用梯度下降算法,可以迭代优化参数,使得目标函数逐渐减小。
pytorch实现
1、计算总误差,即目标函数
得到当前的直线参数b和w,计算根据参数得到的y‘和真正的y之间的均方差。
def comput_err_for_line_points(b, w, points):
totalError = 0
for i in range(0, len(points)):
x = points[i, 0]
y = points[i, 1]
totalError += (y - (w * x + b)) ** 2
return totalError / float(len(points))
2、计算梯度,并根据梯度更新参数
计算梯度,就是计算目标函数在各个点的导数值的相反数求和。 计算完毕之后,用总梯度更新参数w和b
def step_gradient(b_current, w_current, points, learningRate):
b_gradient = 0
w_gradient = 0
N = float(len(points))
# 求每一个点的梯度,并累加,求平均(批量梯度下降)
for i in range(0, len(points)):
x = points[i, 0]
y = points[i, 1]
b_gradient += -(2 / N) * (y - ((w_current * x) + b_current))
w_gradient += -(2 / N) * x * (y - ((w_current * x) + b_current))
new_b = b_current - (learningRate * b_gradient)
new_w = w_current - (learningRate * w_gradient)
return [new_b, new_w]
3、循环更新参数
对更新梯度操作进行一定数量的迭代。
def gradiend_descent_runner(points, starting_b, starting_m,
laerning_rate, num_iterations):
b = starting_b
m = starting_m
for i in range(num_iterations):
b, m = step_gradient(b, m, np.array(points), laerning_rate)
return [b, m]
4、开始运行
def run():
points = np.genfromtxt("Ldata.csv", delimiter=",")
learning_rate = 0.0001
ini_b = 0
ini_w = 0
num_iterations = 1000
print("Starting gradient decent at b={0},w={1},error={2}"
.format(ini_b, ini_w,
comput_err_for_line_points(ini_b, ini_w, points)))
print("Running...")
[b, m] = gradiend_descent_runner(points, ini_b, ini_w, learning_rate, num_iterations)
print("After {0} iterations b={1},m={2},error={3}"
.format(num_iterations, b, m, comput_err_for_line_points(b, m, points)))
运行结果



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









