







近期在自己的数据集上尝试了BERT 的fine-tuning,效果不错,现在把自己的操作过程分享给大家。
由于自己的数据不方便分享,我替换成了一份外卖情感分析,供大家使用。
数据及完整代码:
https://github.com/BruceJust/Sentiment-classification-by-BERT
首先下载huggingface出品的transformers包,这是一个预训练模型大集合,也有各种常见任务的案例。
pip install transformershttps://github.com/huggingface/transformers
然后还需要从git上下载glue.py, run_tf_glue.py两个文件用于后序修改。
glue.py是数据处理部分,run_tf_glue.py是训练部分
https://github.com/huggingface/transformers/blob/master/examples/run_tf_glue.py
数据处理
首先对数据做处理,把一份完整数据拆分为训练集,验证集
import pandas as pd
from sklearn.model_selection import train_test_split
import numpy as np
# 将数据随机拆分为train,test
def prepare_data():
df = pd.read_csv('./data/waimai_10k.csv')
x = df[['review', 'label']]
y = np.arange(0, len(x))
x_train, x_test, y_train, y_test = train_test_split(x, y)
x_train.to_csv('data/train.csv', index=False, header=False)
x_test.to_csv('data/dev.csv', index=False, header=False)
prepare_data()然后开始修改glue.py,把我们的数据整理成模型需要的数据格式。
打开glue.py时候会发现里面有一个
glue_convert_examples_to_features,这个函数保留,(数据格式整理)
和各种Processor,大部分要删除(数据读取)
这里的Processor是各种刷榜任务的案例,由于我们的数据格式和人家的不同,那么
我们可以参考一个processor创建自己的,
这里我copy了ColaProcessor,创建一个自己的UserProcessor
完整复制,然后主要是修改里面的_create_examples,适应自己的数据格式,把文本和label对应上
然后修改了_read_tsv, 由于我传入的是csv文件,稍有不同,所以修改一下。
修改后如下:
class UserProcessor(DataProcessor):
"""Processor for the July data set (GLUE version)."""
def get_example_from_tensor_dict(self, tensor_dict):
"""See base class."""
return InputExample(
tensor_dict["idx"].numpy(),
tensor_dict["sentence"].numpy().decode("utf-8"),
None,
str(tensor_dict["label"].numpy()),
)
def get_train_examples(self, data_dir):
"""See base class."""
return self._create_examples(self._read_tsv(os.path.join(data_dir, "train.csv")), "train")
def get_dev_examples(self, data_dir):
"""See base class."""
return self._create_examples(self._read_tsv(os.path.join(data_dir, "dev.csv")), "dev")
def get_labels(self):
"""See base class."""
return ["0", "1"]
def _read_tsv(self, input_file):
df = pd.read_csv(input_file)
return list(df.values)
def _create_examples(self, lines, set_type):
"""Creates examples for the training and dev sets."""
examples = []
for (i, line) in enumerate(lines):
guid = "%s-%s" % (set_type, i)
text_a = line[0]
label = str(line[1])
examples.append(InputExample(guid=guid, text_a=text_a, text_b=None, label=label))
return examples
然后再把自己的Userprocessor添加到字典中,如下:
glue_tasks_num_labels = {
"user": 2,
}
glue_processors = {
'user': UserProcessor,
}
glue_output_modes = {
"user": "classification",
}glue_convert_examples_to_features中的有一句建议修改下,
# if is_tf_available() and is_tf_dataset:
if is_tf_available(): # 生成满足tf的数据格式训练
数据处理部分就搞定了,然后是修改训练部分run_tf_glue.py。
task名词改成自己的。
TASK="user"
BERT文件地址修改,由于预训练的BERT很大,所以就事先下载了放本地加载,也可以保持原文件的模式,让代码自己下载
bert-base-multilingual-cased 是多语种的版本,由于我自己的任务是中英文混杂的,所以使用这个版本。
分享给大家的是中文的情感文本,也许用纯中文的BERT会效果更好。
git上也没有放模型文件,太大了。
下载地址:
config: https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-multilingual-cased-config.json
model: https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-multilingual-cased-tf_model.h5
vocab: https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-multilingual-cased-vocab.txt
bert_config_dir = '.\\bert\\bert-base-multilingual-cased-config.json'
bert_vocab_dir = '.\\bert\\bert-base-multilingual-cased-vocab.txt'
bert_dir = '.\\bert\\bert-base-multilingual-cased-tf_model.h5'
config = BertConfig.from_pretrained(bert_config_dir, num_labels=num_labels)
tokenizer = BertTokenizer.from_pretrained(bert_vocab_dir)
model = TFBertForSequenceClassification.from_pretrained(bert_dir, config=config)
然後再修改数据加载部分的代码
# make dataset from file
train_examples = processor.get_train_examples(data_dir=data_dir)
valid_examples = processor.get_dev_examples(data_dir=data_dir)
# Prepare dataset for GLUE as a tf.data.Dataset instance
train_dataset = glue_convert_examples_to_features(train_examples, tokenizer, MAX_LEN, TASK)
valid_dataset = glue_convert_examples_to_features(valid_examples, tokenizer, MAX_LEN, TASK)
到这里就ok了,可以开始训练了。
learning_rate如果需要的可以根据情况修改
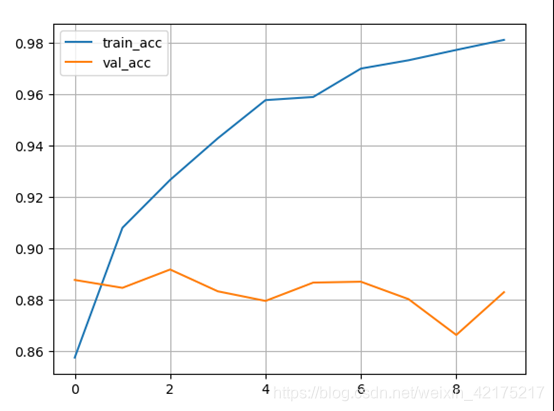
下面是初步训练的结果,10个epochs。
可以看到train_acc一直在增长,val_acc没怎么变,因为已经到88,89了。
BERT模型比较强大,一上来就容易达到最高分了。
最后几行还有一份测试代码,可以测试训练效果。
再次附上数据及完整代码:
https://github.com/BruceJust/Sentiment-classification-by-BERT

















 3340
3340

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









