







简介:本书深入介绍Unix操作系统中的Shell编程,涵盖Unix基础和Shell脚本编写技巧。Shell作为Unix的命令解释器和自动化任务的关键工具,其编程语言虽简洁但功能强大,能处理文件操作、进程控制等复杂任务。本书包含从基础命令到高级话题的全面内容,为读者提供最原汁原味的技术内容和编程实践,无论是初学者还是有经验的用户都能提高对Unix系统和Shell编程的理解和应用。 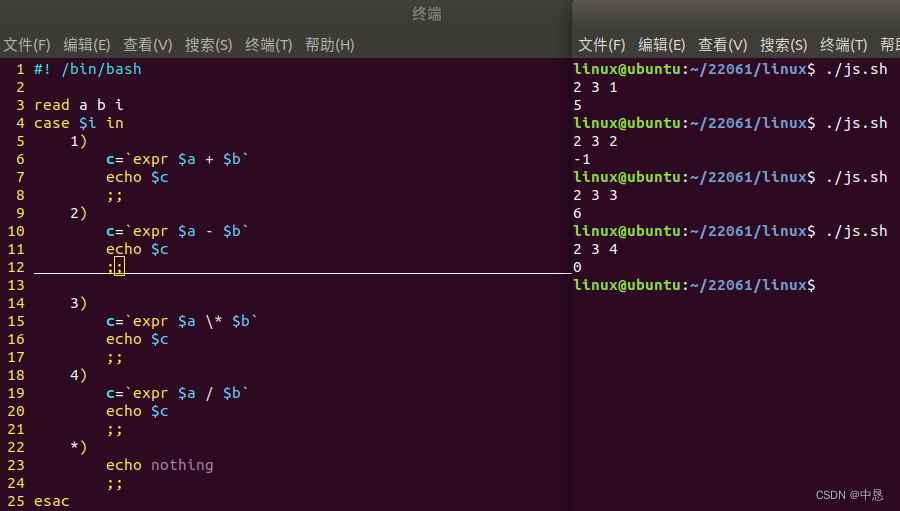
1. Unix系统基础
Unix系统是计算机操作系统的一个重要分支,它于1969年由Ken Thompson和Dennis Ritchie在AT&T的贝尔实验室开发。Unix系统以其稳定性和高效性著称,广泛应用于服务器、工作站和移动设备等平台。其设计理念强调简洁、小型化和模块化,使得Unix系统具有了极佳的灵活性和强大的多任务处理能力。
Unix系统的内核是其核心部分,负责管理系统资源,包括CPU、内存和设备驱动程序等。内核通过提供一系列的系统调用,允许用户程序和应用程序与硬件设备进行交云。内核之上是shell,它是用户和系统之间的接口,处理用户的输入并调用相应的系统命令和服务。Unix系统还包含了丰富的应用程序集,包括文本编辑器、编译器、网络工具等,满足了日常编程和系统管理的需要。
Unix系统的另一个显著特点是其命令行界面,这使得它对于习惯于编程的用户来说更加直观和强大。通过学习Unix命令和Shell编程,用户可以轻松地控制文件系统、执行自动化任务和管理系统配置。在接下来的章节中,我们将深入了解Shell编程以及如何利用它来更高效地工作。
2. Shell编程概述
2.1 Shell编程的基本概念
2.1.1 什么是Shell编程
Shell编程是指使用命令行解释器(Shell)编写的一系列命令序列,这些命令能够自动化完成复杂的任务。Shell脚本通常保存在文本文件中,可以在Unix/Linux环境下直接执行,而无需编译。Shell脚本的编写和执行,为系统管理员和开发人员提供了极大的便利,使得任务自动化和批处理变得高效且易于管理。
2.1.2 Shell编程的重要性
Shell编程的重要性主要体现在以下几个方面: - 自动化执行重复任务,提高工作效率。 - 简化复杂系统管理操作,减少人为错误。 - 可以与系统底层进行交互,执行高级管理操作。 - 跨平台兼容性强,可在多种Unix/Linux系统间移植。 - 提供强大的文本处理能力,特别是在数据处理和分析方面。
2.2 Shell编程与其他编程语言的比较
2.2.1 Shell与其他编程语言的特点对比
Shell编程相较于其他编程语言(如C、Python等)具有以下特点: - 脚本语言,无需编译直接执行,快速开发和调试。 - 与操作系统紧密集成,可以执行底层操作。 - 语法相对简单,易于学习和使用,特别适合系统管理任务。 - 功能强大,特别是在字符串处理和文件操作方面。 - 可以调用其他语言编写的程序,实现跨语言功能。
2.2.2 选择合适Shell环境的理由
选择Shell编程环境的理由包括: - Bash(Bourne Again SHell) 是最常用的Shell之一,广泛支持在多种Unix/Linux系统上,具有丰富的命令集和良好的跨平台兼容性。 - Zsh 提供了许多增强功能,比如语法高亮、自动补全等,适合高级用户。 - Ksh(Korn Shell) 兼具Bourne Shell和C Shell的特点,具有良好的性能和强大的脚本编写能力。 - C Shell(csh) 更加用户友好,提供了类似C语言的语法,适合交互式使用。
2.3 Shell编程的学习路径和资源
2.3.1 学习Shell编程的先决条件
在开始学习Shell编程之前,应当具备以下先决条件: - 熟悉基本的Unix/Linux命令行操作。 - 了解操作系统的基本工作原理。 - 掌握至少一种编程语言的基础知识,有助于理解编程逻辑。
2.3.2 推荐的学习材料和实践平台
为了有效学习Shell编程,以下材料和平台可以帮助你: - 在线教程和课程 :如Codecademy、Udemy提供的Shell编程课程。 - 官方文档 :Bash手册(man bash)提供了详细的功能和命令描述。 - 书籍 :如《The Linux Command Line》是学习Shell编程的经典之作。 - 实验环境 :利用虚拟机或Docker容器来尝试不同的Shell环境。 - 实践项目 :参与开源项目或编写自己的Shell脚本来加深理解。
通过以上内容,读者应该对Shell编程有了初步的了解。接下来,我们将深入探讨文件操作与目录管理,这是Shell编程中用于处理文件系统和目录结构的核心概念。随着学习的深入,我们会逐步揭开Shell脚本的神秘面纱,解锁其强大的自动化和管理功能。
3. 文件操作与目录管理
3.1 文件系统的基本概念和结构
3.1.1 Unix/Linux文件系统布局
Unix/Linux系统的文件系统布局遵循一种称为“一切皆文件”的设计理念。文件系统从根目录( / )开始,是所有目录和文件的起点。其下的目录结构有其特定的用途,例如 /bin 目录存放用户命令, /etc 存储系统配置文件, /home 提供用户主目录, /var 存放经常变化的文件(如日志文件)。了解和熟悉这些目录结构是进行有效文件管理和操作的前提。
3.1.2 文件类型和文件权限基础
在Unix/Linux系统中,文件类型非常丰富,常见的类型包括普通文件、目录、链接、设备文件等。文件权限则定义了不同的用户对文件的操作权限,包括读( r )、写( w )和执行( x )权限。通过 ls -l 命令可以查看文件的类型和权限。权限的设置对于系统的安全性至关重要,合理的权限配置能有效地保护数据不被非法访问或修改。
3.2 文件操作的Shell命令
3.2.1 创建、删除和复制文件命令
文件操作是日常管理工作中的基础。使用 touch 命令可以创建一个新的空文件, rm 命令用于删除文件,而 cp 命令则可以复制文件到指定位置。这些命令在操作文件时都支持多种选项,比如 -i 会在删除文件前提示, -r 可以递归地处理目录。
# 创建一个新文件
touch newfile.txt
# 删除一个文件
rm -i oldfile.txt
# 复制一个文件
cp sourcefile.txt /path/to/destination/
3.2.2 查找和链接文件的技巧
在处理大量文件时, find 命令是非常有用的。它能够根据各种条件来查找文件,比如按照名称、修改日期、文件大小等条件。另一方面,链接文件(包括硬链接和符号链接)允许用户在系统中创建文件的多个引用,这对于维护文件系统的组织结构和节省空间都有显著作用。
# 查找特定文件
find / -type f -name "pattern"
# 创建符号链接
ln -s /path/to/target linkname
3.3 目录结构的管理与维护
3.3.1 目录的创建、删除和浏览
目录管理是文件系统操作的重要组成部分。 mkdir 命令用于创建新目录, rmdir 可以删除空目录。浏览目录则通常使用 cd 切换目录和 ls 查看目录内容。理解这些基础命令对于进行有效的目录管理至关重要。
3.3.2 权限管理及目录安全性增强
权限管理是保证文件系统安全的重要手段。使用 chmod 命令可以修改文件和目录的权限,而 chown 命令用于改变文件或目录的所有者。通过这些命令,可以实现文件的访问控制,确保只有授权用户才能访问敏感数据。
# 修改文件权限
chmod 755 somefile
# 改变文件所有者
chown username somefile
文件系统是Unix/Linux系统的核心组成部分,而文件操作和目录管理是系统管理中不可或缺的技能。通过对文件的创建、删除、查找、链接以及权限的设置和管理,管理员可以高效地维护和优化系统性能,确保数据的安全性和完整性。这些操作虽然基础,但对系统安全和性能的影响不可忽视。掌握这些技术,将为读者在Unix/Linux环境下进行高效编程和系统维护提供重要支持。
4. Shell脚本结构(变量、函数、条件语句、循环结构)
在Unix/Linux环境中,Shell脚本是自动化任务、处理数据和实现复杂操作的关键。Shell脚本的结构由变量、函数、条件语句和循环结构等组成,它们共同构成了脚本的骨架。本章将深入介绍这些组件的工作原理和应用方法。
4.1 Shell脚本中的变量和数据类型
4.1.1 变量的定义和赋值
在Shell脚本中,变量无需声明其数据类型即可使用,它们默认为字符串。变量的命名应避免使用系统保留的关键字和特殊字符。变量通过赋值操作符“=”来赋值,等号两边不可有空格。
#!/bin/bash
# 定义变量并赋值
user="John"
echo "The username is: $user"
在上述代码中,定义了一个名为 user 的变量,并将其赋值为字符串"John"。之后,使用 echo 命令输出变量值。
4.1.2 数据类型及其在脚本中的应用
尽管Shell脚本中的变量通常被视为字符串,但它们可以用于处理整数和浮点数等其他数据类型。使用算术扩展可以处理整数运算,而bc(Basic Calculator)工具可以用于执行浮点数运算。
#!/bin/bash
# 整数运算
num1=10
num2=5
sum=$((num1 + num2))
echo "The sum is: $sum"
# 浮点数运算
num3=2.5
num4=3.1
bc <<< "scale=2; $num3 + $num4"
在整数运算的例子中,使用了 $(( )) 来执行算术运算,并将结果存储在变量 sum 中。对于浮点数运算,通过管道将计算表达式传递给 bc 工具, scale=2 表示保留两位小数。
4.2 Shell脚本中的函数
4.2.1 函数的定义和调用
函数是组织脚本逻辑和代码复用的基本单元。在Shell脚本中,定义函数使用 function 关键字或直接使用函数名,后跟一对圆括号和一对花括号。
#!/bin/bash
# 定义函数
function greet() {
echo "Hello, $1!"
}
# 调用函数,并传递参数
greet "Alice"
在此例中,定义了一个名为 greet 的函数,它接受一个参数 $1 ,并在调用时输出问候语。
4.2.2 参数传递和返回值
Shell脚本中的函数支持通过位置参数 $1 , $2 , ... 来接收参数。函数的返回值通过 return 命令返回,并且返回值是16位的退出状态码,其中0表示成功,其他值表示失败。
#!/bin/bash
# 定义带有返回值的函数
function add() {
local sum=$(( $1 + $2 ))
echo $sum
return 0
}
# 调用函数并获取返回值
sum=$(add 2 3)
echo "The sum is: $sum"
在上述代码中, add 函数计算两个参数的和,并通过 echo 命令输出,然后通过 return 命令返回0,表示成功。返回值可以通过命令替换 $(...) 来捕获。
4.3 条件语句和循环结构的应用
4.3.1 条件语句的类型及使用场景
条件语句允许根据不同的条件执行不同的代码块。在Shell脚本中, if , case 是最常用的条件语句。
#!/bin/bash
# 使用if条件语句
number=5
if (( number > 10 )); then
echo "Number is greater than 10"
elif (( number < 5 )); then
echo "Number is less than 5"
else
echo "Number is 10 or equal"
fi
在此例中, if 条件语句检查变量 number 的值,并根据比较结果执行相应的代码块。
4.3.2 循环结构的控制和优化
循环结构用于重复执行一系列命令。 for , while , until 是Shell中常用的循环类型。
#!/bin/bash
# 使用for循环
for i in {1..5}; do
echo "Iteration $i"
done
# 使用while循环
counter=1
while (( counter <= 5 )); do
echo "Counter: $counter"
((counter++))
done
在这段代码中, for 循环使用大括号 {} 生成数字序列,并在每次迭代中输出序列值。 while 循环则根据条件 counter <= 5 进行迭代,并在每次循环结束时递增计数器。
通过本章内容的学习,您应该已经能够熟练掌握Shell脚本中的变量、函数、条件语句和循环结构,并能够编写结构化和功能完善的Shell脚本。在下一章中,我们将继续深入探讨管道和重定向的高级使用技巧,进一步提升脚本的灵活性和效率。
5. 管道和重定向使用
管道和重定向是Unix/Linux系统中处理数据流和文件I/O的基本技术。本章将深入探讨管道和重定向的概念、原理、使用方法以及它们的高级技巧,并且如何将它们结合起来使用来解决实际问题。
5.1 管道的概念及其重要性
5.1.1 什么是管道以及它的运作机制
在Unix/Linux系统中,管道是一种将一个命令的输出作为另一个命令输入的机制。管道符号 | 用于连接两个或多个命令,使得第一个命令的输出直接成为第二个命令的输入。这种机制极大地提高了数据处理的灵活性和效率。
# 示例:使用管道将ls命令的输出直接传递给grep命令进行搜索
ls | grep "file.txt"
在上述命令中, ls 列出当前目录下的所有文件和目录,然后通过管道 | 将这些信息传递给 grep 命令, grep 则根据提供的参数(在这里是"file.txt")来过滤出包含该字符串的行。
5.1.2 管道在数据处理中的应用案例
管道在数据处理中的应用非常广泛。例如,当需要对日志文件进行快速分析时,管道技术可以非常方便地将多个命令串连起来,形成数据处理的流水线。
# 示例:分析Apache访问日志文件,找出访问次数最多的前10个IP地址
cat access.log | cut -d ' ' -f1 | sort | uniq -c | sort -nr | head -n 10
这个例子中, cut 命令用于提取日志文件中的IP地址, sort 命令对IP地址进行排序, uniq -c 用于统计每个IP地址出现的次数,再次使用 sort 命令对次数进行排序,最后 head -n 10 输出访问次数最多的前10个IP地址。
5.2 重定向的原理和高级技巧
5.2.1 标准输入输出和错误输出的重定向
Unix/Linux系统中,每个运行中的进程都有三个默认的I/O流:标准输入(stdin)、标准输出(stdout)和标准错误输出(stderr)。重定向技术可以将这些流重定向到文件中。
- 标准输出重定向
>和>>:用于将命令的输出写入文件。>覆盖文件内容,>>在文件末尾追加。 - 标准错误输出重定向
2>:用于将命令的错误信息写入文件。
# 示例:将命令的输出写入文件,并追加标准错误输出到同一文件
command > output.txt 2>&1
这个命令将 command 的标准输出写入到 output.txt 文件中,同时将错误信息也重定向到 output.txt 。
5.2.2 高级重定向技巧和场景应用
高级重定向技巧包括同时处理标准输出和错误输出,以及使用 tee 命令同时在终端和文件中显示输出。
# 示例:使用tee命令将输出显示在终端,并写入到文件
command | tee output.txt
使用 tee 命令可以方便地实现这一功能,命令的输出既显示在终端,也写入到指定的文件中。
5.3 管道与重定向的结合使用
5.3.1 综合运用管道与重定向解决问题
管道和重定向可以结合使用来解决更复杂的场景问题。例如,要创建一个包含所有在某个时间范围内被访问过的文件列表的日志文件。
# 示例:创建一个包含所有在2023-01-01至2023-01-31之间被访问过的文件列表的日志文件
find /var/log -type f -newermt 2023-01-01 ! -newermt 2023-02-01 -exec ls -l {} \; 2> /dev/null > access_log.txt
在这个例子中, find 命令用来查找指定时间范围内被访问过的文件, -exec 参数用于对找到的每个文件执行 ls -l 命令来列出详细信息。 2> /dev/null 将错误信息丢弃, > access_log.txt 将 ls -l 的输出重定向到 access_log.txt 文件中。
5.3.2 性能优化与资源管理
结合使用管道和重定向不仅可以提高数据处理的效率,还可以优化系统资源的使用。合理利用重定向可以避免不必要的文件操作和磁盘I/O,而管道则可以减少进程的创建和销毁,提高数据处理速度。
flowchart LR
A["开始"] --> B["执行命令"]
B --> C["输出到 stdout"]
C -->|重定向| D["写入文件"]
C -->|管道| E["传递给下一个命令"]
E --> F["输出到 stdout"]
F -->|重定向| G["写入文件"]
G --> H["结束"]
在上图的Mermaid流程图中,展现了管道和重定向结合使用的基本流程,从命令的执行开始,数据流经过多个处理步骤,最终完成优化的资源管理和数据处理。
通过本章节的详细介绍,读者应该已经充分理解了管道和重定向的运作机制及其在数据处理中的应用,并且掌握了一些高级技巧。在Unix/Linux环境下,这些技能对于高效编程和系统管理是不可或缺的。随着进一步的实践应用,这些概念和技巧将能够为读者提供更加深入和实用的解决方案。
6. Shell函数与别名定义
在Unix/Linux系统中,Shell函数和别名是提高工作效率和简化日常任务处理的两大利器。这一章节将详细介绍如何定义和使用Shell函数、如何创建和管理别名,以及它们在实际工作中的应用。
6.1 Shell函数的定义和调用
Shell函数是脚本中的可重用代码块,通过定义函数,可以将重复使用的代码逻辑封装起来,简化脚本的结构,提高代码的可读性和可维护性。
6.1.1 函数定义的基本语法
定义Shell函数的基本语法如下:
function_name() {
# 函数体
echo "Function has been called"
}
或者使用关键字 function :
function function_name() {
# 函数体
echo "Function has been called"
}
一个具体的函数实例:
print_message() {
echo "Hello, World!"
}
# 调用函数
print_message
在上述示例中, print_message 是一个函数名,函数体内部执行了一个简单的 echo 命令,输出文本消息。调用时直接使用函数名加上括号。
6.1.2 函数参数和返回值的处理
函数可以接受参数,并且可以返回值。函数接收的参数通过位置参数 $1 , $2 , ... $n 来访问,其中 $1 是第一个参数, $n 是第n个参数。函数返回值通过 return 语句返回。
# 定义一个接受两个参数的函数
sum() {
local result=$(( $1 + $2 ))
echo $result
}
# 调用函数并传递参数
sum 5 10
# 输出:15
# 获取函数返回值
result=$(sum 5 10)
echo "The sum is: $result"
# 输出:The sum is: 15
函数返回值的使用可以在脚本中进行条件判断和流程控制。
6.2 别名的创建和管理
别名是一种在命令行中使用简单名称来替代一个长的或者复杂的命令行的方法,它可以提高工作效率,减少输入错误。
6.2.1 别名的作用和定义方式
定义别名的语法为:
alias name='command'
例如,将 ls -la 命令定义为别名 ll :
alias ll='ls -la'
定义之后,直接输入 ll 就可以执行 ls -la 命令的效果。
6.2.2 别名的高级应用和注意事项
别名非常灵活,可以用来定义复杂的命令序列。但请注意,别名只在当前shell会话有效。如果需要永久生效,可以将其添加到用户家目录下的 .bashrc 或 .bash_profile 文件中。
# 打开用户家目录下的.bashrc文件
nano ~/.bashrc
# 在文件中添加别名定义
alias ll='ls -la'
# 保存并退出文件,然后重新加载.bashrc文件
source ~/.bashrc
为了避免别名引起的意外,建议不要为常用命令如 cd 、 rm 定义别名。
6.3 函数和别名在实际工作中的应用
在日常工作中,合理地使用函数和别名可以使复杂的任务自动化,提高工作效率。
6.3.1 提升工作效率的脚本编写技巧
一个提高工作效率的技巧是在脚本中定义常用函数和别名。这样,在执行脚本时,可以快速调用这些已定义的函数和别名,执行重复性的任务。
6.3.2 维护和版本控制的最佳实践
对于经常需要修改和优化的函数和脚本,使用版本控制系统(如Git)进行跟踪和管理。将函数和脚本文件放在版本控制的仓库中,可以方便地管理变化,并且可以和其他开发者共享和协作。
# 初始化git仓库并提交初始脚本
git init
git add .
git commit -m 'Initial commit of utility scripts'
通过这些最佳实践,可以确保脚本和函数的更新和维护是有序和可控的。
在这一章节中,我们介绍了Shell函数和别名的定义、参数传递和返回值处理以及如何在实际工作中应用这些技术。这些技能不仅限于新开发人员,对于有经验的IT从业者也十分有帮助,特别是在优化现有工作流程和提高效率方面。通过深入理解并实践这些概念,您可以更快地执行任务,减少错误,为Unix/Linux环境中的高级编程打下坚实的基础。
简介:本书深入介绍Unix操作系统中的Shell编程,涵盖Unix基础和Shell脚本编写技巧。Shell作为Unix的命令解释器和自动化任务的关键工具,其编程语言虽简洁但功能强大,能处理文件操作、进程控制等复杂任务。本书包含从基础命令到高级话题的全面内容,为读者提供最原汁原味的技术内容和编程实践,无论是初学者还是有经验的用户都能提高对Unix系统和Shell编程的理解和应用。

















 885
885

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









