








一、问题
flink如果不限制日志文件大小,如果报错的情况下,会产生大文件日志。
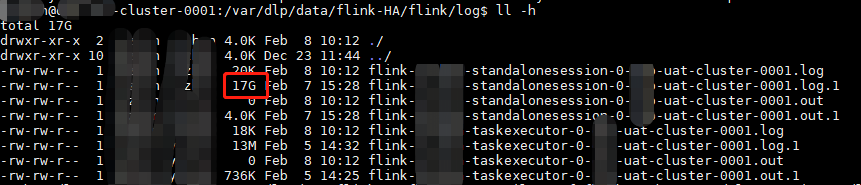
二、说明
Flink1.10.1
默认配置文件会将 JobManager 和 TaskManager 的日志分别打印在不同的文件中,每个文件的日志大小一直会增加.。
配置文件
- log4j-cli.properties: 由Flink命令行客户端使用(例如flink run)
- log4j-yarn-session.properties: 由Flink命令行启动YARN Session(yarn-session.sh)时使用
- log4j.properties: JobManager /Taskmanager日志(包括standalone和YARN)
Flink1.11.1
JobManager 和 TaskManager 日志输出在同一个文件中。
这两个版本,我们都可以对Flink日志做滚动的配置,控制每个日志文件的输出大小。
三、配置详情
jm 和 tm 上用的 log 配置都依赖于 flink/conf/log4j.properties 配置文件。
下面两个版本,将滚动日志设置为最大5m,最多10个文件。
Flink1.10.1
# 滚动日志配置
# This affects logging for both user code and Flink
log4j.rootLogger=INFO, R
# Uncomment this if you want to _only_ change Flink's logging
#log4j.logger.org.apache.flink=INFO
# The following lines keep the log level of common libraries/connectors on
# log level INFO. The root logger does not override this. You have to manually
# change the log levels here.
log4j.logger.akka=INFO
log4j.logger.org.apache.kafka=INFO
log4j.logger.org.apache.hadoop=INFO
log4j.logger.org.apache.zookeeper=INFO
log4j.appender.R=org.apache.log4j.RollingFileAppender
log4j.appender.R.File=${log.file}
log4j.appender.R.MaxFileSize=5MB
log4j.appender.R.Append=true
log4j.appender.R.MaxBackupIndex=10
log4j.appender.R.layout=org.apache.log4j.PatternLayout
log4j.appender.R.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} %t %-5p %-60c %x - %m%n
# Suppress the irrelevant (wrong) warnings from the Netty channel handler
log4j.logger.org.apache.flink.shaded.akka.org.jboss.netty.channel.DefaultChannelPipeline=ERROR, R
Flink1.11.1
# 滚动日志的配置
# This affects logging for both user code and Flink
rootLogger.level = DEBUG
rootLogger.appenderRef.rolling.ref = RollingFileAppender
# Uncomment this if you want to _only_ change Flink's logging
#logger.flink.name = org.apache.flink
#logger.flink.level = INFO
# The following lines keep the log level of common libraries/connectors on
# log level INFO. The root logger does not override this. You have to manually
# change the log levels here.
logger.akka.name = akka
logger.akka.level = INFO
logger.kafka.name= org.apache.kafka
logger.kafka.level = INFO
logger.hadoop.name = org.apache.hadoop
logger.hadoop.level = INFO
logger.zookeeper.name = org.apache.zookeeper
logger.zookeeper.level = INFO
# Log all infos in the given rolling file
appender.rolling.name = RollingFileAppender
appender.rolling.type = RollingFile
appender.rolling.append = false
#日志文件名
appender.rolling.fileName = ${sys:log.file}
#指定当发生文件滚动时,文件重命名规则
appender.rolling.filePattern = ${sys:log.file}.%i
appender.rolling.layout.type = PatternLayout
# 输出模板
appender.rolling.layout.pattern = %d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n
# 指定记录文件的保存策略,该策略主要是完成周期性的日志文件保存工作
appender.rolling.policies.type = Policies
# 基于日志文件大小的触发策略
appender.rolling.policies.size.type = SizeBasedTriggeringPolicy
# 当日志文件大小大于size指定的值时,触发滚动
appender.rolling.policies.size.size = 5MB
# 文件保存的覆盖策略
appender.rolling.strategy.type = DefaultRolloverStrategy
# 生成分割(保存)文件的个数,默认为5(-1,-2,-3,-4,-5)
appender.rolling.strategy.max = 10
# Suppress the irrelevant (wrong) warnings from the Netty channel handler
logger.netty.name = org.apache.flink.shaded.akka.org.jboss.netty.channel.DefaultChannelPipeline
logger.netty.level = OFF


















 1406
1406

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









