import pandas as pd
original_data = pd. read_excel( '19.新策略人群标注问卷数据_3030.xlsx' )
print ( original_data. columns. tolist( ) )
danxuan_list = [ '1.年龄' , '3.您购买的家具,是放在哪里?' , '4.购买家具时的决定人' , '5.购买家具的总费用/预算是(成品+定制)' ,
'6.购买的家具是成品还是定制' , '7.第几次购买家具' , '9.您放置家具的房子建筑面积是' , '10.您放置家具的户型是' ,
'11.您放置家具的房屋类型是' , '12.目前放置家具的房子,是您的第几次置业' , '13.您放置家具的房子,属于以下哪种情况' ,
'14.您家庭常住人口结构是' , '22.硬装软装顺序' , '24.客厅消费观' , '24.餐厅消费观' , '24.卧室消费观' , '24.儿童房消费观' ,
'24.书房消费观' , '24.阳台消费观' , '24.其他空间消费观' , '25.当您心仪的家具超出您的购买预算时' , '26.您平时的生活办公状态是' ,
'28.您家是否有(或希望有)专门的工作区域' , '30.经常有朋友来家中聚会吗' , '32.您日常在家吃饭的人数' ,
'33.您和家人在家做饭的频率是' , '38.您平均每天的睡眠时长是' , '39.您的睡眠质量' , '46.孩子几岁时(希望他)可以自己独立睡' ,
'47.孩子平均每天的睡眠时长是' , '48.您孩子的睡眠质量' , '49.您认为需要为孩子设置单独的儿童房吗' ,
'51.您希望儿童房的家具使用到哪个时候' , '54.您给孩子买的床垫的价格是' , '57.性别' , '58.职业' , '59.受教育程度' ]
original_data[ danxuan_list] . info( )
original_data[ '48.您孩子的睡眠质量' ] = original_data[ '48.您孩子的睡眠质量' ] . fillna( - 3 ) . astype( int )
def find_null ( x, q_list) :
if x[ q_list] . sum ( ) > 0 :
return True
else :
return False
tmall_list = [ 'Z世代' , '潮流租客' , '精致型男' , '轻奢熟女' , '城乡小资' , '小镇百姓' , '品质中产' , '实惠中年' ]
output_list = [ ]
for danxuanti in danxuan_list:
data = original_data. copy( )
data = data[ data[ danxuanti] >= 0 ]
q_list = pd. get_dummies( data[ [ danxuanti] ] , columns= [ danxuanti] ) . columns. tolist( )
print ( q_list)
data = pd. get_dummies( data, columns= [ danxuanti] )
data = data[ data. apply ( lambda x: find_null( x, q_list) , axis= 1 ) ]
data1 = data[ q_list+ [ '新策略人群划分' ] ]
df_list = [ ]
for i, renqun in enumerate ( tmall_list) :
renqun_df = data1[ data1[ '新策略人群划分' ] == renqun]
renqun_num = renqun_df. shape[ 0 ]
策略人群 = [ ]
选项 = [ ]
频数 = [ ]
人群数量 = [ ]
占比 = [ ]
for q in q_list:
q_num = renqun_df[ q] . sum ( )
zhanbi = q_num/ renqun_num
策略人群. append( renqun)
选项. append( q)
频数. append( q_num)
人群数量. append( renqun_num)
占比. append( zhanbi)
df_tmall= pd. DataFrame( zip ( 策略人群, 选项, 频数, 人群数量, 占比) , columns= [ '策略人群' , '选项' , '选项频数' , '策略人群数量' , '占比' ] )
df_tmall = df_tmall. sort_values( by= [ '占比' ] , ascending= False )
exec ( "df_{} = df_tmall" . format ( i) )
exec ( "df_list.append(df_{})" . format ( i) )
df1 = pd. concat( df_list, axis= 0 )
df1 = df1. reset_index( drop= True )
策略人群2 = [ ]
选项2 = [ ]
频数2 = [ ]
人群数量2 = [ ]
占比2 = [ ]
TGI2 = [ ]
total_num = data1. shape[ 0 ]
for q in q_list:
q_num2 = data1[ q] . sum ( )
zhanbi2 = q_num2/ total_num
策略人群2 . append( '总体' )
选项2 . append( q)
频数2 . append( q_num2)
人群数量2 . append( total_num)
占比2 . append( zhanbi2)
TGI2. append( 100 )
df_zongti= pd. DataFrame( zip ( 策略人群2 , 选项2 , 频数2 , 人群数量2 , 占比2 , TGI2) , columns= [ '策略人群' , '选项' , '选项频数' , '策略人群数量' , '占比' , 'TGI' ] )
df_zongti = df_zongti. sort_values( by= [ '占比' ] , ascending= False )
df_zongti = df_zongti. reset_index( drop= True )
def calculate_tgi ( x) :
zongti_zhanbi = df_zongti[ df_zongti[ '选项' ] == x[ '选项' ] ] [ '占比' ]
tgi = round ( x[ '占比' ] / ( zongti_zhanbi) , 2 ) * 100
return tgi. values[ 0 ]
df1[ 'TGI' ] = df1. apply ( lambda x: calculate_tgi( x) , axis= 1 )
output = pd. concat( [ df1, df_zongti] )
output = output. reset_index( drop= True )
output_list. append( output)
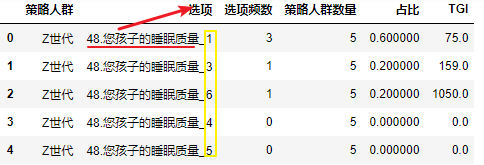
output_list[ 0 ]
def keep_last_num ( x) :
index_ = x. index( '_' )
return x[ index_+ 1 : ]
for o in output_list:
title = o[ '选项' ] [ 0 ] [ : - 2 ]
o[ '选项' ] = o[ '选项' ] . apply ( lambda x: keep_last_num( x) )
o. rename( columns= { '选项' : title} , inplace= True )
dict_data = pd. read_excel( '单选题索引转选项字符串字典.xlsx' )
for o in output_list:
option_string_list = dict_data[ o. columns[ 1 ] ] . dropna( ) . tolist( )
option_index_list = [ str ( x+ 1 ) for x in range ( len ( option_string_list) ) ]
o[ o. columns[ 1 ] ] = o[ o. columns[ 1 ] ] . replace( option_index_list, option_string_list)
output_list[ 0 ]
with pd. ExcelWriter( '单选统计分析结果.xlsx' ) as writer:
for o in output_list:
df_name = o. columns[ 1 ] . replace( '/' , '' ) . replace( '?' , '' )
o. to_excel( writer, sheet_name= df_name, index= False )








 这篇博客介绍了一种方法,通过Python处理问卷数据,特别是针对单选题,计算占比、频数和TGI指标。首先导入数据并检查数据格式,接着处理非整数列,定义函数筛选有效样本,然后进行主程序分析,预览特定问题结果,重命名选项并转换为数字索引,最后批量导出每题分析到单独的Excel工作表。
这篇博客介绍了一种方法,通过Python处理问卷数据,特别是针对单选题,计算占比、频数和TGI指标。首先导入数据并检查数据格式,接着处理非整数列,定义函数筛选有效样本,然后进行主程序分析,预览特定问题结果,重命名选项并转换为数字索引,最后批量导出每题分析到单独的Excel工作表。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









