







 本文介绍了Python中的Numpy库,包括查看数组元素、数据类型、切片、生成数组、矩阵运算等基本操作。同时,也探讨了Pandas的DataFrame和Series,讲解了读写文件、数据合并及描述性统计等核心概念。
本文介绍了Python中的Numpy库,包括查看数组元素、数据类型、切片、生成数组、矩阵运算等基本操作。同时,也探讨了Pandas的DataFrame和Series,讲解了读写文件、数据合并及描述性统计等核心概念。
numpy核心数据类型是 ndarray 底层语言是C
pandas中的DataFrame 和Series 也是基于ndarray

如何看一个array的形状:array.shape 或者是 np.shape(array_object)

2行8列
查看array对象有多少个元素

numpy数组与list的区别在于:list可以放不同类型的元素str,int,float都能同时放入,而nparray只能放同一个类型的元素。
查看nparray里元素的数据类型

修改array中的某个元素

实战中,要导入导出数据时要规范数据类型,就要传入dtype参数

对array数组进行切取操作 [x:y , a:b]

要注意的是如果修改了b里面的值,a所对应的元素也会改变
生成array


单位矩阵(identity-matrix,unit-matrix)只有主对角线上有值:1

随机生成数的矩阵,数值都在0~1之间


index运用技巧


这样修改b是不会影响a的
布尔值掩码 mask ,贴标签:用来筛选


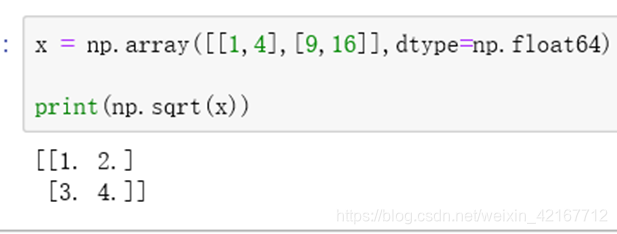
矩阵相加,开方

矩阵点乘dot
#不需要调包
x.dot(y)
# 利用numpy
np.dot(x,y)
矩阵里的元素求和
对矩阵里的所有元素求和
x = np.array([[1,2],[3,4]])
print(x.sum())
得到 10
对矩阵里的每列求和
x = np.array([[1,2],[3,4]])
print(x)
print(np.sum(x,axis=0))
[[1 2]
[3 4]]
[4 6]
矩阵的转置
x = np.array([[1,2],[3,4]])
print(x.T)
矩阵广播boardcasting(传播/扩散)
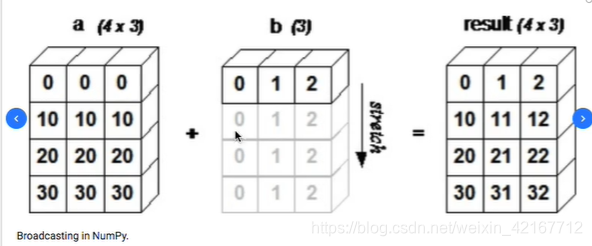
简单理解是两个矩阵/一个矩阵跟一个数字进行加减乘除
形状较小的那个矩阵/一个数会变成(脑补成)较大的那个矩阵的形状,然后运算。
x = np.array([[1,2],[3,4],[5,6]])
print(x)
y = np.array([10,10])
print(x+y)
[[1 2]
[3 4]
[5 6]]
↓
[[11 12]
[13 14]
[15 16]]
按照某个array的形状生成形状相同,但是值不同的array
x = np.array([[1,2],[3,4],[5,6]])
z = np.empty_like(x)
z = np.ones_like(x) # 生成的array元素都是1
z = np.zeros_like(x) # 生成的array元素都是0
pandas 显示设置
pd.set_option('display.max_columns',1000)# 设置成能看1000列
pd.set_option('display.max_rows',1000) # 设置成能看1000行
指定header=None(有时候没有列名)
这样设置后,列名会变成0,1,2,3,4,5…
import pandas from pd
data = pd.read_csv('data_file_location',header=None)
读取文件的时候,批量指定列名
new_cols = ['f1','f2','f3'....]
data = pd.read_csv('data_file_location',names = new_cols, header=None)
不建议使用dataframe.feature这种形式获取series
df['feature_name']
df.feature_name #不建议,因为数字,空格,专用词,都会对获取series产生影响
两个series 相加
new_series = df['series1']+df['series2']
相加的两列如果是数字,相加后得到的series还是数字
相加的两列如果是字符串,相加后字符串就粘合在一起
还可以数字跟字符串相加,生成的新对象是字符串格式
将新的series加入到dataframe中
df['new_series'] = df['series1']+df['series2']
拿到数据后总体描述
data.describe()

















 3245
3245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









