






 本文介绍如何使用Python爬虫从知乎话题主页抓取精华回答的问题URL,并详细阐述了爬虫的四个步骤:获取回答问题URL、筛选热门问题、爬取热门问题回答及作者信息、获取作者详细资料。通过分析xhr请求,构造动态加载的URL,利用循环爬取并解析JSON数据,最终将数据存入数据库。
本文介绍如何使用Python爬虫从知乎话题主页抓取精华回答的问题URL,并详细阐述了爬虫的四个步骤:获取回答问题URL、筛选热门问题、爬取热门问题回答及作者信息、获取作者详细资料。通过分析xhr请求,构造动态加载的URL,利用循环爬取并解析JSON数据,最终将数据存入数据库。
爬虫目标
本次爬虫需要从知乎的话题精华回答中爬取前1000个回答的问题。然后得到关注数最多的100个问题的url后,到问题主页把问题下的50%的回答内容和作者信息爬取下来。
本次爬虫主要分为四部分:
1.爬取精华回答页面,获取每个回答对应的问题的url。
2.爬取上一步的问题页面获取问题的关注人数、评论数,用来选择最热门问题。
3.爬取热门问题主页的前50%回答内容、回答获得的赞同数、回答时间、回答作者的url等。
4.到作者主页获得回答的作者的一些信息,如,获赞量、评论量、关注人数等。
为方便阅读,本篇讲解第一部分
知乎话题主页数据爬虫
需要用到的包
from urllib.parse import urlencode
import requests
import pymysql
前期准备,base_url是动态加载数据的url的前面不变的部分。在知乎话题主页鼠标右键–>检查(或者Fn+F12)。选择文件类型XHR,查看通过Ajax加载的文件。然后向下滑动时我们看到不断加载出来的文件。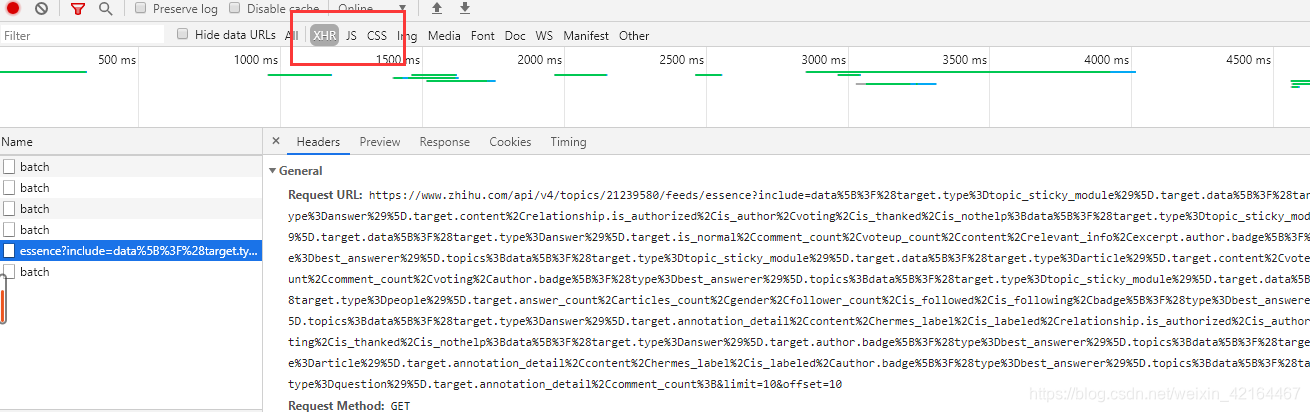
这类文件的格式通常是这样的,我们后面从这个文件中获取数据,需要分析这个结构。
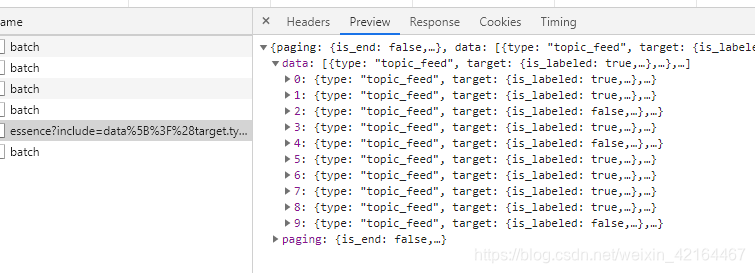
回到,数据包的首部信息。我们需要分析下这个URL的结构。主要是第一部分红色固定部分加上三个量。
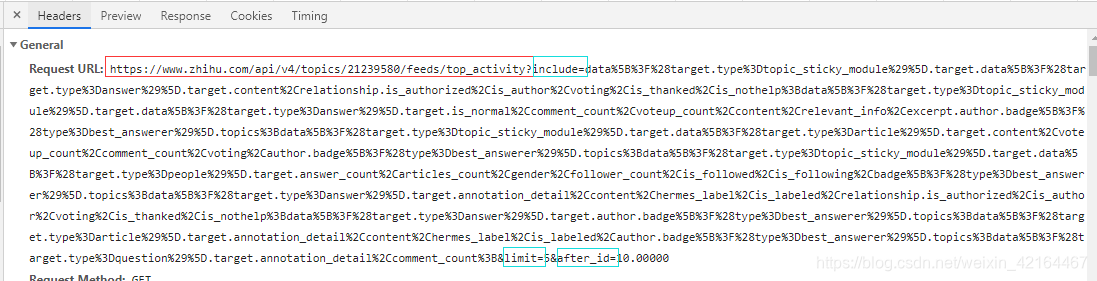
鼠标下滑观察三个量的具体变化情况。
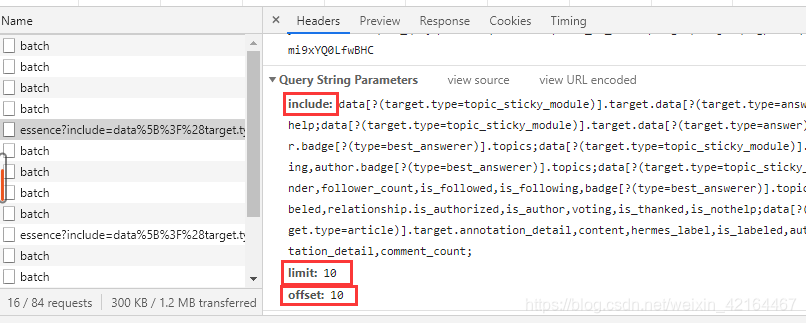
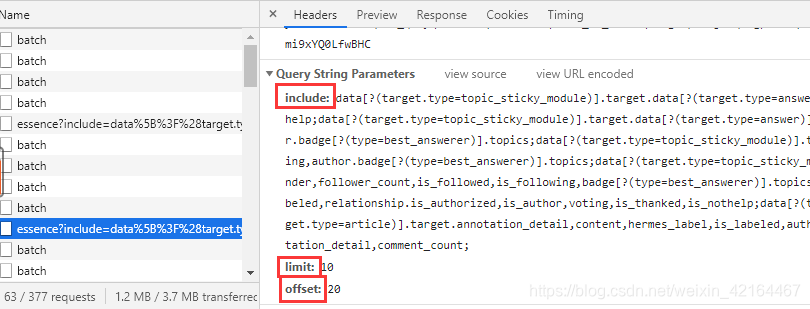
可以发现include、limit是定量,offset递增,每次加10.
然后我们就可以构造爬虫的url了!
base_url就是不变的部分,params字典里将offset设置为变量,offset作为算法的输入参数,借助循环就可以爬取所有的json文件了。
base_url = 'https://www.zhihu.com/api/v4/topics/21239580/feeds/essence?'
#数据包的头部信息完整不容易被反爬
headers = {
'referer': 'https://www.zhihu.com/topic/21239580/top-answers',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
'X-Requested-With': 'fetch',
'cookie':'_zap=dcef10ed-ac5b-47d7-be62-ce15422c243b; d_c0="AEAoweBBYw6PTtM5YdeXEGe9nkFjo1fukEs=|1539959215"; _xsrf=JfK6LMdyHsAQfznzKy9qqzVa1hGVudzX; __utmv=51854390.100--|2=registration_date=20171205=1^3=entry_date=20171205=1; _ga=GA1.2.231820689.1558959113; r_cap_id="MGNkZWRhYzBiMWEyNDUwYmI2ZmNhMWJlZTRmODJhYTY=|1584438632|0ffe2fcf055c73a9876c18c6f60dabbc0df9734b"; cap_id="YzhmN2M2NTdlOTFjNDJlZGFiYTFlNTQ4ZDVmOTRiOWI=|1584438632|ddc44638cf41bcea0634c664cfdc27f767ae79e7"; l_cap_id="ZWUwNTAzYWU1ZGExNDkyYmI4OWI3YzJmOGNlMTg3MzY=|1584438632|655548f26f77e6e254e52f4db91cbf340e699522"; tshl=; tst=r; q_c1=0ec4457e6f67420da14808f4ba874ab9|1586094208000|1539959216000; Hm_lvt_98beee57fd2ef70ccdd5ca52b9740c49=1584686926,1586092328,1586092679,1586309558; _gid=GA1.2.1489756283.1586309558; SESSIONID=vDYbvehGoVHeVUZQN9SUcsRPETOrwazMaLXnvmygBoV; JOID=U1AWAk1pmUkj11LRd2mXl5sPqTBlFtYSRqY-sjIBxgpEhgCCLdK5wX3ZUNhyUVORLtzYaDRq1-uGYkTGUyyTIJE=; osd=UlocAk1ok0Mj11PbfWmXlpEFqTBkHNwSRqc0uDIBxwBOhgCDJ9i5wXzTWthyUFmbLtzZYj5q1-qMaETGUiaZIJE=; capsion_ticket="2|1:0|10:1586309956|14:capsion_ticket|44:NTkzNDk3ZTU2MWU0NDM0ZGJhYmZkNjY5MGU3NDFiNTM=|aff74864db3420505f145e142e16a742ff658f23b7398b9c05d19ac57fa487a0"; z_c0="2|1:0|10:1586309963|4:z_c0|92:Mi4xWUVERUJnQUFBQUFBUUNqQjRFRmpEaVlBQUFCZ0FsVk5TM2w2WHdBd1RPd3p1bWRNTGRONmdNQXJWczlDZjVVVXR3|ebc6875dd9b03e62598afe37b2ee420f4d30578822a588ce82e93adb2b0732fe"; __utmc=51854390; __utma=51854390.231820689.1558959113.1586311624.1586315592.5; __utmz=51854390.1586315592.5.3.utmcsr=zhihu.com|utmccn=(referral)|utmcmd=referral|utmcct=/question/377935555; Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49=1586329609; _gat_gtag_UA_149949619_1=1; KLBRSID=2177cbf908056c6654e972f5ddc96dc2|1586329618|1586319827',
}
#获取动态加载的json文件
def get_page(offset):
params = {
'include':'data[?(target.type=topic_sticky_module)].target.data[?(target.type=answer)].target.content,relationship.is_authorized,is_author,voting,is_thanked,is_nothelp;data[?(target.type=topic_sticky_module)].target.data[?(target.type=answer)].target.is_normal,comment_count,voteup_count,content,relevant_info,excerpt.author.badge[?(type=best_answerer)].topics;data[?(target.type=topic_sticky_module)].target.data[?(target.type=article)].target.content,voteup_count,comment_count,voting,author.badge[?(type=best_answerer)].topics;data[?(target.type=topic_sticky_module)].target.data[?(target.type=people)].target.answer_count,articles_count,gender,follower_count,is_followed,is_following,badge[?(type=best_answerer)].topics;data[?(target.type=answer)].target.annotation_detail,content,hermes_label,is_labeled,relationship.is_authorized,is_author,voting,is_thanked,is_nothelp;data[?(target.type=answer)].target.author.badge[?(type=best_answerer)].topics;data[?(target.type=article)].target.annotation_detail,content,hermes_label,is_labeled,author.badge[?(type=best_answerer)].topics;data[?(target.type=question)].target.annotation_detail,comment_count;',
'limit': 10,
'offset': offset #offset是一个变量
}
url = base_url + urlencode(params)
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.json()
except requests.ConnectionError as e:
print('Error', e.args)
获得了json文件,接下来提取我们需要的字段
这时候我们就需要分析下文件的结构了,我们要获得question信息需要经过这几个目录。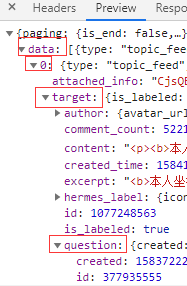
然后,在代码中实现的时候获取json格式的文件数据直接json[‘data’],然后需要什么就写到哪层就可以了。但是万一遇到格式不统一的情况可能出错。这时自己根据自己的情况看这个格式不一致的数据重不重要。在这里,我直接忽略了,因为知乎中不存在question这个字段的也不是回答,所以对我们没有意义。
#获取json文件中的数据的时候要分析json文件的数据结构
def parse_page(json):
if json:
# 连接数据库
conn = pymysql.connect(host='localhost', user='root', password='密码', database='数据库名', port=3306)
cursor = conn.cursor()
#获得一组数据,遍历一组中的问题信息
items = json['data']
num=[0,1,2,3,4,5,6,7,8,9]
for i in num:
try:
item = items[i]['target']['question']
urlid = item['id']
title = item['title']
voteup = items[i]['target']['voteup_count']
i = i + 1
except KeyError as e:
i = i + 1
continue #这里如果出错没有处理,把I加一继续运行是因为,在json文件中有些item里缺少question字段。
print(i)
print(title)
# 插入数据到数据库里
sql = """
insert into 表名(id,title,url,voteup) values(null,%s,%s,%s)
"""
title=title
url="https://www.zhihu.com/question/"+str(urlid)
voteup=voteup
cursor.execute(sql, (title, url, voteup))
conn.commit()
conn.close()
最后我们利用循环实现批量数据爬取。
if __name__ == '__main__':
for offset in range(10,1005,10):
print('+'*30)
print(offset)
json = get_page(offset)
parse_page(json)
range函数参数含义
range(初始值,范围,迭代增量)
10是包含的,1005不包含
最后就得到了1000个精华回答的相关问题的数据了。哦耶。
在Navicat Premium数据库工具中查看数据是否插入。成功。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









