







说明:如需数据可以直接到文章最后关注获取。
1.数据背景
数据集是机器学习和数据分析领域中另一个广泛使用的经典数据集。此数据集来源于意大利的三个不同产区的葡萄酒样本,目标是通过分析葡萄酒的化学成分来分类其所属的产区。该数据集是一个多分类问题,适用于分类算法的研究和评估。
数据集最初由 Forina 等人收集,并被广泛用于模式识别和机器学习的研究。该数据集包含来自三个不同产区的葡萄酒样本,每个样本都有多个化学成分的测量值。数据集的目标是根据这些化学成分,将葡萄酒分类到正确的产区。
数据集的应用场景-数据集广泛应用于以下几个领域:
1)分类模型评估:该数据集常用于评估分类算法的性能,尤其是多分类问题。常见的机器学习算法包括逻辑回归、支持向量机、随机森林分类、K近邻(KNN)、XGBoost 分类等。
2)特征选择与降维:数据集中的一些特征之间存在较强的关联性,因此该数据集非常适合用于特征选择和降维技术的研究。例如,可以使用主成分分析(PCA)、Lasso 回归、递归特征消除(RFE)等方法来选择最重要的特征,从而提高模型的性能。
3)不平衡数据处理:虽然该数据集的类别分布相对均衡,但在实际应用中,如果某些类别的样本数量较少,仍然可以使用不平衡数据处理技术来优化模型的性能。常见的方法包括过采样(如 SMOTE)、欠采样、加权损失函数等。
4)业务优化:该数据集可以帮助葡萄酒生产商优化生产过程。通过分析哪些化学成分对葡萄酒产地有显著影响,生产商可以调整生产工艺,确保葡萄酒的质量和风味符合特定产区的标准。
数据集是一个经典的机器学习数据集,广泛应用于分类任务、特征选择、降维技术等领域。该数据集提供了丰富的葡萄酒化学成分信息,涵盖酒精含量、马来酸、灰分、总酚类物质、黄烷类物质、非黄烷类酚类物质、原花青素、色度、色调、光学密度比值和脯氨酸等多个特征。尽管数据集存在一些局限性,但它仍然是一个非常有价值的研究工具,尤其适合初学者和研究人员进行实践和探索。
2.数据介绍
数据格式为csv格式。
| 编号 | 变量名称 | 描述 |
| 1 | Alcohol | 酒精含量,单位为百分比(%) |
| 2 | Malicacid | 马来酸含量,单位为 g/l |
| 3 | Ash | 灰分含量,单位为 g/l |
| 4 | Alcalinity_of_ash | 灰分的碱度,单位为 mg/l |
| 5 | Magnesium | 镁含量,单位为 mg/l |
| 6 | Total_phenols | 总酚类物质含量,单位为 mg/l |
| 7 | Flavanoids | 黄烷类物质含量,单位为 mg/l |
| 8 | Nonflavanoid_phenols | 非黄烷类酚类物质含量,单位为 mg/l |
| 9 | Proanthocyanins | 原花青素含量,单位为 mg/l |
| 10 | Color_intensity | 色度,表示葡萄酒的颜色深浅 |
| 11 | Hue | 色调,表示葡萄酒的颜色色调 |
| 12 | 0D280_0D315_of_diluted_wines | 稀释葡萄酒在280nm和315nm波长下的光学密度比值 |
| 13 | Proline | 脯氨酸含量,单位为 mg/l |
| 14 | y | 葡萄酒所属的产区,取值为1、2或3,分别对应Barolo、Grignolino和Barbera产区 |
数据详情如下(部分展示):
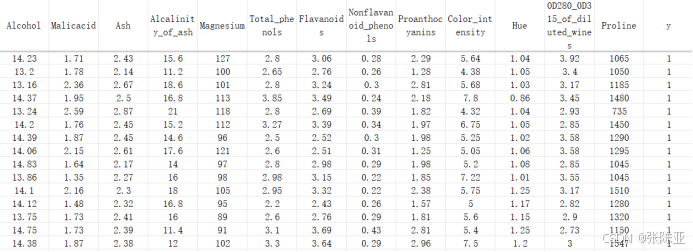
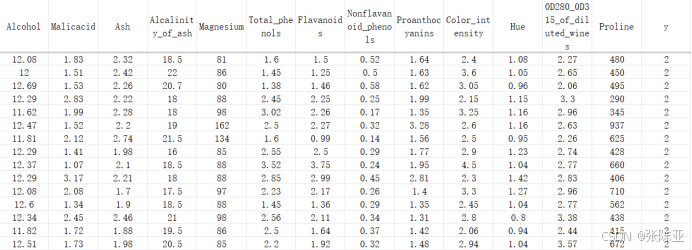
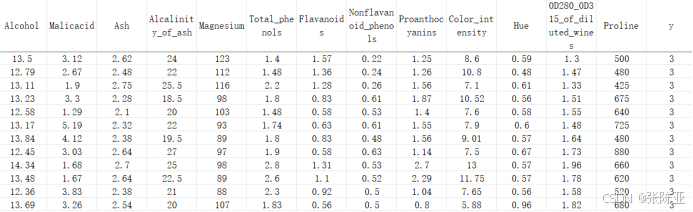
3.数据获取
关注下方 回复1010,获取。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











