







 本文详细介绍了如何使用Scrapy框架搭建一个web抓取项目。从新建虚拟环境开始,到使用清华大学镜像加速安装Scrapy,再到PyCharm中创建项目和爬虫文件夹的全过程。适合初学者快速上手。
本文详细介绍了如何使用Scrapy框架搭建一个web抓取项目。从新建虚拟环境开始,到使用清华大学镜像加速安装Scrapy,再到PyCharm中创建项目和爬虫文件夹的全过程。适合初学者快速上手。
scrapy是一个快速、高层次的web抓取框架
-
新建虚拟环境
具体解释看上一篇推文,
输入: >mkvirtualenv -p /usr/bin/python3 Articlespider

-
安装scrapy
可以直接使用:>pip install scrapy下载,但是速度比较慢
也可以寻找镜像下载(我这里用的清华大学的):>pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scrapy
安装如果提示: Failed building wheel for xxx
可以在 https://www.lfd.uci.edu/~gohlke/pythonlibs/#lxml 找到对应的安装包进行安装 -
在pycharm中新建scrapy项目
在Documents中新建一个文件夹scrapy,在命令行中进入scrapy文件夹:>cd /home/ailiya/Documents/scrapy
在文件夹中建立scrapy项目:>scrapy startproject Articlespider
进入项目:>cd Articlespider -
在pycharm中导入Articlespider
file->new project->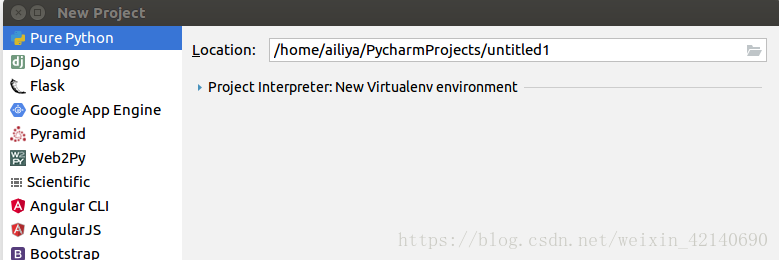
在location中填写Articlespider的位置打开:
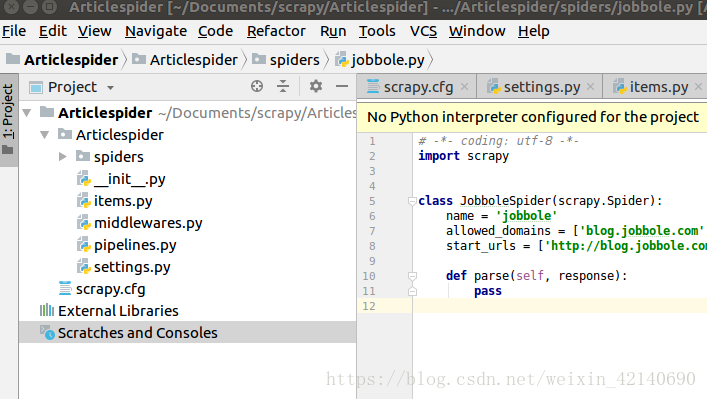
-
创建爬虫文件夹
在命令行中输入:>scrapy genspider jobbole blog.jobbole.com(爬虫的网站)
打开pycharm,可以看到文件夹创建成功
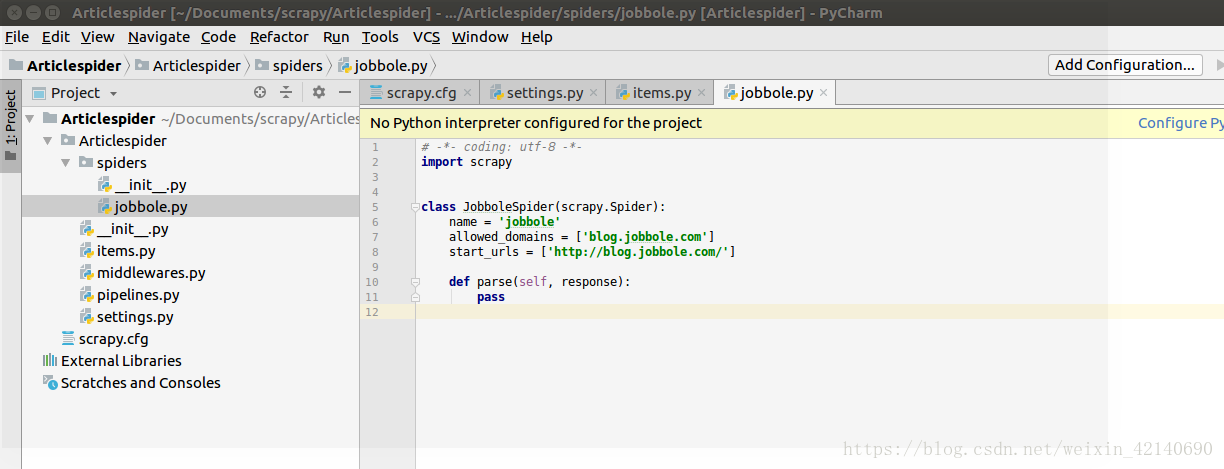

















 800
800

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









