







目录
-
CPU和GPU

其中绿色的是计算单元,橙红色的是存储单元,橙黄色的是控制单元。
-
什么样的任务适合GPU?
- 计算密集型的程序。
- 易于并行的程序。GPU其实是一种SIMD(Single Instruction Multiple Data)架构。
-
内存模型以及硬件
Device对应为GPU,Host对应CPU,Kernel对应GPU上运行的函数。
内存模型
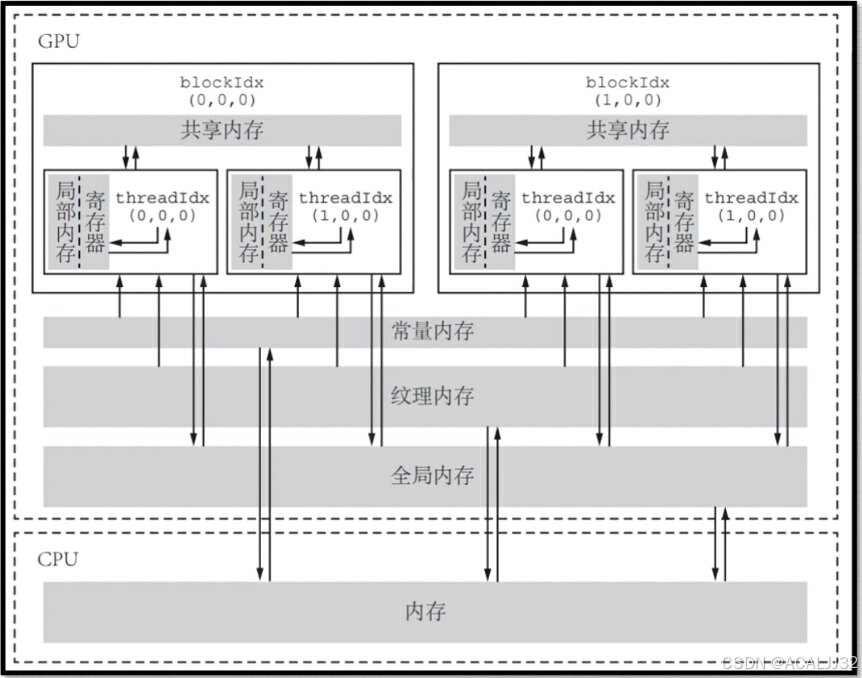

- 寄存器
(1)寄存器访问最快。仅在线程内可见。核函数中不加任何限定符的变量一般存放在寄存器中。
(2)内建变量一般存放在寄存器中,如gridDim,blockDim,blockIdx等。
(3)核函数中定义的不加任何限定符的数组可能在寄存器中,也可能在本地内存中。
(4)寄存器溢出:核函数需要的寄存器数量超过硬件支持后,会存放在本地内存。单个线程运行所需要的寄存器数量为255。
- 全局内存
(1)全局内存中的数据所有线程可见,Host端也可见,具有与程序相同的生命周期。
(2)动态初始化(动态全局内存):cudaMalloc动态申请。静态全局内存:使用__device__关键字声明的静态全局内存。__device__定义的变量不可以放在核函数中,也不可以放在host端的函数中,如:
__device__ int d_x = 1;
__device__ int d_y[2];
__global__ void kernel()
{
d_y[0] += d_x;
d_y[1] += d_x;
}- 共享内存
(1)线程块内所有线程可见。生命周期也与线程块一致。
(2)__shared__修饰的变量放入共享内存中。共享内存也分为动态和静态两种。
(3)访问共享内存必须有同步机制,线程块内同步 void __syncthreads();
(4)静态共享内存声明:__shared__ float size[size, size]; 静态共享内存作用域:(a)在核函数中声明,作用域就近限于这个核函数内;(b)文件核函数外声明,静态共享作用域对所有核函数有效。静态共享内存在编译时就要确定大小。
(5)动态共享内存:extern __shared__ float s_array[]; 这里,不可以写成extern __shared__ float *s_array[],同时,必须要有extern关键字。
在执行核函数时,需要指定动态共享内存大小,如同下边演示,指定动态共享内存大小为32。
dim block(32);
dim grid(2);
kernel_1<<<grid, block, 32>>>();- 常量内存
(1)常量缓存的全局内存。大小有限,只有64KB,访问比全局内存快。
(2)常量内存对同一编译单元内的所有线程可见。
(3)__constant__ 修饰的变量存放于常量内存中,不可以定义核函数中,且常量内存是静态编译的。
(4)常量内存仅仅可读。
(5)给核函数传递参数时,这个变量就存放在常量内存。
(6)常量内存在主机端使用,必须使用cudaMemcpyToSymbol初始化。
__constant__ float c_data;
__constant__ float c_data2 = 6.6f;
__global__ void kernel_1(void)
{
// Your code ...
}
int main()
{
int devID = 0;
cudaDeviceProp deviceProps;
CUDA_CHECK(cudaGetDeviceProperties(&deviceProps, devID));
std::cout << "运行设备:" << deviceProps.name << std::endl;
float h_data = 8.8f;
CUDA_CHECK(cudaMemcpyToSymbol(c_data, &h_data, sizof(float)));
dim3 block(1);
dim3 grid(1);
kernel_1<<<grid, block>>>();
CUDA_CHECK(cudaDeviceSynchronize());
// 获取常量内存的内容
CUDA_CHECK(cudaMemcpyFromSymbol(&h_data, c_data2, sizeof(float)));
CUDA_CHECK(cudaDeviceReset());
return 0;
}
- GPU缓存
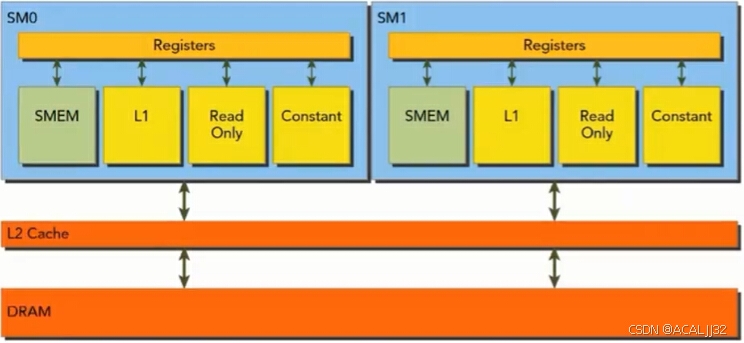
(1)GPU缓存都是不可编程的内存。
(2)每个SM都有一个一级缓存,所有SM共享一个二级缓存。
(3)L1缓存和L2缓存存储本地内存(local memory)和全局内存(global memory)数据,也包含寄存器溢出的部分。读取DRAM必须经过L2缓存。
(4)在GPU上只有内存加载可以被缓存,内存存储操作不可以被缓存。
(5)每个SM有一个只读常量缓存和只读纹理缓存。
(6)GPU全局内存是否支持L1缓存查询指令:
cudaDeviceProp::globalL1CacheSupported(7)默认情况下,数据不会缓存在统一的L1 / 纹理缓存,但可以通过编译指令启动:
开启: -Xptxas -dlcm=ca ; 除了带有禁用缓存修饰符的内联汇编修饰的数据外,所有读取数据都将被缓存。
开始:-Xptxas -fscm=ca ; 所有数据都将被缓存。
#include <stdio.h>
#include <iostream>
#include <cuda_runtime.h>
int main()
{
int devID = 0;
cudaDeviceProp deviceProps;
cudaGetDeviceProperties(&deviceProps, devID);
std::cout << "运行GPU设备: " << deviceProps.name << std::endl;
// If Support L1 Cache
if(deviceProps.globalL1CacheSupported) {
std::cout << "Global L1 Cache supported!" << std::endl;
} else {
std::cout << "Global L1 Cache not supported!" << std::endl;
}
std::cout << "Finished! \n";
return 0;
}CMakeLists.txt :
cmake_minimum_required(VERSION 3.10)
project(INFO_CHECK LANGUAGES CXX CUDA)
add_definitions(-std=c++11)
option(CUDA_USE_STATIC_CUDA_RUNTIME OFF)
set(CMAKE_CXX_STANDARD 11)
set(CMAKE_CUDA_STANDARD 11)
set(CMAKE_BUILD_TYPE Debug)
set(EXECUTABLE_OUTPUT_PATH ${PROJECT_SOURCE_DIR}/build)
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -std=c++11 -Wall -O0 -Wfatal-errors -pthread -w -g")
set(CMAKE_CUDA_FLAGS "${CMAKE_CUDA_FLAGS} -O3 -arch=sm_86 -Xptxas -dlcm=ca")
find_package(CUDA REQUIRED)
if (CUDA_FOUND)
message(STATUS "Found CUDA ${CUDA_VERSION_STRING} at ${CUDA_TOOLKIT_ROOT_DIR}")
else()
message(FATAL_ERROR "Cannot find CUDA.")
endif()
add_executable(GPU_Cache main.cu)
target_include_directories(GPU_Cache PRIVATE ${CUDA_INCLUDE_DIRS})
target_link_libraries(GPU_Cache PRIVATE ${CUDA_LIBRARIES})![]()
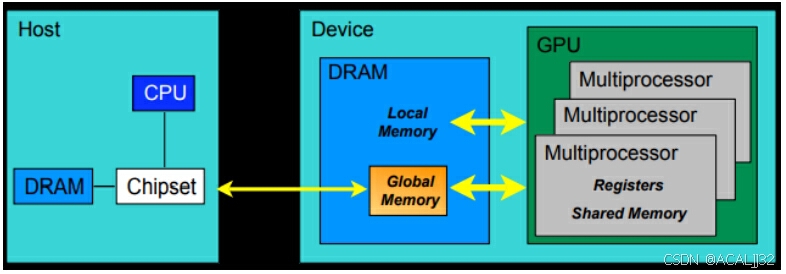
- 每个线程处理器(SP)都有自己的寄存器
- 每个SP都有自己的local memory(局部内存),寄存器和local memory只可以被自己的线程访问。
- 每个多核处理器都有自己的shared memory(共享内存),shared memory 可以被线程块内所有线程访问。
- 一个GPU所有的SM有一块global memory(全局内存),不同线程块都可以使用。
- 层次划分:
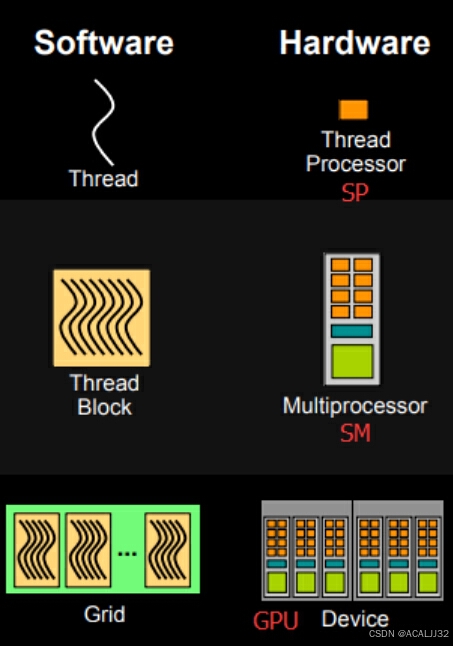
线程处理器SP => 线程,多核处理器SM => 线程块(thread block),设备端 => 线程块组合(Grid)。
CUDA中的Grid与Block
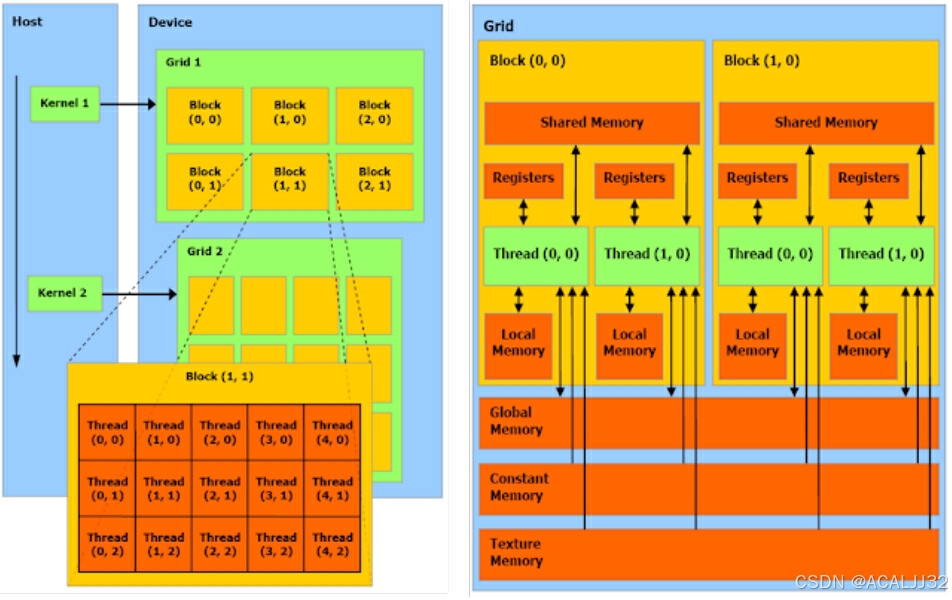
- 一个kernel由一个Grid来执行。
- 一个kernel一次只可以在一个GPU上执行。
线程束

-
SM采用的SIMT(Single-Instruction, Multiple-Thread,单指令多线程)架构,warp(线程束)是最基本的执行单元,一个 warp包含32个并行thread,这些thread以不同数据资源执行相同的指令。warp本质上是线程在GPU上运行的最小单元。
-
当一个kernel被执行时,grid中的线程块被分配到SM上,一个线程块的thread只能在一个SM上调度,SM一般可以调度多个线程块,大量的thread可能被分到不同的SM上。每个thread拥有它自己的程序计数器和状态寄存器,并且用该线程自己的数据执行指令,这就是所谓的Single Instruction Multiple Thread(SIMT)。
-
由于warp的大小为32,所以block所含的thread的大小一般要设置为32的倍数。
SM
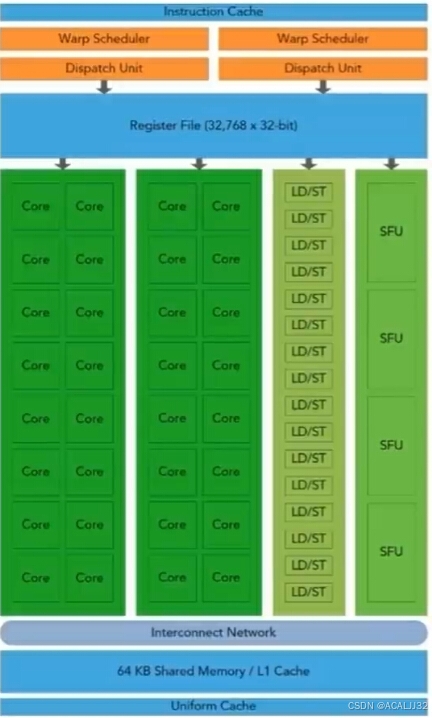
- 以上就是Fermi架构SM,主要资源构成:
1. CUDA Core
2. 共享内存 / L1缓存
3. 寄存器文件
4. 加载和存储单元(Load / Store Unit)
5. 特殊函数单元
6. Warps 调度器
- GPU中每个SM都支持数百个线程并发执行
- 以线程块block为单位,向SM分配线程块,多个线程块可以被用到一个SM上
- 一个线程块被分配到SM上以后,就不可以分配到其他SM上
- 线程块被分配到SM中以后,会以32个线程为一组进行分割,每个组组成一个warp。
cudaDeviceSynchronize
cpu和gpu同步执行,因为kernel的执行默认是异步的,需要强制让kernel函数执行结束后,host再执行。
CUDA Stream
- CUDA Stream是GPU Task的执行队列,所有CUDA操作(kernel,内存拷贝)都在stream上执行。
- CUDA stream默认有两种流:隐式流和显示流,默认在隐式流中计算。隐式流里的GPU Task和CPU是同步的。显示流式异步的,不同显示流的GPU Task也是异步的。
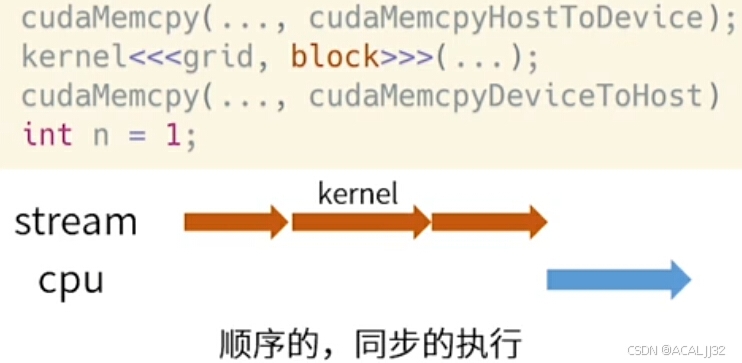

============================== 接口说明 ==============================
// 定义
cudaStream_t stream;
// 创建
cudaStreamCreate(&stream);
// 数据传输
cudaMemcpyAsync(dst, src, size, type, stream);
// kernel在流中执行
kernel_name<<<grid, block, sharedMemSize, stream>>>(arglist);
// sharedMemSize, 动态shared memory 大小,如果用到动态的需要去申请。
// 同步和查询
cudaError_t cudaStreamSynchronize(cudaStream_t stream);
cudaError_t cudaStreamQuery(cudaStream_t stream);
// 销毁
cudaError_t cudaStreamDestroy(cudaStream_t stream);
- cuda stream demo
// 创建2个流
cudaStream_t stream[2];
for(int i = 0; i < 2; i++)
cudaStreamCreate(&stream[i]);
float *hostPtr;
cudaMallocHost(&hostPtr, 2 * size);
// 两个流,每个流有三个命令
for(int i = 0; i < 2; i++) {
cudaMemcpyAsync(inputPtr + i * size, hostPtr + i * size, size, cudaMemcpyHostToDevice, stream[i]);
MyKernel<<<grid, block, 0, stream[i]>>>(outputDevPtr + i * size, inputDevPtr + i * size, size);
cudaMemcpyAsync(hostPtr + i * size, outputDevPtr + i * size, size, cudaMemcpyDeviceToHost, stream[i]);
}
// 同步流
for(int i = 0; i < 2; i++)
cudaStreamSynchronize(stream[i]);
// 销毁流
for(int i = 0; i < 2; i++)
cudaStreamDestroy(stream[i]);- stream优点:CPU计算和kernel计算并行,CPU计算和数据传输并行,输出传输和kernel计算并行,kernel计算并行。
- cudaStreamSynchronize() 用来同步一个流。
- cudaDeviceSynchronize() 同步该设备上的所有流。
- cuda默认流的表现
- 假如编译命令:
nvcc ./stream_test.cu -o stream_legacy则执行情况如下:

为什么不是并行执行?因为单线程内,默认流的执行是同步的,显示流的执行是异步的!
- 如果编译命令为:
nvcc --default-stream per-thread ./stream_test.cu -o stream_per-thread
// 默认流和显示流的执行是异步的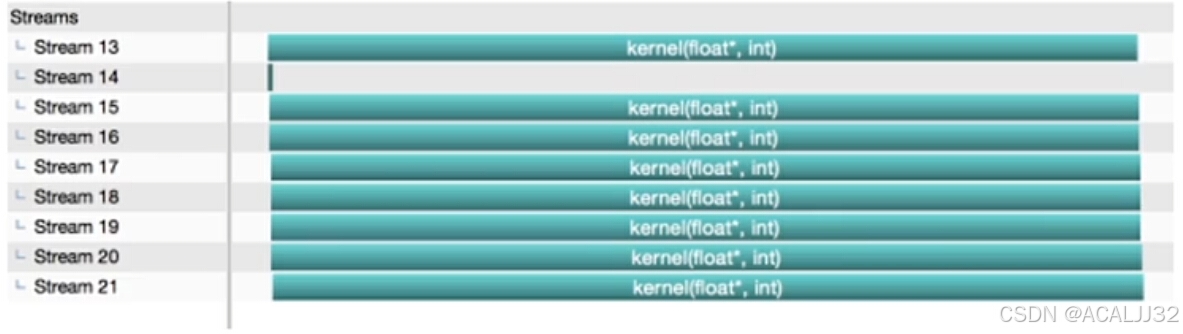
- 多线程里,不同线程默认使用一个默认流!除非编译加上default-stream!
CUDA Event
- CUDA Event,在Stream中插入一个事件,类似于打标记,用来记录stream是否执行到该位置。Event主要有两个状态,已被执行和未被执行。
- CUDA Event的一个主要作用:计时
// 使用event计算时间
float time_elapsed = 0;
cudaEvent_t start, stop;
cudaEventCreate(&start); // 创建Event
cudaEventCreate(&stop);
cudaEventRecord(start, 0); // 记录当前时间
mul<<<blocks, threads, 0, 0>>>(dev_a, NUM);
cudaEventRecord(stop, 0); // 记录当前时间
cudaEventSynchronize(start); // 等待start
cudaEventSynchronize(stop); // 等待stop
cudaEventElapsedTime(&time_elapsed, start, stop); // 计算时间差
cudaEventDestroy(start);
cudaEventDestroy(stop);
print("执行时间: %f(ms) \n", time_elapsed);
线程执行资源的分配
(1)线程束本地执行上下文主要资源构成:程序计数器,寄存器,共享内存。
(2)SM处理的每个线程束计算所需要的计算资源属于片上资源(on-chip)资源,因此从一个执行上下文切换到另一个执行上下文没有时间损耗。
(3)每个线程消耗的寄存器越多,则可以放在一个SM中的线程束越少;如果减少内核消耗寄存器的数量,SM可以处理更多的线程束。
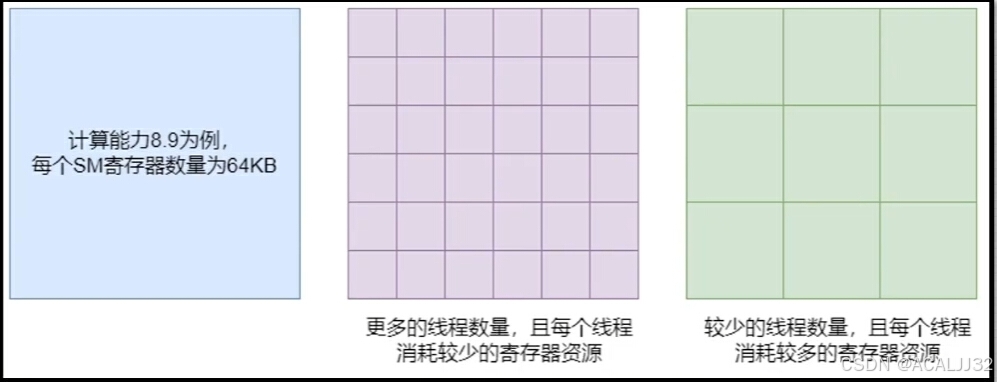
(4)一个线程块消耗的共享内存越多,则一个SM中可以同时处理的线程块就会变少。

延迟隐藏
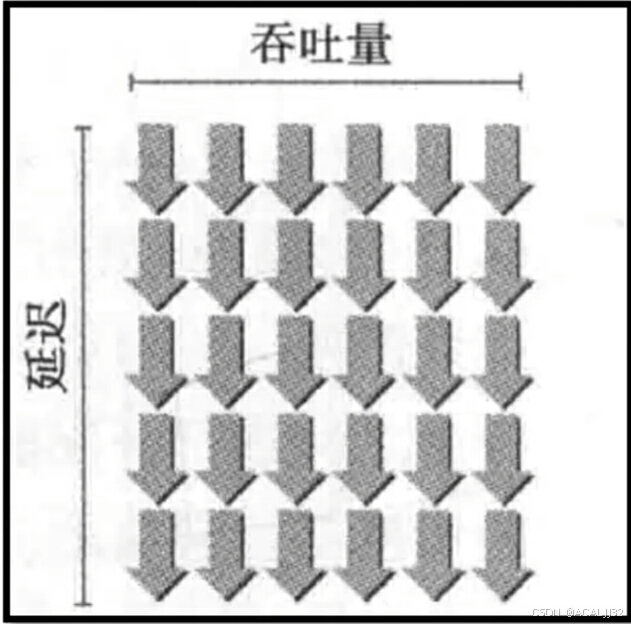
定义:在指令发出和完成之间的时钟周期定义为指令延迟。
如果每个时钟周期中,所有线程束调度器都有一个符合条件的线程束时,可以达到计算资源完全利用。GPU的指令延迟被其他线程束的计算隐藏,称为延迟隐藏。
(1)算术指令隐藏
算术指令延迟:从开始运算到得到计算结果的时钟周期,通常为4个时钟周期。为了满足延迟隐藏所需要的线程束数量,利用利特尔法则估计值:
所需线程束数量 = 延迟 X 吞吐量
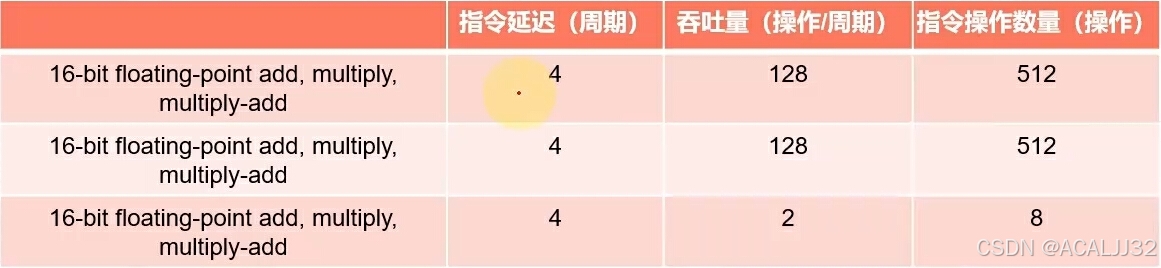
以第一行计算为例,4 X 128,指令操作数量至少为512才可以做到延迟隐藏。
(2)内存访问指令延迟
定义:从命令发出到数据到达目的地的时钟周期,通常为400~800个时钟周期。对内存而言,所需的并行可以表示为在每个时钟周期内隐藏内存延迟所需的字节数。

![]()

-
避免线程束分化
定义:一个线程束中的所有线程在同一个周期中必须执行相同的指令。如果一个线程束中的线程执行不同的分支的命令,则会造成线程束分化。
__global__ void kernel(float *A)
{
int tid = blockIdx.x * blockDim.x + threadIdx.x;
float a = 0.0f;
float b = 0.0f;
if(tid % 2 == 0)
{
a = 10.0f;
}
else
{
b = 20.0f;
}
A[tid] = a + b;
}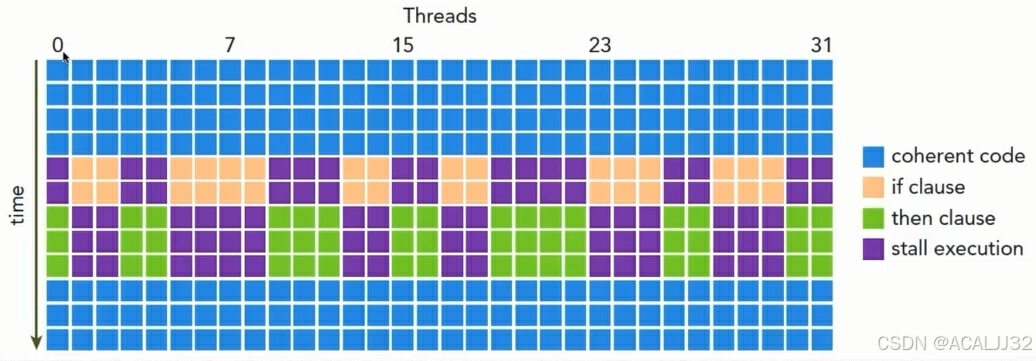
线程束分支只发生在同一个线程束中,不同线程束不会发生线程束分化。
if ((tid / 32) % 2 == 0)
{
a = 10.0f;
}
else
{
b = 20.0f;
}以上是一个常见的线程束解决思路。
并行规约计算:在向量中满足交换律和结合律的运算,称为规约问题,并行执行的规约计算称为并行规约计算。
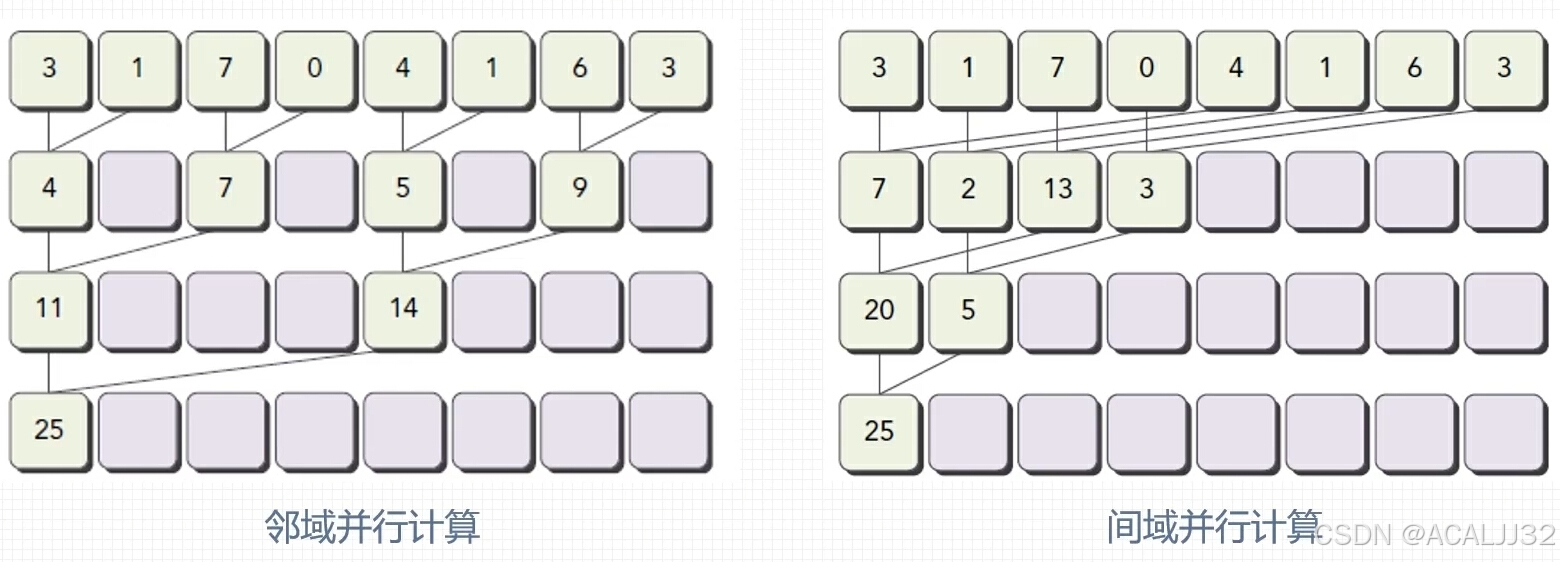
这里只粘贴部分代码,完整代码参考原up的视频和仓库
#include <iostream>
#include <stdio.h>
#include <cuda_runtime.h>
#include <string>
#include "utils.hpp"
#include "timer.hpp"
#include "reduce.hpp"
#include <cstring>
#include <memory>
#include <cmath>
int seed;
int main(int argc, char *argv[])
{
if (argc != 3)
{
std::cerr << "用法: ./build/reduction [size] [blockSize]" << std::endl;
return -1;
}
Timer timer;
char str[100];
int size = std::stoi(argv[1]);
int blockSize = std::stoi(argv[2]);
int gridsize = size / blockSize; // 这里存在问题
float* h_idata = nullptr;
float* h_odata = nullptr;
h_idata = (float*)malloc(size * sizeof(float));
h_odata = (float*)malloc(gridsize * sizeof(float));
seed = 1;
initMatrix(h_idata, size, seed);
memset(h_odata, 0, gridsize * sizeof(float));
// CPU归约
timer.start_cpu();
float sumOnCPU = ReduceOnCPU(h_idata, size);
timer.stop_cpu();
std::sprintf(str, "reduce in cpu, result:%f", sumOnCPU);
timer.duration_cpu<Timer::ms>(str);
// GPU warmup
timer.start_gpu();
ReduceOnGPUWithDivergence(h_idata, h_odata, size, blockSize);
timer.stop_gpu();
// timer.duration_gpu("reduce in gpu(warmup)");
// GPU归约(带分支)
timer.start_gpu();
ReduceOnGPUWithDivergence(h_idata, h_odata, size, blockSize);
timer.stop_gpu();
float sumOnGPUWithDivergence = 0;
for (int i = 0; i < gridsize; i++) sumOnGPUWithDivergence += h_odata[i];
std::sprintf(str, "reduce in gpu with divergence, result:%f", sumOnGPUWithDivergence);
timer.duration_gpu(str);
// GPU归约(不带分支)
timer.start_gpu();
ReduceOnGPUWithoutDivergence(h_idata, h_odata, size, blockSize);
timer.stop_gpu();
float sumOnGPUWithoutDivergence = 0;
for (int i = 0; i < gridsize; i++) sumOnGPUWithoutDivergence += h_odata[i];
std::sprintf(str, "reduce in gpu without divergence, result:%f", sumOnGPUWithoutDivergence);
timer.duration_gpu(str);
free(h_idata);
free(h_odata);
return 0;
}
第一种,带分支的计算:
__global__ void ReduceNeighboredWithDivergence(float *d_idata, float *d_odata, int size){
// set thread ID
unsigned int tid = threadIdx.x;
unsigned int idx = blockIdx.x * blockDim.x + threadIdx.x;
// convert global data pointer to the local pointer of this block
float *idata = d_idata + blockIdx.x * blockDim.x;
// boundary check
if (idx >= size) return;
// in-place reduction in global memory
for (int stride = 1; stride < blockDim.x; stride *= 2)
{
if ((tid % (2 * stride)) == 0)
{
idata[tid] += idata[tid + stride];
}
// synchronize within threadblock
__syncthreads();
}
// write result for this block to global mem
if (tid == 0) d_odata[blockIdx.x] = idata[0];
}第二种,不带分支的计算:
__global__ void ReduceNeighboredWithoutDivergence(float *d_idata, float *d_odata, unsigned int n)
{
// set thread ID
unsigned int tid = threadIdx.x;
unsigned int idx = blockIdx.x * blockDim.x + threadIdx.x;
// convert global data pointer to the local pointer of this block
float *idata = d_idata + blockIdx.x * blockDim.x;
// boundary check
if(idx >= n) return;
// in-place reduction in global memory
for (int stride = 1; stride < blockDim.x; stride *= 2)
{
// convert tid into local array index
int index = 2 * stride * tid;
if (index < blockDim.x)
{
idata[index] += idata[index + stride];
}
// synchronize within threadblock
__syncthreads();
}
// write result for this block to global mem
if (tid == 0) d_odata[blockIdx.x] = idata[0];
}-
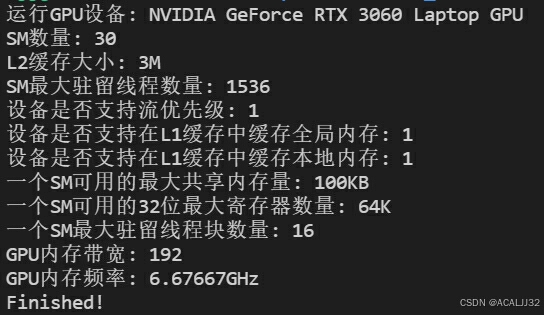
GPU信息查询
#include <stdio.h>
#include <iostream>
#include <cuda_runtime.h>
int main()
{
int devID = 0;
cudaDeviceProp deviceProps;
cudaGetDeviceProperties(&deviceProps, devID);
std::cout << "运行GPU设备: " << deviceProps.name << std::endl;
std::cout << "SM数量: " << deviceProps.multiProcessorCount << std::endl;
std::cout << "L2缓存大小: " << deviceProps.l2CacheSize / (1024 * 1024) << "M" << std::endl;
std::cout << "SM最大驻留线程数量: " << deviceProps.maxThreadsPerMultiProcessor << std::endl;
std::cout << "设备是否支持流优先级: " << deviceProps.streamPrioritiesSupported << std::endl;
std::cout << "设备是否支持在L1缓存中缓存全局内存: " << deviceProps.globalL1CacheSupported << std::endl;
std::cout << "设备是否支持在L1缓存中缓存本地内存: " << deviceProps.localL1CacheSupported << std::endl;
std::cout << "一个SM可用的最大共享内存量: " << deviceProps.sharedMemPerMultiprocessor / 1024 << "KB" << std::endl;
std::cout << "一个SM可用的32位最大寄存器数量: " << deviceProps.regsPerMultiprocessor / 1024 << "K" << std::endl;
std::cout << "一个SM最大驻留线程块数量: " << deviceProps.maxBlocksPerMultiProcessor << std::endl;
std::cout << "GPU内存带宽: " << deviceProps.memoryBusWidth << std::endl;
std::cout << "GPU内存频率: " << (float)deviceProps.memoryClockRate / (1024 * 1024) << "GHz" << std::endl;
std::cout << "Finished! \n";
return 0;
}
-
存储体冲突Bank Conflict
cuda编程中,32个thread组成一个warp,为了可以高效访存,shared memory中也对应分成了32个存储体,称为“bank”,对应32个线程。


一个理想的情况就是,32个线程,分别访问shared memory中的32个不同的bank(无bank confict),一个memory周期完成所有读写操作。
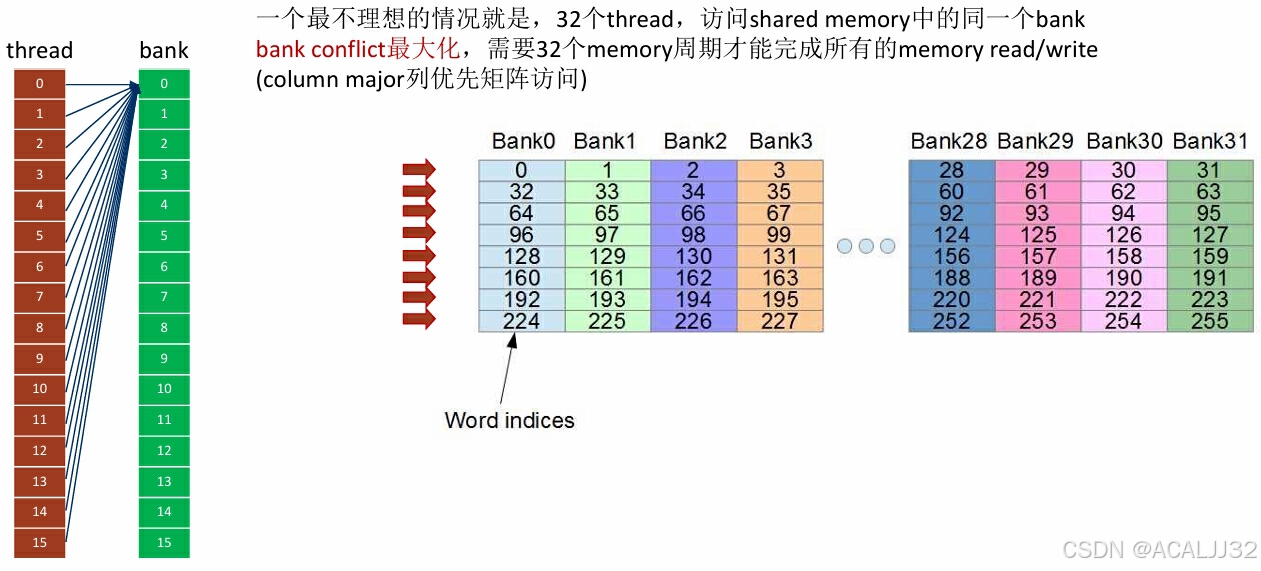
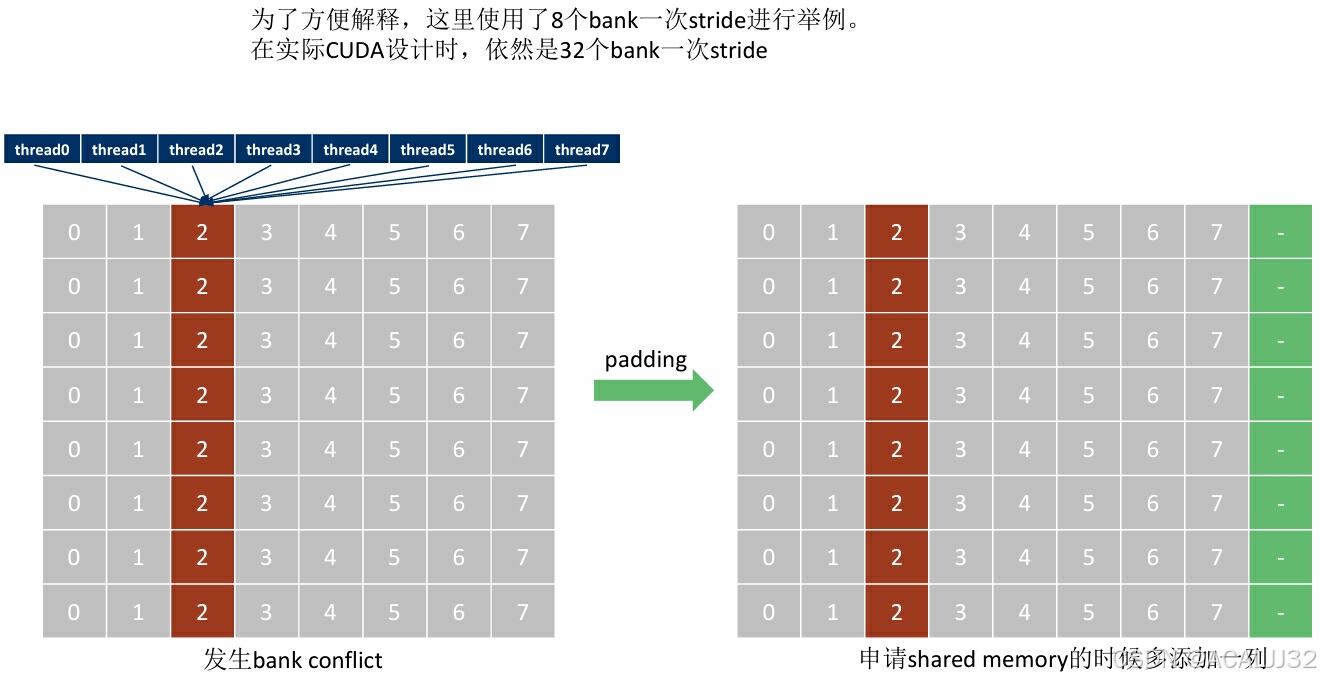
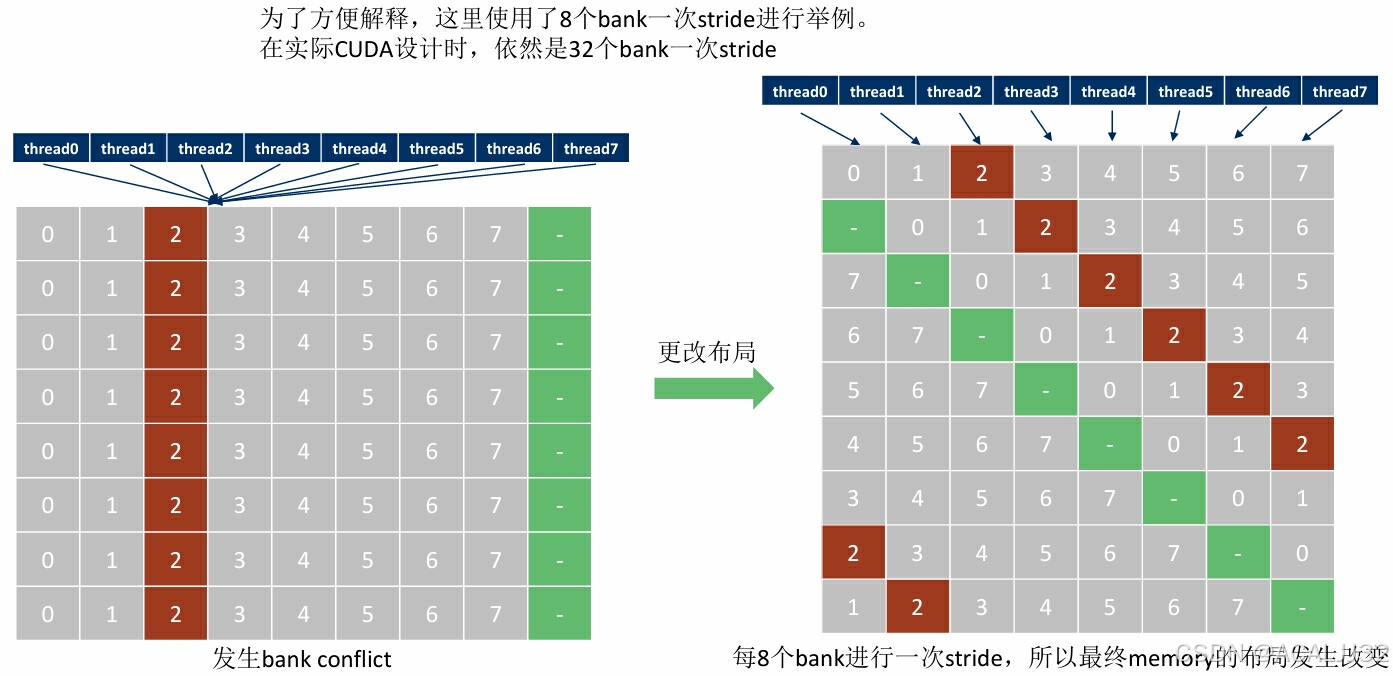
-
thread对应的硬件结构
在GPU中,一个thread对应的是CUDA core。CUDA core是GPU的基本处理单元,负责执行具体的计算任务。每个CUDA core 可以同时处理一个thread,但一个CUDA core 可能对应多个thread。
SM,GPU最小的执行单元,包含多个CUDA core,一个SM可以同时运行多个warp。
Warp,GPU执行程序的基本单元,一个warp对应32个thread,这些thread执行相同的指令。

















 316
316

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









