







论文:https://arxiv.org/abs/1904.06487v5
代码:http://cs-people.bu.edu/keisaito/research/MME.html
1.介绍
本文主要针对半监督领域自适应的场景,在分类器后加入一个分类层,用线性层中的每个类别对应的特征向量原型,与特征提取器出的样本特征向量相乘得到属于该类别的概率。利用对抗训练方式分别对分类层进行熵最大化,对特征提取器进行熵最小化,将特征向量原型训练为跨域不变原型的估计。在不同的数据集下都稳定超越了其他UDA方法和只用有标注图像训练的方式。
2.方法
实验设定:有标签源域图像Ds,有标签目标域图像Dt,无标签目标域图像Du,在Ds、Dt、Du上训练,在Du上评估测试。
2.1 基于相似度的网络架构
特征提取器F输出的特征,先经过L2norm,然后用一个线性层W(W=[w1,…,wK],K为分类类别数,其中每个特征向量wi对应类别i的类别原型特征),再用温度法乘,以1/T进行归一化,然后再传到softmax得到概率p(x):
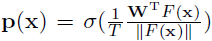
这里认为Wi可以用类别i的原型prototype向量,个人理解这样做的原因是Wi和embedding的特征的相乘再除以embedding的范数,可以理解为一种近似余弦相似度的近似,当一个样本和wi相似度越高输出的属于类别的概率p(xi)也越大,所以如图1中所示的域不变特征原型wi可以表示一个类别在不同域中表现出的域不变知识(比如我们人对于卡通的狗和真实照片中的狗具有的共通特征的认识,这种认识让我们不管让狗以何种形式展现都能分辨出来)。整体的网络结构如下图:

2.2 训练目标
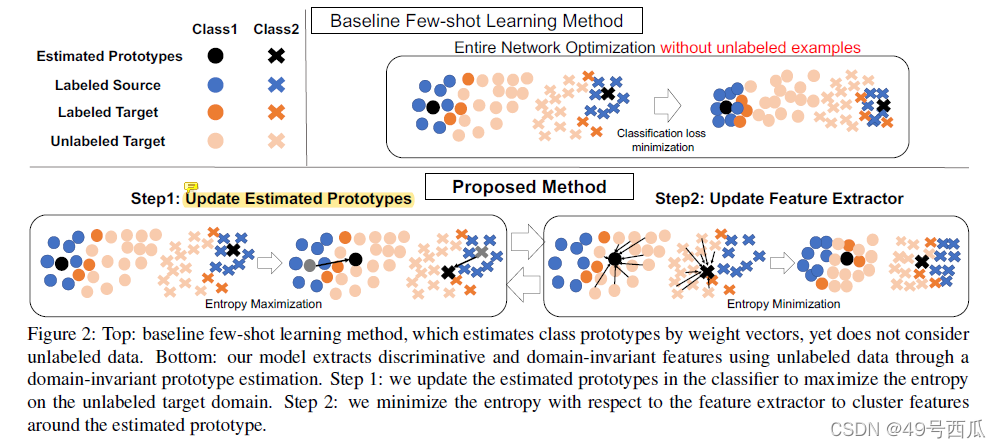
训练的过程中,先用交叉熵损失对Ds、Dt进行优化,然后对Du进行熵最小化得到可描述的(类别之间分明的)特征。
如图2步骤1所示,假设每个类别都存在一个域不变原型,优化分类头C最大化Du的熵值,将类别的边界划分的更加的宽松,所以导致类别原型从源域数据集中的位置中扩散更接近目标域中该类别的特征,这样原型才为域不变原型。熵最大化可以防止表征的过拟合,可以认为是一种选择可以防止过拟合的原型的过程。步骤2,优化特征提取器F最小化Du的熵值,即使固定了类别边界,去优化特征的空间分布,让每个目标域特征更加接近某一个特定的类别。所以对抗训练优化函数为:
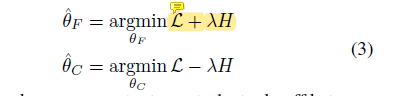
其中,L为有标注的Ds、Dt的监督损失,H为Du的熵值。对抗的具体实现由梯度反转层GRL实现,即是Du的熵值H在C和F之间的梯度反转。
2.3 理论内核
假设h是一种假设(个人理解为输入到输出的拟合网络),源域预计损失和目标域预计损失的风险(个人理解为模型的损失)
ϵ
t
h
\epsilon_{t}^{h}
ϵth、
ϵ
s
h
\epsilon_{s}^{h}
ϵsh的不等式关系为: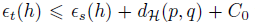
源域和目标域之间的风险的差距,不可消除的是假设空间的系统误差,可以消除的是通过准确估计两个域之间的H-散度
d
H
(
p
,
q
)
d_{H}^{(p,q)}
dH(p,q)来实现
的: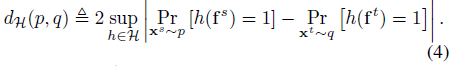
目前在DA领域中额外增加域判别器对抗训练来实现对以上H散度的建模,本文虽没有直接采用预判别器训练,但是用最大最小化熵实现了近似的效果。
3.实验
3.1 设定
针对一个域,在每个类别中随机选择1或者3张图片(one-shot或three-shot设定)作为目标域标注图像,选取类别中另外3张作为验证集用于调整超参数,其他的目标域图像的原图可以用于无监督训练,而且最后被用来测试准确度。
数据集:三个数据集domainnet、office-home、office有选择的选取了一些域适应组合。
实现细节:网络:imagenet上与训练的AlexNet和VGG16,在domainNet上用的Resnet34。每次迭代有有标注样本和无标注样本两个batch,其中有标注的batch一半由源域标注图构成一半来自于目标域标注图。无监督损失前的权重最优值
λ
\lambda
λ通过验证集的表现获得(支撑材料中说实在domainNet上用Alexnet得到最高准确率时的值,然后其他所有实验都是用0.1固定不变了)。用梯度反转层实现熵最大最小训练。给分类头C的无监督图像损失熵符号为正(信息熵的负),特征提取器中的为负(信息熵)。
3.2 结果
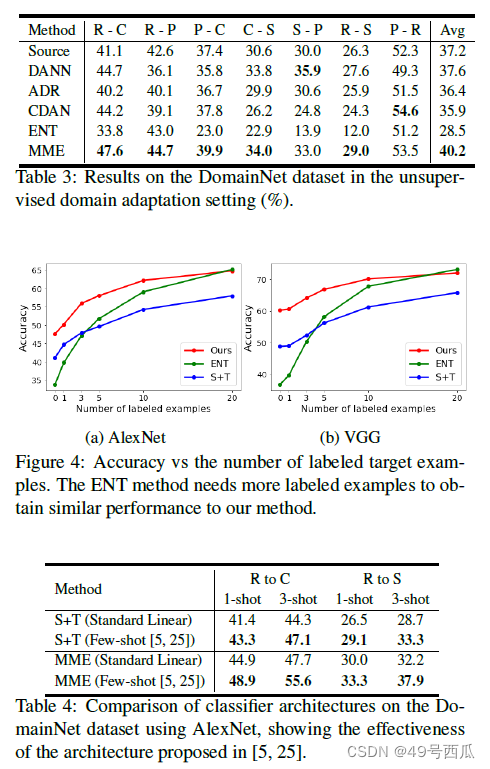
本文主要对比了直接在源域和有标注的目标域上训练的模型(S+T),以及其他UDA的方法。实验发现,UDA方法虽然运用了无标注图像,但是有些设定下的性能还比不过S+T的方法。典型的例子为ENT熵最小化的UDA方法,在增加数据标注量的时候,才比S+T的方式要强,在数据集小情况下比S+T还要明显差。但是本文提出的MME方法在各种规模的网络和不同的数据集下基本上都比S+T都要好。
增加标注的数量和BN层(Alexnet和VGG没有,ResNet才有)在一些DA的组合下明显有助于提高准确率。(验证在附加材料中)
3.3 分析
1.不同的标注数量:
没有标注,UDA的设定下(如表3),本文的MME仍然要比其他的UDA以及S+T要强。
逐渐增加标注(如图4),发现本文的方法能一直领先于S+T的方法,说明了有效利用了无标注目标域图像的特征节省了标注。最终与ENT方法持平表明随着标注数量的上升,对于域不变原型的估计越发准确(ENT方法实现的原型估计就是熵最小化)。
2.分类头的架构:
Alexnet中加入L2 norm和温度缩放对S+T和MME都有涨点。
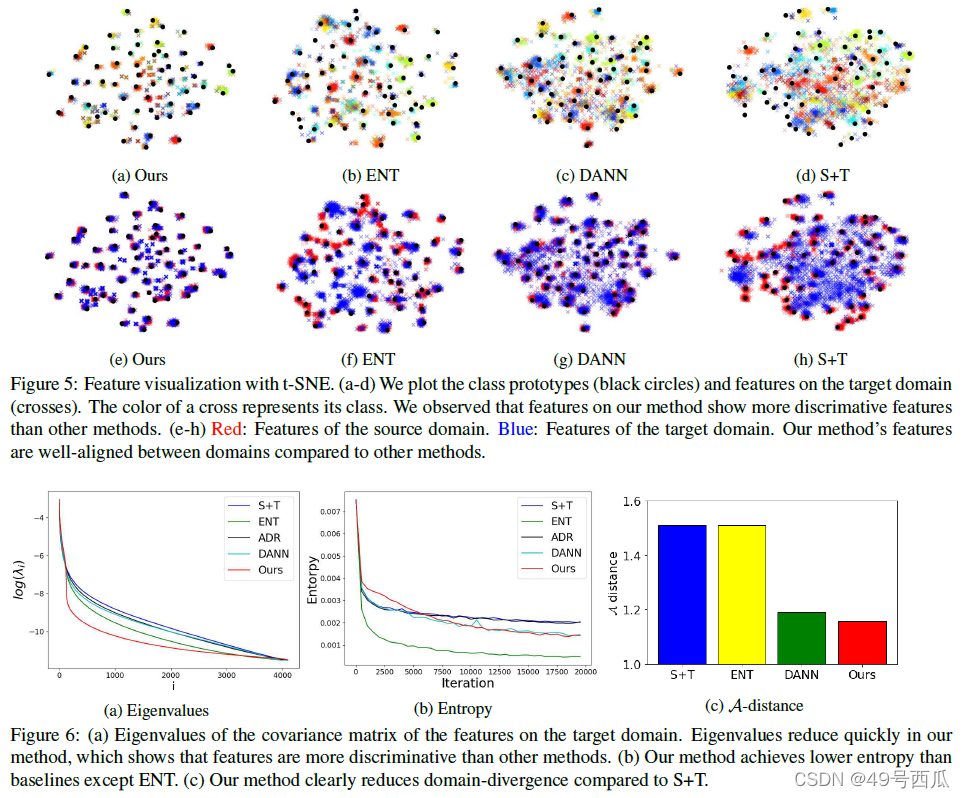
3.可视化t-sne:
如图5所示,MME可以同时得到可描述的表征(类别之间划分界限很清楚分明),并且可以准确估计类别原型(原型所属的簇中的特征比较集中方差小)。
4.定量分析:
一些分析方法认为如果特征是高度可描述的(个人理解为类别之间分明),那么它的Eigenvectors特征向量由几个重要的成分就能描述,其他的成分并不重要。分析发现MME对目标特征进行分析发现他们的熵值的确要小(如图6)

















 3502
3502

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









