







作者:Irain
QQ:2573396010
微信:18802080892
GitHub项目链接:https://github.com/Irain-LUO/machine_learning
视频资源链接:文本相似度
本次文章应用:狂人日记分别于红楼梦、莎士比亚悲剧进行相似度比较
应用场景:推送相似文本(小说、文章、影视、商品)、自动匹配推荐
目录
1 下载
1.1 下载文本
1.2 下载第三方库

下载命令:pip install gensim -i https://pypi.douban.com/simple/
下载命令:pip install jieba -i https://pypi.douban.com/simple/
2 文本相似识别过程
2.1 引用第三方库
from gensim import corpora, models, similarities
import jieba
from collections import defaultdict
2.2 读取文档
# 读取文档
Dream = open("红楼梦.txt",encoding='utf-8').read()
Grieving = open("莎士比亚悲剧.txt",encoding='utf-8').read(

2.3 文本分词
datas_Dream = jieba.cut(Dream)
data_Dream = ""
for data in datas_Dream:
data_Dream += data + " "
#print(data)
pass
datas_Grieving = jieba.cut(Grieving)
data_Grieving = ""
for data in datas_Grieving:
data_Grieving += data + " "
#print(data)
pass
documents = [data_Dream,data_Grieving]
# document.split():使用空格分词
texts = [[word for word in document.split()] for document in documents]

2.4 计算词频
defaultdict函数内容链接:
https://blog.youkuaiyun.com/real_ray/article/details/17919289
https://www.jianshu.com/p/26df28b3bfc8
frequency = defaultdict(int)
for text in texts:
for token in text:
frequency[token] += 1

2.5 过滤频率少数据.调控相似度
texts = [[token for token in text if frequency[token] > 30 ] for text in texts]
2.6 通过语料库建立词典,保存词典
dictionary = corpora.Dictionary(texts)
dictionary.save("dict.txt")

2.7 加载要对比的文档
doc = open("狂人日记.txt").read()
datas_doc = jieba.cut(doc)
data_doc = ""
for item in datas_doc:
data_doc += item + " "

2.8 使用doc2bow把需要对比的文档转换为稀疏向量
data_vec = dictionary.doc2bow(data_doc.split())
corpus = [dictionary.doc2bow(text) for text in texts]
2.9 将新语料库通过tfidfmodel进行处理,得到TF-IDF模型
tfidf = models.TfidfModel(corpus)
2.10 通过token2id得到特征数
featureNum = len(dictionary.token2id.keys())
2.11 稀疏矩阵相似度,从而建立索引
index = similarities.SparseMatrixSimilarity(tfidf[corpus],num_features=featureNum)
2.12 得到最终相似度结果
sim = index[tfidf[data_vec]]
print(sim)
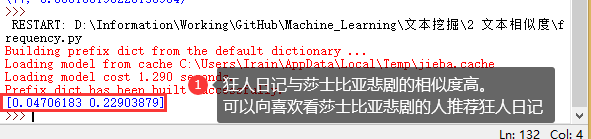
参考链接:
https://www.jianshu.com/p/d10fd1575a27
https://cloud.tencent.com/developer/article/1010859
发布:2020年5月28日

















 868
868

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









