



案例设备
处理器 13th Gen Intel® Core™ i7-13620H 2.40 GHz
机带 RAM 16.0 GB (15.7 GB 可用)
NVIDIA GeForce RTX 4060 Laptop GPU
系统类型 64 位操作系统, 基于 x64 的处理器
在开始前需要确认电脑是否安装CUDA
https://blog.youkuaiyun.com/weixin_42120140/article/details/146768424?spm=1001.2014.3001.5502
创建conda环境
conda create -n internvl python==3.10.11 -y
conda activate internvl
conda安装可参考网络教程
环境安装
accelerate 1.5.2
av 14.2.0
certifi 2025.1.31
charset-normalizer 3.4.1
colorama 0.4.6
decord 0.6.0
einops 0.8.1
filelock 3.18.0
fsspec 2025.3.0
huggingface-hub 0.29.3
idna 3.10
Jinja2 3.1.6
MarkupSafe 3.0.2
modelscope 1.24.0
mpmath 1.3.0
networkx 3.4.2
numpy 2.2.4
packaging 24.2
pillow 11.1.0
pip 25.0.1
psutil 7.0.0
PyYAML 6.0.2
regex 2024.11.6
requests 2.32.3
safetensors 0.5.3
setuptools 75.8.2
sympy 1.13.1
timm 1.0.15
tokenizers 0.21.1
torch 2.5.1+cu121
torchaudio 2.5.1+cu121
torchvision 0.20.1+cu121
tqdm 4.67.1
transformers 4.50.2
typing_extensions 4.13.0
urllib3 2.3.0
wheel 0.45.1
sentencepiece 0.2.0
InternVL模型下载
modelscope download --model OpenGVLab/InternVL2_5-2B --local_dir modelPath
**–model:**模型有如下,目前测试2B在RTX4060下是可以运行的,4B理论上单图推理应该是可以的
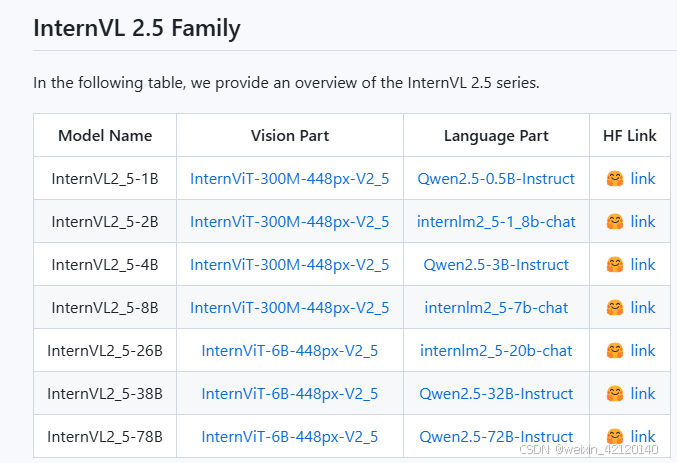
推理显存占用
推理代码
python internvl.py
internvl.py:
import numpy as np
import torch
import torchvision.transforms as T
from decord import VideoReader, cpu
from PIL import Image
from torchvision.transforms.functional import InterpolationMode
from modelscope import AutoModel, AutoTokenizer
IMAGENET_MEAN = (0.485, 0.456, 0.406)
IMAGENET_STD = (0.229, 0.224, 0.225)
def build_transform(input_size):
MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
transform = T.Compose([
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),
T.ToTensor(),
T.Normalize(mean=MEAN, std=STD)
])
return transform
def find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):
best_ratio_diff = float('inf')
best_ratio = (1, 1)
area = width * height
for ratio in target_ratios:
target_aspect_ratio = ratio[0] / ratio[1]
ratio_diff = abs(aspect_ratio - target_aspect_ratio)
if ratio_diff < best_ratio_diff:
best_ratio_diff = ratio_diff
best_ratio = ratio
elif ratio_diff == best_ratio_diff:
if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:
best_ratio = ratio
return best_ratio
def dynamic_preprocess(image, min_num=1, max_num=12, image_size=448, use_thumbnail=False):
orig_width, orig_height = image.size
aspect_ratio = orig_width / orig_height
# calculate the existing image aspect ratio
target_ratios = set(
(i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if
i * j <= max_num and i * j >= min_num)
target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
# find the closest aspect ratio to the target
target_aspect_ratio = find_closest_aspect_ratio(
aspect_ratio, target_ratios, orig_width, orig_height, image_size)
# calculate the target width and height
target_width = image_size * target_aspect_ratio[0]
target_height = image_size * target_aspect_ratio[1]
blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
# resize the image
resized_img = image.resize((target_width, target_height))
processed_images = []
for i in range(blocks):
box = (
(i % (target_width // image_size)) * image_size,
(i // (target_width // image_size)) * image_size,
((i % (target_width // image_size)) + 1) * image_size,
((i // (target_width // image_size)) + 1) * image_size
)
# split the image
split_img = resized_img.crop(box)
processed_images.append(split_img)
assert len(processed_images) == blocks
if use_thumbnail and len(processed_images) != 1:
thumbnail_img = image.resize((image_size, image_size))
processed_images.append(thumbnail_img)
return processed_images
def load_image(image_file, input_size=448, max_num=12):
image = Image.open(image_file).convert('RGB')
transform = build_transform(input_size=input_size)
images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(image) for image in images]
pixel_values = torch.stack(pixel_values)
return pixel_values
# If you want to load a model using multiple GPUs, please refer to the `Multiple GPUs` section.
path = r'.\model\InternVL2_5-2B'
imagePath1=r".\model\InternVL2_5-2B\examples\image1.jpg"
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True).eval().cuda()
tokenizer = AutoTokenizer.from_pretrained(path, trust_remote_code=True, use_fast=False)
# set the max number of tiles in `max_num`
pixel_values = load_image(imagePath1, max_num=12).to(torch.bfloat16).cuda()
generation_config = dict(max_new_tokens=1024, do_sample=True)
# pure-text conversation (纯文本对话)
question = 'Hello, who are you?'
response, history = model.chat(tokenizer, None, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Can you tell me a story?'
response, history = model.chat(tokenizer, None, question, generation_config, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# single-image single-round conversation (单图单轮对话)
question = '<image>\nPlease describe the image shortly.'
response = model.chat(tokenizer, pixel_values, question, generation_config)
print(f'User: {question}\nAssistant: {response}')
# single-image multi-round conversation (单图多轮对话)
question = '<image>\nPlease describe the image in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Please write a poem according to the image.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
例子:
图片:

问题:
User: 请详细描述图片内容
回答:
Assistant: 这是一幅卡通图像,描绘了一个穿着黄色和白色衣服的角色。他正蹲着,身体微微向前倾。角色表情显得有些严肃或焦虑,脸颊涨满了红色。一只手正在摸耳朵,仿佛在听很响的声音。图像的风格简洁明快,线条简单。
Error报错:
AssertionError: Torch not compiled with CUDA enabled
主要是torch安装的为cpu版本,如果pip安装不了cuda版本的torch,需要手动下载安装,解决方法有两种,1手动下载安装包,2.pip安装指定官网地址
1)手动安装官网下载下载torch
https://download.pytorch.org/whl/torch/
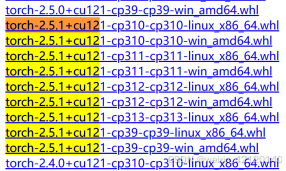
cu 指的是cuda版本,低于系统cuda版本均可,不可高于
cp python版本cp310->python==3.10
Win windows系统
下载torchvision
https://download.pytorch.org/whl/torchvision/
参数和torch一样,torch和torchvision需要对应,详情查看
https://pytorch.org/get-started/previous-versions/
2)pip指定官网安装
pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 --index-url https://download.pytorch.org/whl/cu121
2.torch.OutOfMemoryError: CUDA out of memory
问题主要是显存大小不够,
解决方法:
1.关闭运行的一些程序,降低显存占用,或者设置显示器为集显输出
2.internvl会将图片切为多张图片,导致显存溢出,需要缩小max_num大小,默认max_num=12,可以将max_num设置小一点


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









