







 本文深入讲解数据分析中的基本统计、分组、交叉、结构、相关、RFM及矩阵分析方法,通过实例演示各方法的应用,帮助读者掌握数据分析核心技能。
本文深入讲解数据分析中的基本统计、分组、交叉、结构、相关、RFM及矩阵分析方法,通过实例演示各方法的应用,帮助读者掌握数据分析核心技能。
基本统计
基本统计分析:描述性统计分析,用来概括事物整体状况以及事物间联系(即事物的基本特征),以发现其内在规律的统计分析方法。
常用的统计指标:计数、求和、平均值、方差、标准差
描述性统计分析函数:describe()
常用的统计函数:
| 统计函数 | 注释 |
|---|---|
| size | 计数 |
| sum | 求和 |
| mean | 平均值 |
| var | 方差 |
| std | 标准差 |
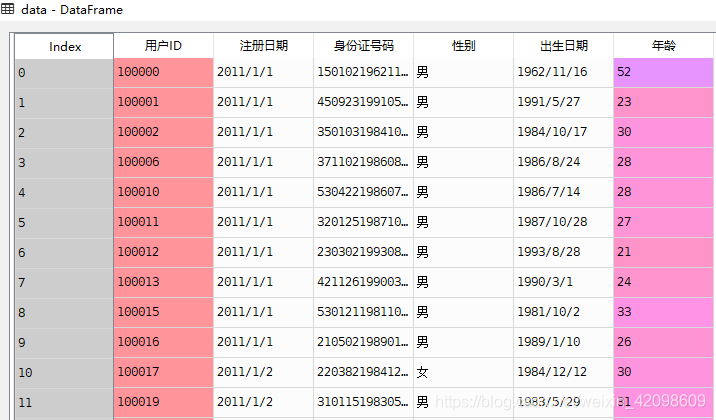
举例
import pandas
data = pandas.read_csv('D://Data Analysis//5.1//data.csv',sep=',')
data.score.describe()
'''
count 13.000000
mean 121.076923
std 12.446295
min 96.000000
25% 115.000000
50% 120.000000
75% 131.000000
max 140.000000
Name: score, dtype: float64
'''
# 计数
data.score.size
# 基本统计量
data.score.min()
data.score.max()
data.score.mean()
data.score.min()
data.score.std()
# 变量累积
data.score.cumsum()
'''
0 120
1 242
2 382
3 513
4 635
5 754
6 850
7 985
8 1090
9 1204
10 1319
11 1455
12 1574
Name: score, dtype: int64
'''
# 查找最大值、最小值所在位置
data.score.argmin()
data.score.argmax()
# quantile(percent,interpolation)函数用于输出百分之几处的数,nearest表示取离百分处最近的值
data.score.quantile(0.5,interpolation='nearest')
分组分析
分组分析是指,根据分组字段,将分析对象划分为不同的部分,以进行对比分析各组之间的差异性的一种分析方法。
分组分析主要分为两大类:定性分组(如性别、年龄)、定量分组。常用统计指标:计数、求和、平均值
分组统计函数:
groupby(by=[分组列1,分组列2,...])[统计列1,统计列2,...].agg({统计列别名1:统计函数1,统计列别名2:统计函数2,...})
参数说明:
by: 用于分组的列- 中括号: 用于统计的列
agg: 统计别名显示统计值的名称,统计函数用于统计数据
| 常用统计函数 | 注释 |
|---|---|
| size | 计数 |
| sum | 求和 |
| mean | 均值 |
举例
原始数据
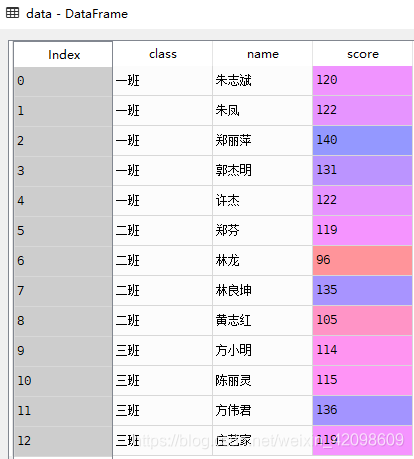
import pandas
import numpy
data = pandas.read_csv('D://Data Analysis//5.2//data.csv')
# 按class分组,根据score来分析每个class的统计量
groups = data.groupby(
by=['class'])['score'].agg({'总人数':numpy.size,'总分':numpy.sum,'平均值':numpy.mean})
'''
运行上面这个语句能出结果,但会出现一个警告:FutureWarning: using a dict on a Series for aggregation
is deprecated and will be removed in a future version
因此,修改成如下语句,正常运行。
'''
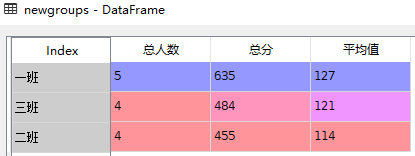
newgroups = data.groupby(
by=['class'])['score'].agg([numpy.size,numpy.sum,numpy.mean])
newgroups.columns = ['总人数','总分','平均值']
分布分析
分布分析是指,根据分析目的,将数据(定量数据)进行等距或者不等距的分组,进行研究各组分布规律的一种分析方法。
举例
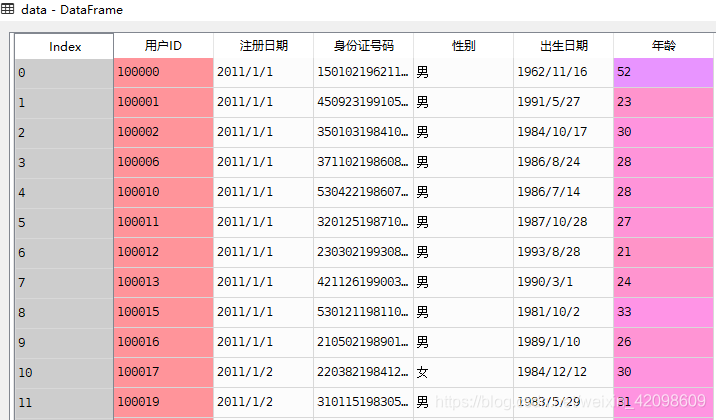
对当前数据,根据年龄进行分组,并查看分布情况。
import pandas
import numpy
data = pandas.read_csv('D://Data Analysis//5.3//data.csv',sep=',')
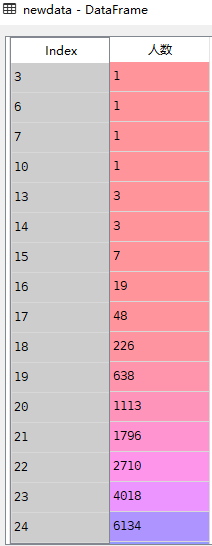
# 直接按年龄分组,太过细碎
newdata = data.groupby(by=['年龄'])['年龄'].agg([numpy.size])
newdata = newdata.rename(columns={'size':'人数'})
输出:
import pandas
import numpy
data = pandas.read_csv('D://Data Analysis//5.3//data.csv',sep=',')
# 直接按年龄分组,太过细碎
newdata = data.groupby(by=['年龄'])['年龄'].agg([numpy.size])
newdata = newdata.rename(columns={'size':'人数'})
# 根据年龄画出柱状图
data.年龄.hist()
输出:
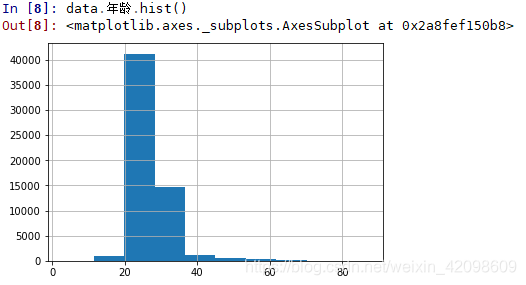
import pandas
import numpy
data = pandas.read_csv('D://Data Analysis//5.3//data.csv',sep=',')
# 直接按年龄分组,太过细碎
newdata = data.groupby(by=['年龄'])['年龄'].agg([numpy.size])
newdata = newdata.rename(columns={'size':'人数'})
# 根据年龄画出柱状图
data.年龄.hist()
# 利用cut函数,对年龄进行分组
bins = [data.年龄.min()-1,20,30,40,data.年龄.max()+1]
labels = ['20岁及以下','20以上及30岁','30以上及40岁','40岁以上']
data['年龄分层'] = pandas.cut(
data.年龄,
bins,
labels=labels)
newdata = data.groupby(by=['年龄分层'])['年龄'].agg([numpy.size])
pnewdata = round(newdata/newdata.cumsum(),2)*100
pnewdata['size'].map('{:,.2f}%'.format)
output:
年龄分层
20以上及30岁 100.00%
20岁及以下 4.00%
30以上及40岁 15.00%
40岁以上 2.00%
Name: size, dtype: object
输出:
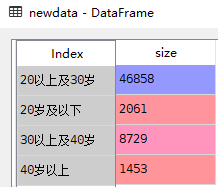
交叉分析
交叉分析:通常用于分析两个或两个以上,分组变量之间的关系,以交叉表形式进行变量间关系的对比分析;
- 定量、定量分组交叉
- 定量、定性分组交叉
- 定性、定性分组交叉
建议两个维度最好,维度越多,分的越细,越没有重点。
交叉计数函数:
pivot_table(values,index,columns,aggfunc,fill_value)
参数说明:
values: 数据透视表中的值index: 数据透视表中的行columns: 数据透视表中的列aggfunc: 统计函数fill_value: NA值的统一替换
举例
import pandas
import numpy
data = pandas.read_csv('D://Data Analysis//5.4//data.csv')
bins = [data.年龄.min()-1,20,30,40,data.年龄.max()+1]
labels = ['20岁以下及20岁','20岁以上及30岁','30岁以上及40岁','40岁以上']
data['年龄分层'] = pandas.cut(
data.年龄,
bins,
labels=labels)
# 设置行为‘年龄分层’,列为‘性别’,数值为年龄的计数
newdata = data.pivot_table(
values = '年龄',
index = '年龄分层',
columns = '性别',
aggfunc = [numpy.size])
输出结果:
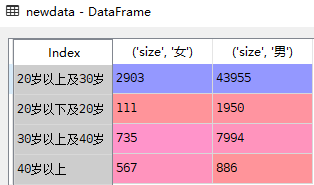
结构分析
结构分析:是在分组以及交叉的基础上,计算各组成部分所占的比重,进而分析总体的内部特征的一种分析方法。通常使用饼图(多个部分)或圆环图(两个部分)显示。
使用groupby计算出分组的结果或者用pivot_table计算出交叉结果之后,需要进一步计算可以使用DataFrame自带的函数进行运算。自带函数分为两类:外运算和内运算。
数据框的外运算函数:
| 运算 | 注释 |
|---|---|
| add | 加 |
| sub | 减 |
| multiply | 乘 |
| div | 除 |
数据框的内运算函数:
| 运算 | 注释 |
|---|---|
| sum | 求和 |
| mean | 均值 |
| var | 方差 |
| sd | 标准差 |
axis参数指定按行还是按列运算。
0:按列运算,默认按列运算1:按行运算
根据上述交叉分析的结果举例。
import pandas
import numpy
data = pandas.read_csv('D://Data Analysis//5.4//data.csv')
bins = [data.年龄.min()-1,20,30,40,data.年龄.max()+1]
labels = ['20岁以下及20岁','20岁以上及30岁','30岁以上及40岁','40岁以上']
data['年龄分层'] = pandas.cut(
data.年龄,
bins,
labels=labels)
# 设置行为‘年龄分层’,列为‘性别’,数值为年龄的计数
newdata = data.pivot_table(
values = ['年龄'],
index = ['年龄分层'],
columns = ['性别'],
aggfunc = [numpy.size])
# 默认按列计算
newdata.sum()
newdata.sum(axis=0)
# output
'''
性别
size 年龄 女 4316
男 54785
dtype: int64
'''
# 按行计算
newdata.sum(axis=1)
# output
'''
年龄分层
20岁以上及30岁 46858
20岁以下及20岁 2061
30岁以上及40岁 8729
40岁以上 1453
dtype: int64
'''
# 计算占比
newdata.div(newdata.sum(axis=0),axis=1)
# output
'''
size
年龄
性别 女 男
年龄分层
20岁以上及30岁 0.672614 0.802318
20岁以下及20岁 0.025718 0.035594
30岁以上及40岁 0.170297 0.145916
40岁以上 0.131372 0.016172
'''
newdata.div(newdata.sum(axis=1),axis=0)
# output
'''
size
年龄
性别 女 男
年龄分层
20岁以上及30岁 0.061953 0.938047
20岁以下及20岁 0.053857 0.946143
30岁以上及40岁 0.084202 0.915798
40岁以上 0.390227 0.609773
'''
相关分析
相关分析(correlation analysis):是研究两个或两个以上随机变量之间相互依存关系的方向和密切程度的方法。包含线性相关和非线性相关。
线性相关关系主要采用皮尔逊(Pearson)相关系数r来度量连续变量之间线性相关强度。r为负表示负相关,为正表示正相关,r=0表示无线性关系(但可以存在其他关系)。
线性相关系数|r|取值范围 | 相关程度 |
|---|---|
| 0 ≤ \leq ≤|r|<0.3 | 低度相关 |
| 0.3 ≤ \leq ≤|r|<0.8 | 中度相关 |
| 0.8 ≤ \leq ≤|r| ≤ \leq ≤ 1 | 高度相关 |
相关分析函数:
DataFrame.corr()
Series.corr(other)
函数说明:
- 如果由数据框调用
corr方法,那么将会计算每个列两两之间的相似度 - 如果由序列调用
corr方法,那么只是计算该序列与传入序列之间的相关度
返回值:
DataFrame调用:返回DataFrame
Series调用:返回一个数值型,大小为相关度
举例

import pandas
data = pandas.read_csv('D://Data Analysis//5.6//data.csv')
# Series比较两列数据相关性
data['人口'].corr(data['文盲率'])
'''
0.10762237339473261
'''
# DataFrame每两列计算相关性
data.corr()
'''
小区ID 人口 平均收入 文盲率 超市购物率 网上购物率 本科毕业率
小区ID 1.000000 -0.051500 -0.222223 -0.170539 -0.251381 0.251381 -0.078813
人口 -0.051500 1.000000 0.208228 0.107622 0.343643 -0.343643 -0.098490
平均收入 -0.222223 0.208228 1.000000 -0.437075 -0.230078 0.230078 0.619932
文盲率 -0.170539 0.107622 -0.437075 1.000000 0.702975 -0.702975 -0.657189
超市购物率 -0.251381 0.343643 -0.230078 0.702975 1.000000 -1.000000 -0.487971
网上购物率 0.251381 -0.343643 0.230078 -0.702975 -1.000000 1.000000 0.487971
本科毕业率 -0.078813 -0.098490 0.619932 -0.657189 -0.487971 0.487971 1.000000
'''
# DataFrame中多列计算相关性
data[['人口','文盲率','超市购物率','网上购物率']].corr()
'''
人口 文盲率 超市购物率 网上购物率
人口 1.000000 0.107622 0.343643 -0.343643
文盲率 0.107622 1.000000 0.702975 -0.702975
超市购物率 0.343643 0.702975 1.000000 -1.000000
网上购物率 -0.343643 -0.702975 -1.000000 1.000000
'''
RFM分析
RFM分析:是根据客户活跃程度和交易金额贡献,进行客户价值细分的一种方法。
| 指标 | 解释 | 意义 |
|---|---|---|
| R(Recency)近度 | 客户最近一次交易时间到现在的间隔 | R越大,表示客户越久未发生交易;R越小,表示客户越近有交易发生 |
| F(Frequency)频度 | 客户在最近一段时间内交易的次数 | F越大,说明客户交易越频繁;F越小,表示客户不够活跃 |
| M(Monetary)额度 | 客户在最近一段时间内交易的金额 | M越大,表示客户价值越高;M越小,表示客户价值越低 |
RFM分析过程
- 计算RFM各项分值
R_S:距离当前日期越近,得分越高,最高5分,最低1分F_S:交易频率越高,得分越高,最高5分,最低1分M_S:交易金额越高,得分越高,最高5分,最低1分
-
汇总RFM分值
R F M = 100 × R _ S + 10 × F _ S + 1 × M _ S RFM=100\times R\_S+10\times F\_S+1\times M\_S RFM=100×R_S+10×F_S+1×M_S -
根据RFM分值对客户分类
-
根据三项高低,客户类型共8类
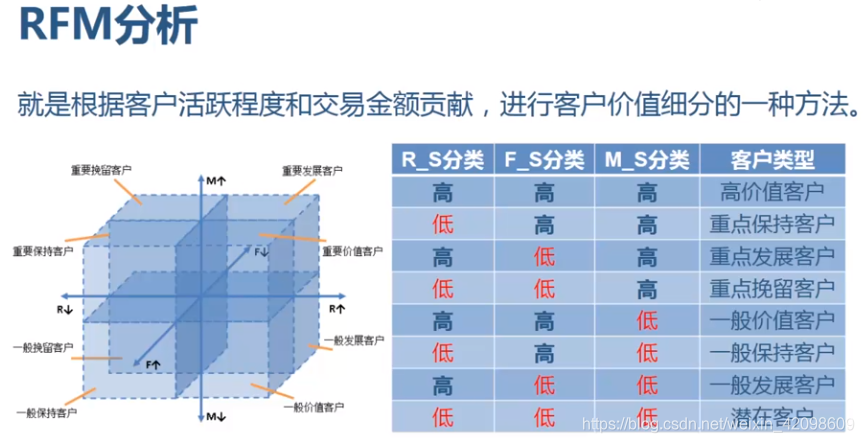
RFM分析前提
(1) 最近有过交易行为的客户,再次发生交易的可能性要高于最近没有交易行为的客户;
(2) 交易频率较高的客户比交易频率较低的客户,更有可能再次发生交易行为;
(3) 过去所有交易总金额较多的客户,比交易总金额较少的客户,更有消费积极性。
举例
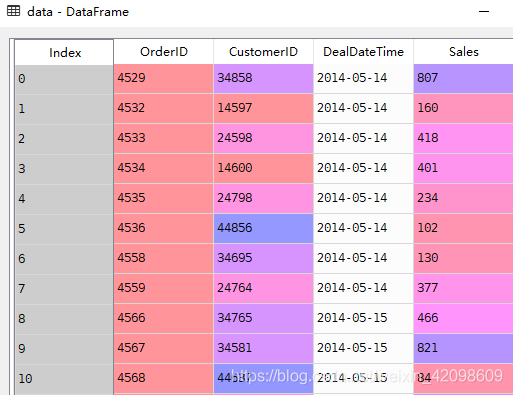
原始数据包含订单号(OrderID)、用户ID(CustomerID)、交易时间(DealDateTime)、交易金额(Sales)。RFM分析的代码如下。
# -*- coding: utf-8 -*-
import pandas
import numpy
data = pandas.read_csv('D://Data Analysis//5.7//data.csv')
# 计算近度,首先处理时间列
data['DealDateTime'] = pandas.to_datetime(data.DealDateTime,format='%Y/%m/%d')
# 计算到现在的时间间隔
data['DateDiff'] = pandas.to_datetime('today')-data['DealDateTime']
data['DateDiff'] = data.DateDiff.dt.days
# 根据用户ID分组,计算用户最近的消费近度
R_Date = data.groupby(by=['CustomerID'])['DateDiff'].agg({'Recency':numpy.min})
# 根据订单号来计算用户最近的消费次数
F_Date = data.groupby(by=['CustomerID'])['OrderID'].agg({'Frequency':numpy.size})
# 根据Sales来计算用户的消费金额
M_Date = data.groupby(by=['CustomerID'])['Sales'].agg({'Monetary':numpy.sum})
# 用join函数将三个DateFrame整理成一个,注意,join函数对象必须是DateFrame,不能是Series
RFM_Agg = R_Date.join(F_Date).join(M_Date)
# 接下来计算得分,因为每列均是连续数值,因此需要先分5组,然后对每一组赋予一个得分
# 计算近度得分
bins = RFM_Agg.Recency.quantile(q=[0,0.2,0.4,0.6,0.8,1],interpolation='nearest')
# bins[0] = 0是为了防止左边不闭合,最小值取不到
bins[0] = 0
labels = [5,4,3,2,1]
RFM_Agg['R_S'] = pandas.cut(RFM_Agg.Recency,bins,labels=labels)
# 计算交易次数得分
bins = RFM_Agg.Frequency.quantile(q=[0,0.2,0.4,0.6,0.8,1],interpolation='nearest')
bins[0] = 0
labels = [1,2,3,4,5]
RFM_Agg['F_S'] = pandas.cut(RFM_Agg.Frequency,bins,labels=labels)
# 计算交易金额得分
bins = RFM_Agg.Monetary.quantile(q=[0,0.2,0.4,0.6,0.8,1],interpolation='nearest')
bins[0] = 0
labels = [1,2,3,4,5]
RFM_Agg['M_S'] = pandas.cut(RFM_Agg.Monetary,bins,labels=labels)
# 计算RFM
RFM_Agg['RFM'] = 100 * RFM_Agg.R_S.astype(int) + 10 * RFM_Agg.F_S.astype(int) + RFM_Agg.M_S.astype(int)
# RFM根据各项分数高低可以分为8项
bins = RFM_Agg.RFM.quantile(q=[1,0.125,0.250,0.375,0.500,0.625,0.750,0.875,1],interpolation='nearest')
bins[0] = 0
labels = [1,2,3,4,5,6,7,8]
RFM_Agg['level'] = pandas.cut(RFM_Agg.RFM,bins,labels=labels)
RFM_Agg = RFM_Agg.reset_index()
RFM_Agg.sort_values(['level','RFM'],ascending=[1,1])
# 查看每个level的人数
num = RFM_Agg.groupby(by=['level'])['CustomerID'].agg(numpy.size)
记DataFrame.quantile(self, q=0.5, axis=0, numeric_only=True, interpolation=‘linear’)分位数函数。
参数说明:
q:浮点型或数组,默认为0.5。取值在[0,1]之间。axis:{0,1,'index','columns'}。0和index表示按行,1和columns表示按列。numeric_only:布尔值,默认为True。如果False,datetime和timedelta数据的分位数也会被计算。interpolation:{‘linear’, ‘lower’, ‘higher’, ‘midpoint’, ‘nearest’}
linear: i + (j - i) * fraction, where fraction is the fractional part of the index surrounded by i and j.
lower: i.
higher: j.
nearest: i or j 取最近
midpoint: (i + j) / 2.
New in version 0.18.0.
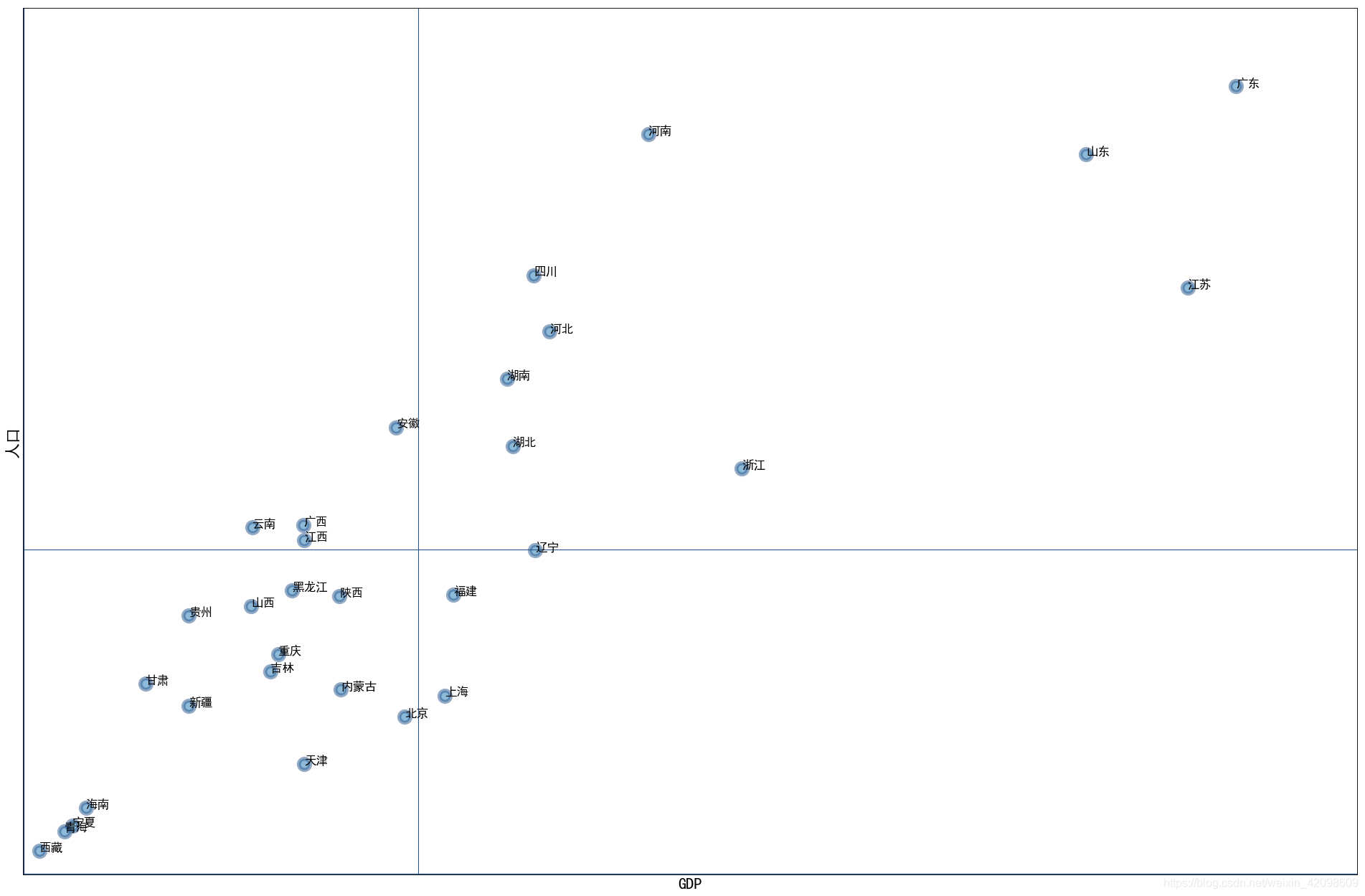
矩阵分析
矩阵分析,是指根据事物(如产品、服务等)的两个重要属性(指标)作为分析的依据,进行关联分析,找出解决问题的一种分析方法。矩阵分析法在解决问题和资源分配时,为决策者提供重要的参考依据。先解决主要矛盾,再解决此要矛盾,有利于提高工作效率,有利于决策者进行资源的优化配置。
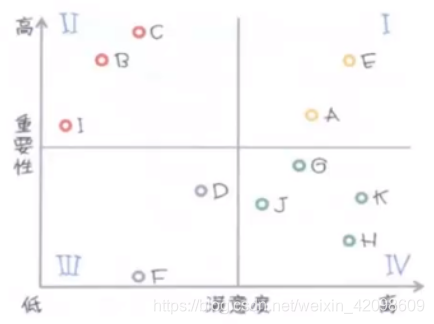
举例
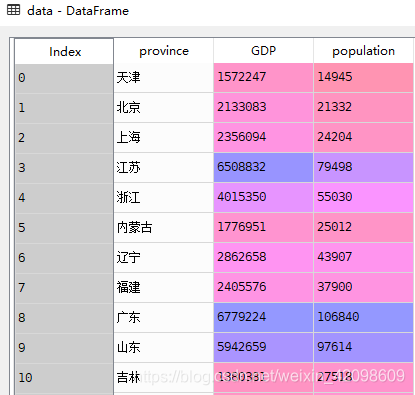
原始数据包含三个变量:province,GDP和population。矩阵分析代码如下:
# -*- coding: utf-8 -*-
import pandas
import matplotlib
import matplotlib.pyplot as plt
data = pandas.read_csv('D://Data Analysis//5.8//data.csv')
# 设置显示的颜色
mainColor = (42/256, 87/256, 141/256, 1)
# 设置字体
font = {
'family':'SimHei',
'size':20}
matplotlib.rc('font',**font)
# 设置画布大小
fig = plt.figure(figsize=(30,20),dpi=80)
#111表示第一行第一列,并且当且操作第一个子图
sp = fig.add_subplot(111)
# 设置x轴和y轴的范围,将范围设置为最大值的1.1倍,显示时比较清晰
sp.set_xlim([0,data.GDP.max()*1.1])
sp.set_ylim([0,data.population.max()*1.1])
# 这里不要坐标的刻度值,因此可以关闭
# sp.axis('off')
sp.get_xaxis().set_ticks([])
sp.get_yaxis().set_ticks([])
# 画点
sp.scatter(
data.GDP,data.population,
alpha=0.5,s=200,marker='o',
edgecolors=mainColor,linewidths=5)
# 画均值线
sp.axvline(
x = data.GDP.mean(),
linewidth=1,color=mainColor)
sp.axhline(
y = data.population.mean(),
linewidth=1,color=mainColor)
sp.axvline(
x = 0,
linewidth=3,color=mainColor)
sp.axhline(
y = 0,
linewidth=3,color=mainColor)
# 设置坐标轴名称
sp.set_xlabel('GDP')
sp.set_ylabel('人口')
# 画标签
data.apply(
lambda row: plt.text(
row.GDP,
row.population,
row.province,
fontsize=15),axis=1)
plt.show()
输出:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









