







多层感知机的基本介绍
课程讲解的十分详尽,这里就简记一下知识点。
下图展示了一个多层感知机的神经网络图,它含有一个隐藏层,该层中有5个隐藏单元。
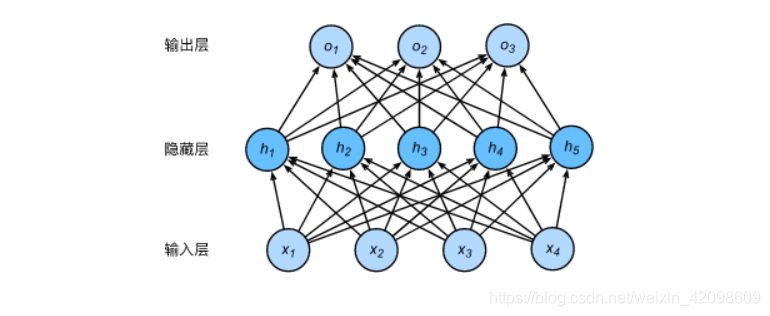
含单隐藏层的多层感知机,其输出
O
n
×
q
O^{n\times q}
On×q计算为(
n
n
n是批量大小,
q
q
q是输出类别数):
H
=
X
W
h
+
b
h
H=XW_h+b_h
H=XWh+bh
O = H W o + b o O=HW_o+b_o O=HWo+bo
联立起来得
O
=
(
X
W
h
+
b
h
)
W
o
+
b
o
=
X
W
h
W
o
+
b
h
W
o
+
b
o
O=(XW_h+b_h)W_o+b_o=XW_hW_o+b_hW_o+b_o
O=(XWh+bh)Wo+bo=XWhWo+bhWo+bo
不难看出,输出与输入特征仍为线性关系,事实上,即便再添加更多的隐藏层,以上设计依然只能与仅含输出层的单层神经网络等价。
激活函数
激活函数引入了非线性变换。
这里有三种激活函数:relu函数、sigmoid函数以及tanh函数。
relu函数:
R
e
L
U
(
x
)
=
m
a
x
(
x
,
0
)
ReLU(x) = max(x,0)
ReLU(x)=max(x,0)
sigmoid函数:
s
i
g
m
o
i
d
(
x
)
=
1
1
+
exp
(
−
x
)
sigmoid(x)=\frac{1}{1+\exp(-x)}
sigmoid(x)=1+exp(−x)1
由此可见,sigmoid函数取值在[0,1]之间。
sigmoid导数:
s
i
g
m
o
i
d
′
(
x
)
=
s
i
g
m
o
i
d
(
x
)
(
1
−
s
i
g
m
o
i
d
(
x
)
)
sigmoid'(x)=sigmoid(x)(1-sigmoid(x))
sigmoid′(x)=sigmoid(x)(1−sigmoid(x))
tanh函数:
t
a
n
h
(
x
)
=
1
−
exp
(
−
2
x
)
1
+
exp
(
−
2
x
)
=
2
1
+
exp
(
−
2
x
)
−
1
tanh(x)=\frac{1-\exp(-2x)}{1+\exp(-2x)}=\frac{2}{1+\exp(-2x)}-1
tanh(x)=1+exp(−2x)1−exp(−2x)=1+exp(−2x)2−1
由此可见,tanh函数取值在[-1,1]之间。
tanh函数导数:
t
a
n
h
′
(
x
)
=
1
−
t
a
n
h
2
(
x
)
tanh'(x)=1-tanh^2(x)
tanh′(x)=1−tanh2(x)
它是关于原点对称的。
关于激活函数的选择
ReLu函数是一个通用的激活函数,目前在大多数情况下使用。但是,ReLU函数只能在隐藏层中使用。
用于分类器时,sigmoid函数及其组合通常效果更好。由于梯度消失问题,有时要避免使用sigmoid和tanh函数(因为它们的梯度在[0,1]之间)。
在神经网络层数较多的时候,最好使用ReLu函数,ReLu函数比较简单计算量少,而sigmoid和tanh函数计算量大很多。
在选择激活函数的时候可以先选用ReLu函数如果效果不理想可以尝试其他激活函数。
多层感知机代码解读
多层感知机就是含有至少一个隐藏层的由全连接层组成的神经网络,且每个隐藏层的输出通过激活函数进行变换。
H
=
Φ
(
X
W
h
+
b
h
)
H=\Phi(XW_h+b_h)
H=Φ(XWh+bh)
O = H W o + b o O=HW_o+b_o O=HWo+bo
从零开始实现需自己定义网络
def net(X):
X = X.view((-1, num_inputs))
#隐藏层输出
H = relu(torch.matmul(X, W1) + b1)
return torch.matmul(H, W2) + b2
torch.matmul(tensor1,tensor2,out=None)
torch.mm(mat1,mat2,out=None)
二者之间的区别从输入参数上就可以看出。
利用PyTorch实现时
net = nn.Sequential(
# FlattenLayer是在数据输入前进行维度变换
d2l.FlattenLayer(),
nn.Linear(num_inputs, num_hiddens),
nn.ReLU(),
nn.Linear(num_hiddens, num_outputs),
)
其他函数
- detch()函数:简而言之就是将参数从网络中隔离开来,不再参与更新。一个简单的示例摘自慢行厚积:
import torch
a = torch.tensor([1, 2, 3.], requires_grad=True)
print(a.grad)
out = a.sigmoid()
print(out)
#添加detach(),c的requires_grad为False
c = out.detach()
print(c)
#这时候没有对c进行更改,所以并不会影响backward()
out.sum().backward()
print(a.grad)
output:
None
tensor([0.7311, 0.8808, 0.9526], grad_fn=<SigmoidBackward>)
tensor([0.7311, 0.8808, 0.9526])
tensor([0.1966, 0.1050, 0.0452])


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









