









目录
1 背景
得益于flash-attention对于MHA(Multi Head Attention)计算的加速优化,使得LLM训练和推理的性能都获得了极大地提升。Tri Dao在Flash Attention v2的基础上又专门写了Flash Decoding来优化推理,主要修改了block划分方法,使用多个block来处理相同的注意力头,实现KV Cache的并行化加载,最后发射一个单独的kernel来重新缩放和合并结果。因此在小batch和超长序列情况下,Flash Decoding的推理性能提升很大。
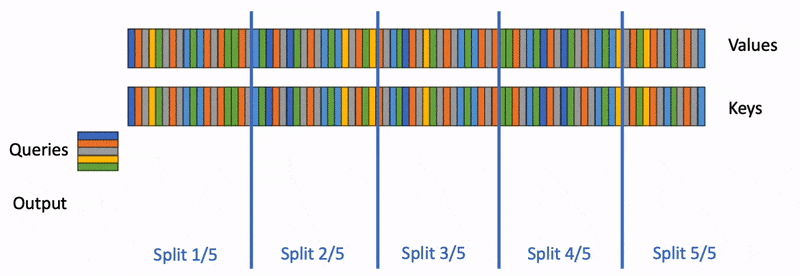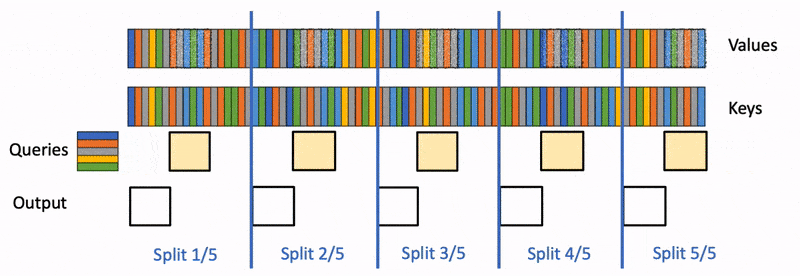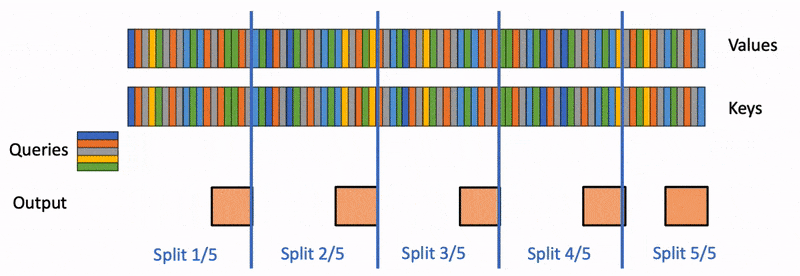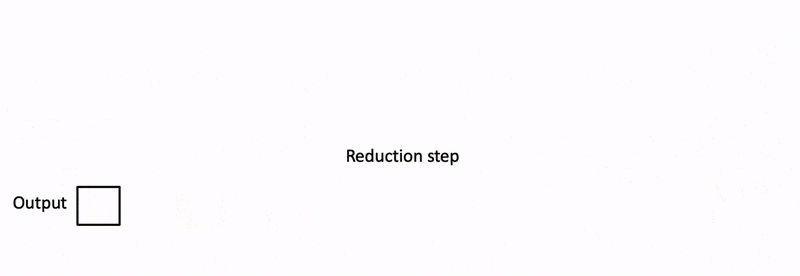
然而Flash Attention应用于LLM推理,依然会存在如下问题:
-
Decoding阶段Tensor Core利用率低,以Ampere架构(NVIDIA A100、RTX3090等)为例,Tensor Core利用率只有1 / 16
-
只支持FP16和BF16数据类型,不支持FP8、Int8、Int4等量化算法,不利于降低推理成本
-
只支持通用Attention,不支持ALiBi等变种Attention
由于LLM推理Decoding阶段的seq_q始终是1,所以MHA每个头注意力的计算流程简化为两个HGEMV和一个Softmax,示意图如下。
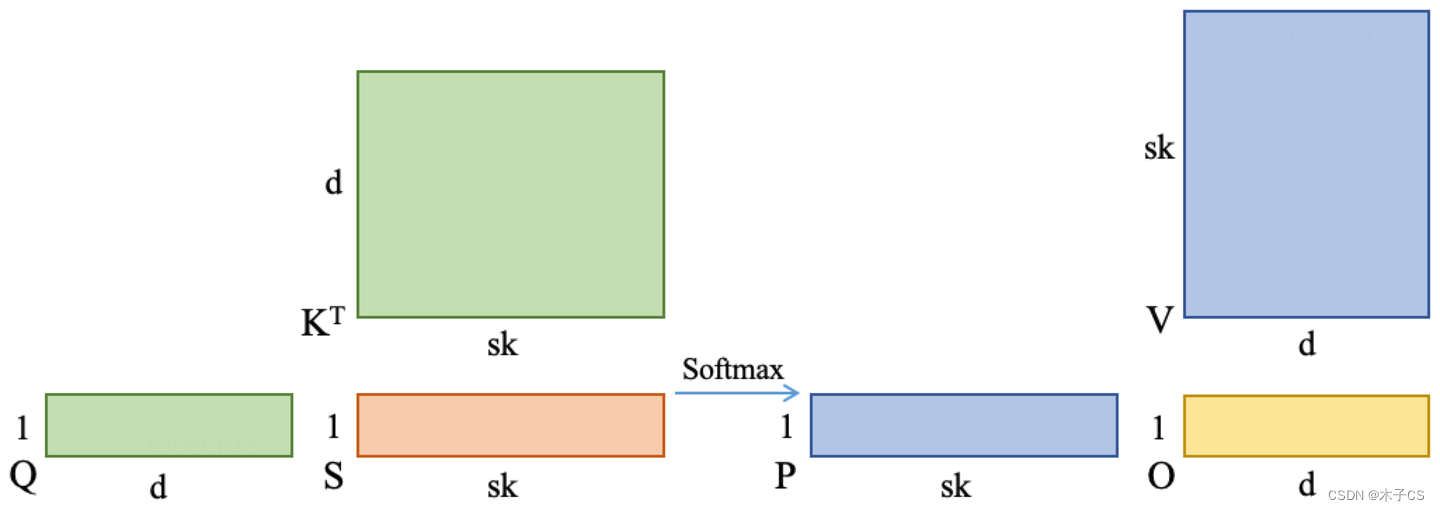
注意到RTX3090在FP32乘累加的情况下,Tensor Core FP16算力只有CUDA Core FP32算力的2倍,这种情况下,使用手写CUDA Core Kernel来计算Decoding MHA,在保证精度的同时,无论是延迟还是硬件利用率都会取得一定的收益。另一方面,手写Decoding MHA Kernel不仅方便进一步采用KV Cache量化方法提升LLM推理的吞吐性能,进而降低推理成本,也可以支持更多的变种Attention(如ALiBi等)。
2 结果
本文主要参考ppl.llm.kernel.cuda和flash-attention,使用CUDA Core优化MHA在LLM推理Decoding阶段的性能。目前在部分推理Decoding场景下,Decoding Attention的性能优于Flash Decoding(Flash Attention)和FlashInfer。Decoding Attention支持GQA(Group Query Attention)/ MQA(Multi Query Attention)和ALiBi(Attention with Linear Biases)推理场景,支持FP16和BF16数据类型。Decoding Attention提供了C++ API和Python API,代码开源在decoding_attention。
2.1 测试条件
-
MHA:O = Softmax(Q * K^T) * V
-
CUDA:12.1
-
GPU:RTX3090
-
Flash Attention:v2.6.3
-
FlashInfer:v0.1.6
-
Head Num:32
-
Head Dim:128
-
Data Type:FP16
2.2 设备规格
RTX3090的设备规格如下。
| Graphics Card | RTX3090 |
|---|---|
| GPU Codename | GA102 |
| GPU Architecture | Ampere |
| GPCs | 7 |
| TPCs | 41 |
| SMs | 82 |
| CUDA Cores / SM | 128 |
| CUDA Cores / GPU | 10496 |
| Tensor Cores / SM | 4 (3rd Gen) |
| Tensor Cores / GPU | 328 (3rd Gen) |
| GPU Boost Clock (MHz) | 1695 |
| Peak FP32 TFLOPS | 35.6 |
| Peak FP16 TFLOPS | 35.6 |
| Peak FP16 Tensor TFLOPS | 142 |
| Peak FP16 Tensor TFLOPS | 71 |
| Memory Interface | 384-bit |
| Memory Clock (Data Rate) | 19.5 Gbps |
| Memory Bandwidth | 936 GB/sec |
| L1 Data Cache/Shared Memory | 10496 KB |
| L2 Cache Size | 6144 KB |
| Register File Size | 20992 KB |
2.3 RTX3090
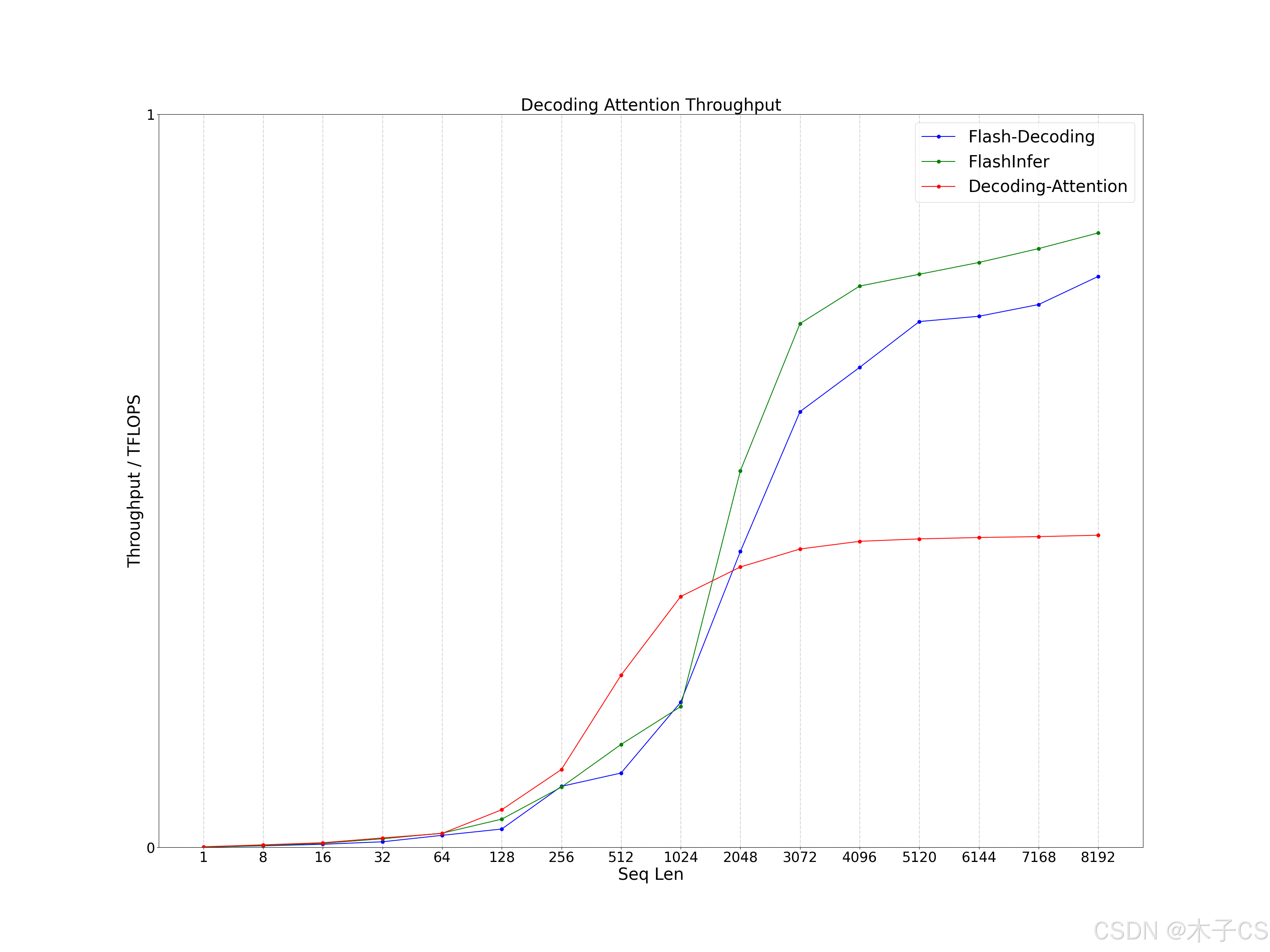
(1)Seq Len
序列长度小于1536时,Decoding Attention的性能优于Flash Decoding(Flash Attention)和FlashInfer;序列长度大于1536时,Flash Decoding(Flash Attention)和FlashInfer的性能更优。
-
Batch Size:1
-
Seq Q:1
-
Seq K:Seq Len
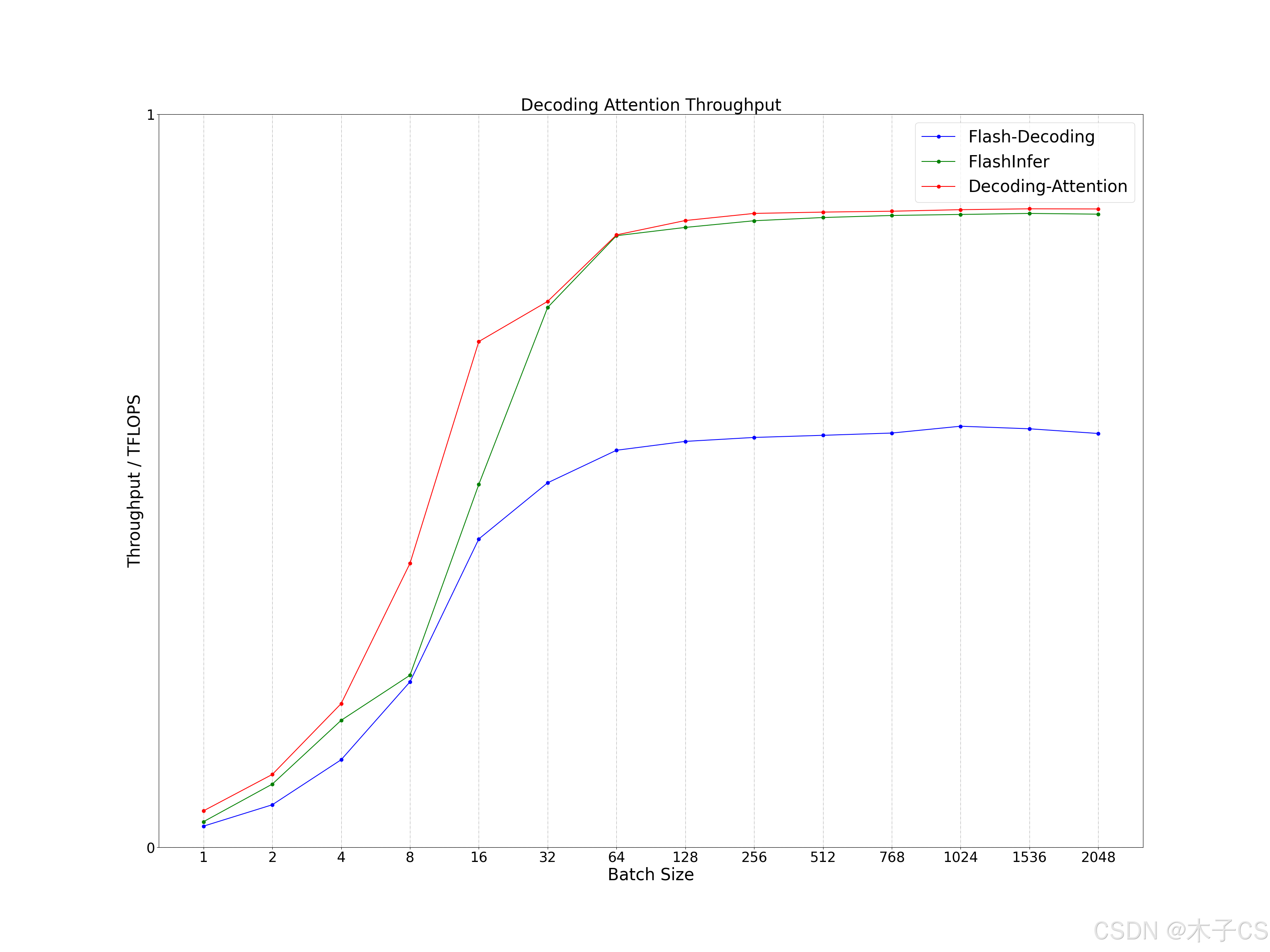
(2)Batch Size
Batch Size无论大小,Decoding Attention性能都要优于Flash Decoding(Flash Attention)和FlashInfer。
-
Batch Size:Batch Size
-
Seq Q:1
-
Seq K:128
3 Decoding Attention
如上所述,LLM推理Decoding阶段的seq_q始终是1,所以MHA每个头注意力的计算流程简化为两个HGEMV和一个Softmax。Decoding Attention按batch和head划分block,Kernel主要分为三个部分,即HGEMV(S = Q * K^T)、Softmax(P = Softmax(S))和HGEMV(O = P * V),源码在decoding_attention。
3.1 HGEMV(S = Q * K^T)
每个Group处理一个或多个seqlen_k,计算流程与HGEMV一致,可参考开源代码cuda_hgemv。
// S = Q * K^T
T RQ[thread_elem_nums];
#pragma unroll
for (size_t i = 0; i < thread_iters; ++i) {
*(int4 *)(&RQ[i * thread_copy_elem_nums]) =
*(int4 *)(&q_ptr[binfo.q_offset(params.q_row_stride, params.q_head_stride,
(i * threads_per_group + group_lane_id) * thread_copy_elem_nums)]);
}
extern __shared__ float S_smem[];
float S_max = -std::numeric_limits<float>::max();
#pragma unroll
for (size_t base_seq_k = warp_id * groups_per_warp; base_seq_k < binfo.actual_seq_k;
base_seq_k += groups_per_block) {
size_t seq_k = base_seq_k + group_id;
T RK[thread_elem_nums];
float acc = 0.0;
if (seq_k < binfo.actual_seq_k) {
#pragma unroll
for (size_t i = 0; i < thread_iters; ++i) {
*(int4 *)(&RK[i * thread_copy_elem_nums]) =
*(int4 *)(&k_ptr[binfo.k_offset(seq_k, params.k_row_stride, params.k_head_stride,
(i * threads_per_group + group_lane_id) * thread_copy_elem_nums)]);
}
#pragma unroll
for (size_t i = 0; i < thread_elem_nums; ++i) {
if constexpr (std::is_same_v<T, half>) {
acc += (__half2float(RQ[i]) * __half2float(RK[i]));
} else {
acc += (__bfloat162float(RQ[i]) * __bfloat162float(RK[i]));
}
}
}
#pragma unroll
for (size_t i = threads_per_group / 2; i >= 1; i /= 2) {
acc += __shfl_xor_sync(shfl_mask, acc, i);
}
if (group_lane_id == 0 && seq_k < binfo.actual_seq_k) {
acc *= params.scale_softmax;
if (IsAlibi) {
acc += (binfo.h_slope * (static_cast<int>(seq_k) - binfo.actual_seq_q - binfo.row_shift));
}
S_smem[seq_k] = acc;
S_max = fmaxf(acc, S_max);
}
}3.2 Softmax(P = Softmax(S))
首先根据上一步计算得到的每个Group中S的最大值进行Reduce,得到一行中S的最大值,然后在S_smem上计算每个seqlen_k对应的Softmax。
// P = Softmax(S)
__shared__ float softmax_smem[warps_per_block];
#pragma unroll
for (size_t i = warp_size / 2; i >= 1; i /= 2) {
S_max = fmaxf(S_max, __shfl_xor_sync(shfl_mask, S_max, i));
}
if (lane_id == 0) {
softmax_smem[warp_id] = S_max;
}
__syncthreads();
if (lane_id < warps_per_block) {
S_max = softmax_smem[lane_id];
} else {
S_max = -std::numeric_limits<float>::max();
}
#pragma unroll
for (size_t i = warps_per_block / 2; i >= 1; i /= 2) {
S_max = fmaxf(S_max, __shfl_xor_sync(shfl_mask, S_max, i));
}
S_max = __shfl_sync(shfl_mask, S_max, 0);
float exp_sum = 0.0;
#pragma unroll
for (size_t seq_k = threadIdx.x; seq_k < binfo.actual_seq_k; seq_k += threads_per_block) {
S_smem[seq_k] -= S_max;
S_smem[seq_k] = exp(S_smem[seq_k]);
exp_sum += S_smem[seq_k];
}
#pragma unroll
for (size_t i = warp_size / 2; i >= 1; i /= 2) {
exp_sum += __shfl_xor_sync(shfl_mask, exp_sum, i);
}
if (lane_id == 0) {
softmax_smem[warp_id] = exp_sum;
}
__syncthreads();
if (lane_id < warps_per_block) {
exp_sum = softmax_smem[lane_id];
}
#pragma unroll
for (size_t i = warps_per_block / 2; i >= 1; i /= 2) {
exp_sum += __shfl_xor_sync(shfl_mask, exp_sum, i);
}
exp_sum = __shfl_sync(shfl_mask, exp_sum, 0);
#pragma unroll
for (size_t seq_k = threadIdx.x; seq_k < binfo.actual_seq_k; seq_k += threads_per_block) {
S_smem[seq_k] /= exp_sum;
}
__syncthreads();3.3 HGEMV(O = P * V)
由于V矩阵存储的特殊性,此处每个Group计算V中每一行或多行的外积,然后Reduce Sum得到最终结果。
// O = P * V
T RV[thread_elem_nums];
float RO[thread_elem_nums];
memset(RO, 0, sizeof(RO));
#pragma unroll
for (size_t base_seq_k = warp_id * groups_per_warp; base_seq_k < binfo.actual_seq_k;
base_seq_k += groups_per_block) {
size_t seq_k = base_seq_k + group_id;
if (seq_k < binfo.actual_seq_k) {
#pragma unroll
for (size_t i = 0; i < thread_iters; ++i) {
*(int4 *)(&RV[i * thread_copy_elem_nums]) =
*(int4 *)(&v_ptr[binfo.k_offset(seq_k, params.v_row_stride, params.v_head_stride,
(i * threads_per_group + group_lane_id) * thread_copy_elem_nums)]);
}
#pragma unroll
for (size_t i = 0; i < thread_elem_nums; ++i) {
if constexpr (std::is_same_v<T, half>) {
RO[i] += (S_smem[seq_k] * __half2float(RV[i]));
} else {
RO[i] += (S_smem[seq_k] * __bfloat162float(RV[i]));
}
}
}
}
#pragma unroll
for (size_t i = 0; i < thread_elem_nums; ++i) {
#pragma unroll
for (size_t j = threads_per_group; j <= warp_size / 2; j *= 2) {
RO[i] += __shfl_xor_sync(shfl_mask, RO[i], j);
}
}
__syncthreads();
#pragma unroll
for (size_t i = threadIdx.x; i < head_dim; i += threads_per_block) {
S_smem[i] = 0.0;
}
__syncthreads();
if (lane_id < threads_per_group) {
#pragma unroll
for (size_t i = 0; i < thread_iters; ++i) {
#pragma unroll
for (size_t j = 0; j < thread_copy_elem_nums; ++j) {
atomicAdd(S_smem + (i * threads_per_group + lane_id) * thread_copy_elem_nums + j,
RO[i * thread_copy_elem_nums + j]);
}
}
}
__syncthreads();
#pragma unroll
for (size_t i = threadIdx.x; i < head_dim; i += threads_per_block) {
if constexpr (std::is_same_v<T, half>) {
o_ptr[binfo.q_offset(params.o_row_stride, params.o_head_stride, i)] = __float2half(S_smem[i]);
} else {
o_ptr[binfo.q_offset(params.o_row_stride, params.o_head_stride, i)] = __float2bfloat16(S_smem[i]);
}
}4 其他
4.1 计划
- Kernel优化
- KV Cache量化:FP8、Int8、Int4



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









