




 本文详细介绍了CNN模型中反向传播的过程,从全连接层、激活层到损失函数的计算,通过链式法则求解权重梯度,并使用梯度下降法更新权重。讲解了误差的定义及其在网络训练中的作用,帮助理解深度学习中参数优化的原理。
本文详细介绍了CNN模型中反向传播的过程,从全连接层、激活层到损失函数的计算,通过链式法则求解权重梯度,并使用梯度下降法更新权重。讲解了误差的定义及其在网络训练中的作用,帮助理解深度学习中参数优化的原理。
看这篇文章,看官需要了解常规CNN模型的结构,并且了解结构下的各层计算逻辑。
OK,我们这次对CNN从全连接层到计算损失函数大致三个阶段进行推导和分析。
全连接层——激活层(一般只把它看做一个函数,但是其实keras里面把它作为一个层)——输出层(计算损失)
1、假设全连接层的输入(即上一层的输出)为x,全连接层的权重参数(神经元)为w,则全连接层的输出为

这个过程是一个矩阵的乘法运算。那为了计算的方便,我们就以两个变量举例,则全连接层输出为:

2、激活层的激活函数我们用relu,然后对于X的负轴方向我们不需要考虑,因为都是0嘛,那怎么计算都是0。假设正轴部分是y=kx,即斜率为k的x轴正向直线部分。于是
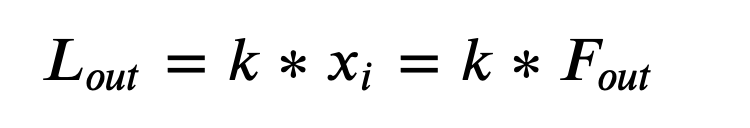
这里的x就是上一层的输出,即F
3、损失函数我们选用平方损失函数,写起来简单一些,并且假设只有一个输出。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 759
759

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









