






EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks
EDA包括四种简单但很有效的操作:同义词替换、随机插入、随机转换、随机删除。
这种方法在CNN和LSTM-RNN网络中都有很好的表现。
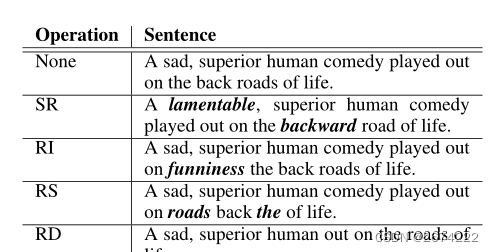
- synonym replacement ,随机选择n个非停用词从他的同义词中随机选择进行替换;
- random insertion ,从非停用词中随机选择这个词的同义词,在句子中的任意位置进行插入,重复n次;
- random swap 随机在句子中选择2个词并交换他们的位置,重复n次;
- random deletion,以概率P随机删除句子中的每个词;
*注:SR、RI、RS中的n代表着一个句子中要改变的单词个数,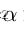 代表每个单词在句子中会被改变的概率,l是句子的长度。
代表每个单词在句子中会被改变的概率,l是句子的长度。
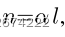
在RD中,p=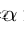
实验
本文是基于五个基准文本分类任务和两个网络模型去评估EDA的。
-
SST-2 (Stanford Senti-ment Treebank)五分类问题
数据介绍以及Python处理地址:https://www.jianshu.com/p/6c23c6b85cf3 -
CR(customer reviews)
-
SUBJ(subjectivity/objectivity dataset) 二分类问题
数据集获取链接:https://www.cs.cornell.edu/home/llee/data/search-subj.html
数据集简介:
$ann_label: 0到3之间的数字。这是由注释者分配的原始标签;它被贴上了标签根据以下约定
关于四级分类方案):
0.单一的审查
1.多个评论
2.回顾和客观信息的结合
3.目标文件
$ exp_label:{主题| obj}
为了实验目的,我们随后将这四个类拆分分为subj(“主观”)和obj(“客观”)两类,其中“主观”类别涵盖了四种原创中的前三种标签。 -
TREC(question type dataset)该数据集包含9000多条问句,标注有6个类别,包括人物、地点、数量、方式、时间和原因,可用于训练短文本问题分类模型
TrecQA原始数据如下:
https://trec.nist.gov/data/qa/2017_LiveQA/med-qs-and-reference-answers.xml

标记数据如下:
标记数据连接 https://github.com/castorini/data/blob/master/TrecQA/data
-
PC (Pro-Con dataset)
实验数据集分析
共同点:
五个数据集都是情感分析类
数据格式都是
(label,sentence)/(sentence,label)
不同点:
SST-2是五分类问题,其他都是二分类问题
SUBJ是主客观情感分类
总结
在关系抽取中,我们的数据集是1对1 的形式,但是文本增强的数据集是多对1的形式,此外我们的数据集要保证标签与标签之间存在关系以及连续性,但是文本增强的数据集的标签之间是独立的。
经过分析发现,可能文本增强不适合我们这类型的seq-seq模型,同时经过查阅部分关系抽取以及知识图谱构建的文献发现,在关系抽取任务中,基本不进行文本增强。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











