



一、Learning structured sparsity in deep neural network

Abstract:
本文提出了Structured Sparsity Learning(ssl)方法来正则化DNN的网络结构。ssl技术可以做到1)从一个复杂的DNN网络学习到一个紧凑的结构,从而减少计算消耗;2)在保证精度不损失的情况下,获得一个对硬件友好的DNN稀疏结构。实验表明SSL的稀疏结构使得alexnet网络在CPU和GPU计算平台获得了5.1倍和3.1倍的计算加速。3)正则化DNN结构提升分类精度,实验表明:对于CIFAR-10数据集,正则化可以将ResNet从20层减少到18层,分类精度从91.25到92.60,以上精度都高于原始的ResNet网络;对于AlexNet减少了1%的错误率。
1 introduction:

为了减少计算量:目前主要从以下几个方面从事研究工作:正则稀疏化、网络剪枝、低秩近似(分解)
相关引用论文:
- Misha Denil, Babak Shakibi, Laurent Dinh, Marc' Aurelio Ranzato, and Nando de Freitas. Predicting
parameters in deep learning. In Advances in Neural Information Processing Systems, pages 2148–2156.
2013. - Emily L Denton, Wojciech Zaremba, Joan Bruna, Yann LeCun, and Rob Fergus. Exploiting linear structure
within convolutional networks for efficient evaluation. In Advances in Neural Information Processing
Systems, pages 1269–1277. 2014 - Max Jaderberg, Andrea Vedaldi, and Andrew Zisserman. Speeding up convolutional neural networks with
low rank expansions. arXiv preprint arXiv:1405.3866, 2014. - Yani Ioannou, Duncan P. Robertson, Jamie Shotton, Roberto Cipolla, and Antonio Criminisi. Training
cnns with low-rank filters for efficient image classification. arXiv preprint arXiv:1511.06744, 2015. - Cheng Tai, Tong Xiao, Xiaogang Wang, and Weinan E. Convolutional neural networks with low-rank
regularization. arXiv preprint arXiv:1511.06067, 2015. - Ming Yuan and Yi Lin. Model selection and estimation in regression with grouped variables. Journal of
the Royal Statistical Society. Series B (Statistical Methodology), 68(1):49–67, 2006.
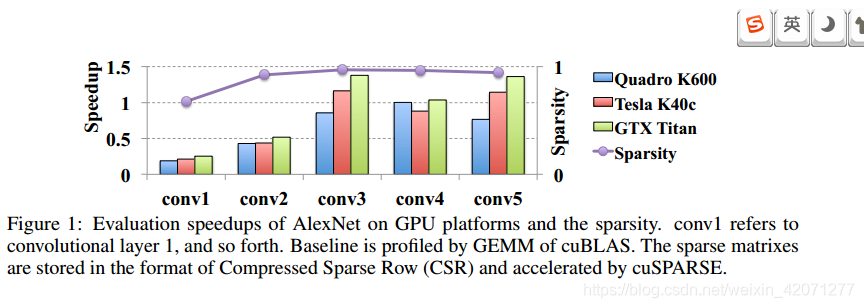
然而正则稀疏化和网络剪枝会产生一个非结构化得DNN网络连接,这会导致不规则的内存访问,会影响部署在硬件平台的网络精度。下图显示了 非结构化稀疏操作对alexnet的每一层的实际加速效果。对比原始模型这种方法带来了2%的精度损失。因为分散的权值分布,实际的加速效果大大的受限,当稀疏率很高的情况下(>95%)加速效果为负。
低秩近似的方法是在训练得到权重矩阵,训练的到的权重向量倍分解和近似为多个小元素的乘积。之后在进行fine-tuning来保持网络的精度。低秩近似方法提升了速度是因为他权衡了参数的稠密度与权重的分布之间的关系,但是这种方法计算复杂度太高。
作者得到的启发:1)DNN中filter和channel个数是存在冗余的2)我们常把filter的尺寸规定为正方体,但是这种filter的形状理论上是不固定的,或许可以改变卷积核的形状从而进行模型压缩3)训练过程中通过group Lasso regularization压缩模型深度,SLL可调整每一个层的滤波器的形状,通道数,滤波器的结构,还可以跨层的调整网络深度。SLL既可以加速有课以减少模型大小还可以改善准确率。
2、Related works

网络剪枝:Deep compression中介绍了相关的剪枝方法,模型的大小已经被极大的缩小了,但是并没有加速(分散的权值分布、存储)。由于卷积层才是计算的瓶颈,因此压缩卷积层是非常必要的。
低秩近似:denil 预测DNN中有95%的参数都是冗余的
SSL的贡献:
1)SLL可以动态的最优化DNN网络结构的稀疏性,而且只需要一个超参数、不需要重复计算
2)SLL可以相应的减少层深度
3)SLL有低秩近似
模型的结构学习:Group lasso是一种有效的正则化方法,可以得到稀疏化结构。本文使用Group lasso从filter number channel 和dlayer deep多个维度稀疏化模型。
3、结构稀疏化学习方法
3.1 一般结构的结构稀疏化方法
关键字:group lasso
3.2、Structured sparsity learning for structures of filters, channels, filter shapes and depth????
3.3、Structured sparsity learning for computationally efficient structures
名词解析:GEMM(通用矩阵乘法)
BLAS:Basic Linear Algebra Subprograms

















 4686
4686

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









