







附:课程链接
第六讲.全连接网络实践
6.1输入手写数字图片输出识别结果
由于个人使用Win7系统,并未完全按照课程所讲,以下记录的也基本是我的结合课程做的Windows系统+PyCharm操作。且本人有python基础,故一些操作可能简略。并未完全按照网课。
记住编写代码时,除注释内容外,字符均使用英文格式。
本节目标:
1、实现断点续训
2、输入真实图片,输出预测结果
3、制作数据集,实现特定应用
一、断点续训:
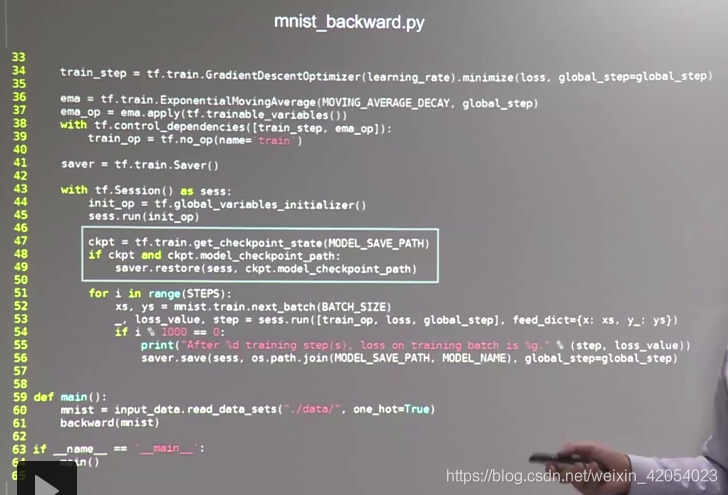
关键处理:在反向传播的with结构中加上加载ckpt的操作,如果ckpt存在,则用saver.restore把ckpt恢复到当前会话。即加入:
ckpt = tf.train.get_checkpoint_state(MODEL_SAVE_PATH)
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess,ckpt.model_checkpoint_path)
注解(来自助教笔记):

ckpt代码所处位置:
这样在训练网络时,不用再担心宿舍断电参数白跑的情况发生了。
再次运行mnist_backward.py时,程序会自动找到断点:

(上一课中我们训练到了49001 training step(s):
 )
)
二、输入真实图片,输出预测结果
目前我们已经学会了全连接网络的设计、mnist数据集的使用,可以成功输入手写数字识别准确率了,但是程序只输出正确率是没有用的,我们希望程序可以实现实际应用——输入一张真实图片,输出预测结果;我们还希望找到图像分类的八股套路。至少当给我们一堆标注过的图片,可以制作出特定数据集以实现特定应用。
目前仍有两个问题亟待解决:
①如何对输入的真实图片,输出预测结果?
②如何制作数据集,实现特定应用?
1、先来看第一个问题:如何对输入的真实图片,输出预测结果
实现过程即:
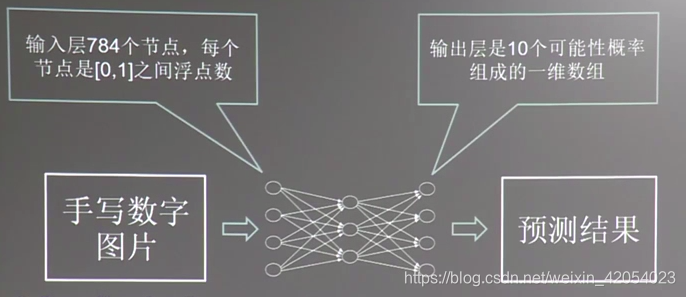
(其中①网络输入:一维数组(784个像素点)

②

③
上述①②③内容均为助教的笔记)
即可将任务分成两个函数解决:

def application():
testNum = input("Input the number of test pictures:")
for i in range(testNum):
testPic = raw_input("the path of test picture:")
"""
先对手写数字图片进行预处理,当图片符合神经网络输入要求后,
再把它喂给复现的神经网络模型,输出预测值
"""
testPicArr = pre_pic(testPic)
preValue = restore_model(testPicArr)
print("The prediction number is:",preValue)
输入图片输出预测值的代码验证中包括以下四个文件:

其中除新增了一个应用程序,另外三个程序都跟原来相同。
mnist_app.py:
import tensorflow as tf
import numpy as np
from PIL import Image
import mnist_backward
import mnist_forward
def restore_model(testPicArr):
with tf.Graph().as_default() as g: #重现计算图
x = tf.placeholder(tf.float32, [None, mnist_forward.INPUT_NODE]) #给输入x占位
y = mnist_forward.forward(x, None) #计算求得输出y
preValue = tf.argmax(y,1) #y的最大值对应的列表索引号就是预测结果preValue
#实例化带有滑动平均值的saver
variable_averages = tf.train.ExponentialMovingAverage(mnist_backward.MOVING_AVERAGE_DECAY)
variable_to_restore = variable_averages.variables_to_restore()
saver = tf.train.Saver(variable_to_restore)
with tf.Session() as sess:
#用with结构加载训练好的模型ckpt,也就是把滑动平均值赋给各个参数
ckpt = tf.train.get_checkpoint_state(mnist_backward.MODEL_SAVE_PATH)
#如果已有ckpt模型则恢复ckpt的参数等信息到当前会话
if ckpt and ckpt.model_checkpoint_path:
#恢复会话
saver.restore(sess,ckpt.model_checkpoint_path)
preValue = sess.run(preValue,feed_dict={x:testPicArr}) #把刚刚准备好的待识别图片喂入网络,执行预测操作
return preValue
#如果没有模型ckpt
else:
print('No checkpoint file found') #模型不存在提示
return -1
#这样我们就得到了预测结果,返回application()
#预处理函数,包括resize、转变灰度图、二值化操作
def pre_pic(picName):
img = Image.open(picName) #打开传入的原始图片,变量名为img
reIm = img.resize((28,28),Image.ANTIALIAS) #保证图片符合模型的尺寸要求,把img给resize为28*28像素
#Image.ANTIALIAS表示用消除锯齿的方法来resize
im_arr = np.array(reIm.convert('L')) #resize后的图片为im_arr。为符合模型对颜色的要求,将im_arr用convert('L')变为灰度图
#用np.array把im_arr转换为矩阵的形式,赋给im_arr
threshold = 50 #设定合理的阈值
"""
由于模型要求的是黑底白字,而输入的图片是白底黑字,故要给输入图片反色
用嵌套循环遍历每个像素点
"""
for i in range(28):
for j in range(28):
im_arr[i][j] = 255 - im_arr[i][j] #每个像素点的新值 = 255 - 原值,求得互补的反色
#给图片做二值化处理,让图片只有纯白色点和纯黑色点,这样可以滤掉手写数字图片中的噪声,留下图片主要特征
if (im_arr[i][j] < threshold): #小于阈值的点认为是纯黑色0
im_arr[i][j] = 0
else:im_arr[i][j] = 255 #大于阈值的点认为是纯白色255
#也可适当调整阈值,让图像尽量包含手写数字的完整信息。也可尝试其他种处理方法来滤掉噪声
nm_arr = im_arr.reshape([1,784]) #把im_arr整理形状为1行784列,起名为nm_arr
#对于模型要求,像素点是0-1之间的浮点数
nm_arr = nm_arr.astype(np.float32) #先把nm_arr变为浮点型
img_ready = np.multiply(nm_arr,1.0/255.0) #再让现有的RGB图从0-255之间的数变为0-1之间的浮点数
#这样就完成了对图形的预处理操作,符合神经网络对输入特征格式的要求了
return img_ready #整理好的待识别图片。
#函数运行完成,返回到application()
def application():
#用input()可实现从控制台读入数字,用raw_input()可实现从控制台读入字符串
testNum = int(input("Input the number of test pictures:")) #输入要识别几张图片
for i in range(testNum):
testPic = input("the path of test picture:") #给出识别图片的路径和名称
testPicArr = pre_pic(testPic) #把接收到的图片交给pre_pic()做预处理,进入到pre_pic()中
preValue = restore_model(testPicArr) #把整理好的待识别图片喂入神经网络,进入到restore_model()中
print("The prediction number is:",preValue) #打印出预测的结果
"""
程序从main()函数开始执行,在main()中调用了application()
"""
def main():
application()
if __name__ == '__main__':
main()
运行mnist_backward.py,可以看到程序加载了mnist数据集,开始训练模型(仅显示部分):
同时运行mnist_test来检测模型的准确率,准确率随着训练轮数的增加在慢慢提高,当准确率达到稳定的95%以上打开mnist_app.py验证一下,要用真正的手写数字图片来验证结果了!
在课程中老师使用的是助教画好的图片(很好看):
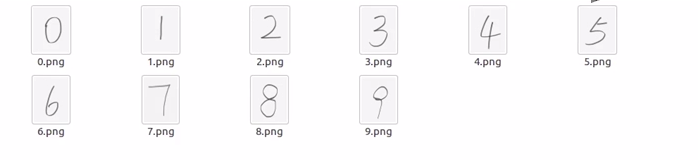
然而我并没有找到这份资料(哭泣),也没有找到看着还行的,所以自己就用电脑自带的“画图”软件做了一回灵魂画手然后截图保存到文件夹pic下,这就是我画的丑图:

(看我画的这么丑,截的图还大小不一,就为我一会识别结果的不准确埋下了伏笔)
运行代码,显示:Input the number of test pictures: 这代表着我们要输入图片个数了,我是0-9共10个,故:Input the number of test pictures:10 。
接着又显示:the path of test picture: ,此时我们要输入文件夹路径和图片名称,比如数字0:the path of test picture: ,接着就成功识别出了图片0:

但不要高兴得太早,让我们继续看几个:
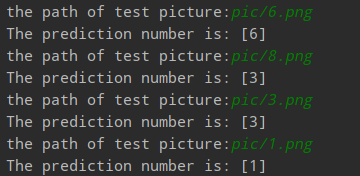
6和1都识别正常,3也是3,但是8却识别成了3。这个我前面说的“伏笔”有关系,因为我截图大小不一,而喂入神经网络的模型需要符合才能喂入,在喂入以前做过像素大小调整等等预处理操作,这样就可能导致3和8reshape后特征值十分相似,这样就导致了误判。(当然这些都是我个人的理解与判断,下次图片做的好看一点就是了。要是不想做好看的图形,那就只能设计一个超强网络啦)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









