







 本文探讨了寻找两个链表首个公共节点的四种方法,包括蛮力法、使用栈、利用长度关系及双指针法,详细解析了每种方法的原理、优缺点及时间空间复杂度。
本文探讨了寻找两个链表首个公共节点的四种方法,包括蛮力法、使用栈、利用长度关系及双指针法,详细解析了每种方法的原理、优缺点及时间空间复杂度。
题目描述:
输入两个链表,找出它们的第一个公共结点。(注意因为传入数据是链表,所以错误测试数据的提示是用其他方式显示的,保证传入数据是正确的)
思路解析:
含有公共节点的两个链表的结构类似于下图中的链表:
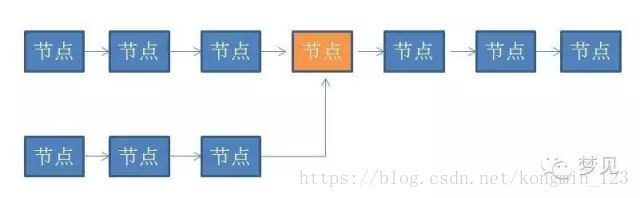
可以看到两个链表中有一个公共节点,其中橙色的节点就是这两个链表的公共节点。
注意单向链表的指针地址是唯一的,所以在第一个共同结点后,之后的节点都是一样的。
思路一、蛮力法:
在第一个链表上顺序遍历每一个节点,每遍历到一个节点,就在第二个链表上顺序遍历每个节点。如果在第二个链表上有一个节点与第一个链表上的节点一样,则说明两个链表在这个节点上重合,于是就找到了他们的公共节点。如果第一个链表的长度为m,第二个链表的长度为n,那么,显然该方法的时间复杂度是O(mn)
思路二:使用栈
通常蛮力法不会是最好的方法,分析有公共节点的两个链表有哪些特点。从链表节点的定义可以看出,这两个链表是单向链表。如果两个单向链表有公共的节点,那么这两个链表从某一节点开始,他们的next都指向同一个节点。但由于是单向链表的节点,每个节点只有一个next,因此从第一个公共节点开始,之后他们的所有节点都是重合的,不可能再出现分叉。所以两个有公共节点而部分重合的链表,其拓扑形状看起来像一个Y,而不可能像一个X,如下图所示。
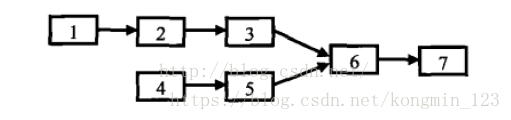
经过分析发现,如果两个链表有公共结点,那么公共结点出现在两个链表的尾部。从两个链表的尾部开始往前比较,那么最后一个相同的结点就是要找的结点。
但是,在单向链表中,只能从头结点开始按顺序遍历,最后才能到达尾节点。尾节点要最先被比较,可以采用“后进先出”的栈结构:分别把两个链表的结点放入两个栈里,这样两个链表的尾节点就位于两个栈的栈顶,接下来比较两个栈顶的结点是否相同。如果相同,则把栈顶弹出接着比较下一个栈顶,直到找到最后一个相同的节点。
需要用两个辅助栈。如果链表的长度分别为m和n,那么空间复杂度是O(m+n)。这种思路的时间复杂度也是O(m+n)。和最开始的蛮力法相比,时间效率得到了提高,相当于是用空间消耗换取了时间效率。
/*
public class ListNode {
int val;
ListNode next = null;
ListNode(int val) {
this.val = val;
}
}*/
import java.util.Stack;
public class Solution {
public ListNode FindFirstCommonNode(ListNode pHead1, ListNode pHead2) {
if(pHead1 == null || pHead2 == null)
return null;
Stack<ListNode> stack1 = new Stack<ListNode>();
Stack<ListNode> stack2 = new Stack<ListNode>();
while(pHead1 != null)
{
stack1.push(pHead1);
pHead1 = pHead1.next;
}
while(pHead2 != null)
{
stack2.push(pHead2);
pHead2 = pHead2.next;
}
ListNode node1 = null, node2 = null;
while(stack1 != null && stack2 != null)
{
while(node1 == node2)
{
node1 = stack1.pop();
node2 = stack2.pop();
}
break;
}
return node1.next;
}
}但是却出现错误?????对这个输入不太懂??三个链表??
答案错误:您提交的程序没有通过所有的测试用例点击对比用例标准输出与你的输出 case通过率为42.86% 用例:
{},{},{1,2,3,4,5} 对应输出应该为: {1,2,3,4,5} 你的输出为:
java.util.EmptyStackException
修改后代码:
/*
public class ListNode {
int val;
ListNode next = null;
ListNode(int val) {
this.val = val;
}
}*/
import java.util.Stack;
public class Solution {
public ListNode FindFirstCommonNode(ListNode pHead1, ListNode pHead2) {
if(pHead1 == null || pHead2 == null)
return null;
Stack<ListNode> stack1 = new Stack<ListNode>();
Stack<ListNode> stack2 = new Stack<ListNode>();
while(pHead1 != null)
{
stack1.push(pHead1);
pHead1 = pHead1.next;
}
while(pHead2 != null)
{
stack2.push(pHead2);
pHead2 = pHead2.next;
}
ListNode node1 = null;
while(!stack1.isEmpty() && !stack2.isEmpty() && stack1.peek()== stack2.peek())
{
stack2.pop();
node1 = stack1.pop();
}
return node1;
}
}思路三:利用长度关系
之所以思路二需要用到栈,是因为想同时遍历到达两个栈的尾节点。当两个链表的长度不相同时,如果我们从头开始遍历到达两个栈的尾节点的时间就不一致。
其实解决这个问题还有一个更简单的办法:首先遍历两个链表得到他们的长度,就能知道哪个链表比较长,以及长的链表比短的链表多几个结点。在第二次遍历的时候,在较长的链表上先走若干步,接着同时在两个链表上遍历,找到的第一个相同的结点就是他们的第一个公共结点。
时间复杂度为O(m+n),但我们不在需要辅助栈,因此提高了空间效率。
/*
public class ListNode {
int val;
ListNode next = null;
ListNode(int val) {
this.val = val;
}
}*/
public class Solution {
public ListNode FindFirstCommonNode(ListNode pHead1, ListNode pHead2) {
int length1 = getLength(pHead1);
int length2 = getLength(pHead2);
int lengthDif = length1-length2;
ListNode longList = pHead1;
ListNode shortList = pHead2;
if(lengthDif<0){
longList = pHead2;
shortList = pHead1;
lengthDif = -lengthDif;
}
for(int i=0;i<lengthDif;i++)
longList = longList.next;
while(longList!=null && longList!=shortList ){
longList=longList.next;
shortList=shortList.next;
}
return longList; //没有公共结点刚好是null
}
private int getLength(ListNode head){
int len=0;
while(head!=null){
len++;
head=head.next;
}
return len;
}
}思路四:双指针
一个指针顺序遍历list1和list2,另一个指针顺序遍历list2和list1,(这样两指针能够保证最终同时走到尾结点),两个指针找到的第一个相同结点就是第一个公共结点
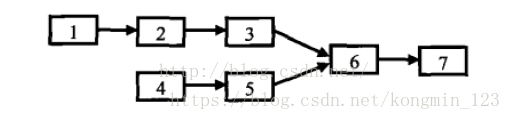
先list1后list2:1-2-3-6-7-4-5-6-7;
先list2后list1:4-5-6-7-1-2-3-6-7;
可以发现两个指针的第一个相同结点是结点6,即第一个共同结点。
/*
public class ListNode {
int val;
ListNode next = null;
ListNode(int val) {
this.val = val;
}
}*/
public class Solution {
public ListNode FindFirstCommonNode(ListNode pHead1, ListNode pHead2) {
ListNode node1 = pHead1;
ListNode node2 = pHead2;
while(node1 != node2)
{
node1 = node1 == null ? pHead2: node1.next;
node2 = node2 == null ? pHead1: node2.next;
}
return node1;
}
}总结
由于有共同结点时,后面的链表是重合的,所以这道题关键是要保证最后同时遍历到达尾结点,因此就有了后面三种方法:
1) 利用栈的先进后出实现同时到达;
2) 利用长度关系,长链表先行几步,实现同时到达;
3) 两个指针同时遍历两个链表,一个先list1后list2,另一个则相反,也可以实现同时到达。

















 264
264

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









