







 本文介绍了如何使用pytesseract和PIL库从图片中提取文字。首先确保安装了pytesseract和PIL,接着下载并配置tesseract-ocr,特别是添加中文语言包。然后修改pytesseract.py文件的tesseract_cmd路径为绝对路径。虽然运行准确度不高,但腾讯AI的图片识别服务提供了更高精度的结果,适合集成到项目中。
本文介绍了如何使用pytesseract和PIL库从图片中提取文字。首先确保安装了pytesseract和PIL,接着下载并配置tesseract-ocr,特别是添加中文语言包。然后修改pytesseract.py文件的tesseract_cmd路径为绝对路径。虽然运行准确度不高,但腾讯AI的图片识别服务提供了更高精度的结果,适合集成到项目中。
本文的目的是为了提取图片中的文字,图片如下所示:

第一:
首先保证有这两个包:pytesseract、PIL
直接pip即可;
第二:
- 网上找资源,下载tesseract-ocr;
【微软本已经下载成功,存放目录如下:】
- 安装tesseract-ocr;
【默认路径:C:\Program Files (x86)\Tesseract-OCR】 - 环境配置;
【将上述路径配置进去】 - 将安装包中的中文语言包文件夹下的语言包拖进tessdata中;
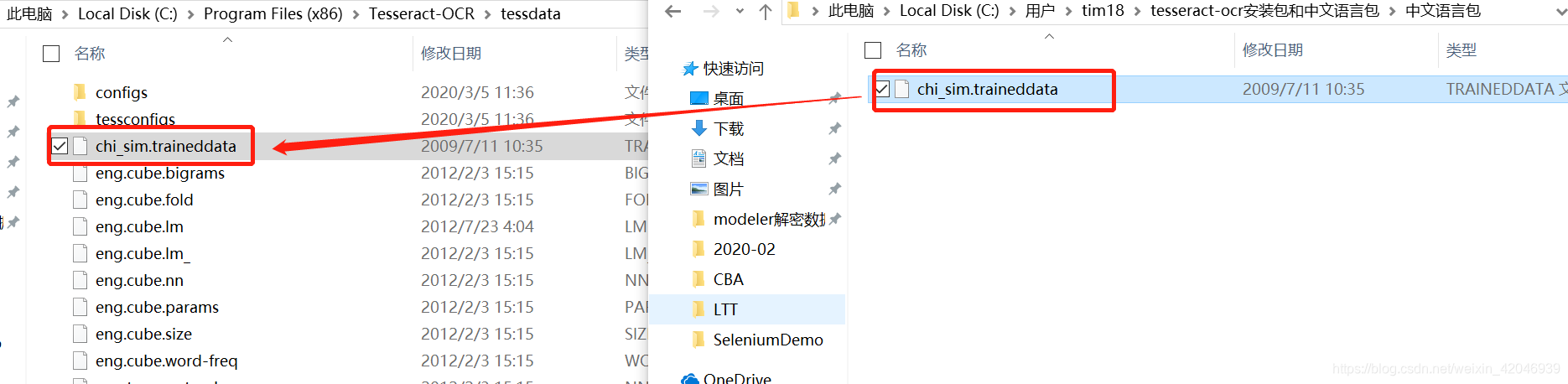
第三:
在pycharm中打开site_packages下的pytesseract下的pytesseract.py文件,将tesseract_cmd后的相对路径改成绝对路径,如下所示:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 278
278

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









