







写在前面
当我们在使用服务器时,如果发现服务器运行较慢,使用top、 uptime 、 w等命令查看一下,哪些进程耗费CPU资源过多,如果是垃圾进程,可以杀死。
服务器性能好坏如何分辨?有哪些衡量标准?
摘自知乎:服务器性能好坏如何分辨?有哪些衡量标准? - 知乎
服务器是整个网络系统和计算平台的核心,许多重要的数据都保存在服务器上,很多网络服务都在服务器上运行,因此服务器性能的好坏决定了整个应用。服务器性能的好坏如何分辨?主要看以下几个指标:
(1)CPU(中央处理器)
独立服务器的CPU执行诸如服务网页、运行数据库查询或处理计算命令等指令。CPU和内核的数量会影响可执行多少个并发指令。CPU架构和功能也影响执行指令的速度,特别是在围绕这些功能设计程序的网站或应用。
(2)内存RAM(随机存取存储器)
服务器内存的大小会影响服务器处理命令的速度。处理更复杂和更多种命令时,需要更高的内存。例如,动态的电子商务网站、数据库服务器等,需要对数据库运行各种查询和检索,更大的内存将使您获得更高的性能优势。
(3)硬盘类型(如SATA,SDD)
服务器中的固态硬盘(SSD)比SATA硬盘驱动器提供更高的磁盘读/写速度,也称为输入/输出(I/O)性能。具有SSD读取和写入磁盘的服务器速度更快,但定价显著高于同等存储容量的SATA硬盘。
(4)硬盘存储空间
服务器的硬盘存储是本地数据库大小和文件(如图像)的本地存储的限制因素。配置RAID磁盘阵列可有效增加数据可靠性,增加读取/写入(I/O)性能,RAID需要两个以上单独的存储卷。存储还可以采取网络存储的形式,如NAS(网络连接存储)或SAN(存储区域网络)。
(5)带宽
带宽数据传输限制,指的是可以并发到您的服务器的数据量。服务器带宽价格一般较高,通常提供10M 、20M,100M等常用带宽。像并发视频流、游戏和大数据处理等工作任务都需要高带宽。
(6)可用性
服务器的高可用性(HA)可能指网络和电源可用性,这反映在托管服务提供商的维护正常运行时间的实际记录以及其SLA(服务级别协议)中,以保证一定的正常运行时间。HA还可以通过以系统中单独的主动地添加RAID配置引入冗余来实现可用性保障,在发生隔离故障的情况下进行故障转移。
(7)网络延迟
网络延迟是服务器和用户之间发送信息的延迟的毫秒。网络延迟的高低由服务器提供商决定,但受到服务器和用户之间的距离和网络质量的影响。如租用HK服务器为降低延迟,服务器供应商部署中国大陆连通香港地区的CN2专线,是目前中国大陆访问较快较稳的线路,可提供较低的延迟和较好的网络体验。
(1)(3)(5)(6)(7)我们没有办法决定,阿里云服务器已经决定了,我们只能通过在平时使用过程中定期检查一下系统负载,有没有垃圾进程,CPU、内存、硬盘占用率,过高则需要自行清理一下。
1 查看服务器型号
查看服务器型号指令如下:
# output为Alibaba Cloud ECS
dmidecode -s system-product-name这说明这台服务器采用的是Alibaba Cloud ECS(阿里云ECS平台)。
2 查看CPU性能参数
CPU和内核的数量会影响可执行多少个并发指令。服务器CPU性能参数主要信息可以通过查看/proc/cpuinfo 获得。具体查看指令及效果如图所示,我们阿里云服务器有1个物理CPU,12个内核,12个逻辑CPU。

2.1 查看物理cpu个数
# output为1,说明该服务只有一个物理CPU
cat /proc/cpuinfo |grep "physical id"|sort|uniq|wc -l
2.2 查看每个物理cpu中的core个数
# output为12,说明当前服务器的每个物理CPU封装的物理核数为12个
cat /proc/cpuinfo |grep "cpu cores"|wc -l
2.3 逻辑cpu的个数
# output为12,说明该服务器有12个逻辑CPU
# 物理cpu个数*核数=逻辑cpu个数(不支持超线程技术的情况下)
cat /proc/cpuinfo |grep "processor"|wc -l
注:物理cpu个数 * 核数 = 逻辑cpu个数(不支持超线程技术的情况下)
2.4 查看cpu运行模式
# output 输出为64,说明这台服务器当前运行在64bit模式下
root@XXXXXXX:~# getconf LONG_BIT
2.5 查看服务器CPU型号
# Intel(R) Xeon(R) Platinum 8163 CPU @ 2.50GHz
cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq
2 服务器内核信息查询
# output为Linux BioCompute 4.15.0-122-generic #124-Ubuntu SMP Thu Oct 15 13:03:05 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux
# uname -a3 内存查看
3.1 查看内存使用情况
free -m命令会以MB形式现实内存使用情况。
free -m
free -h 命令会自动选择合适的容量单位显示。
free -h 
这台服务器上总的内存数为94G,已经使用的内存数为10G,空闲内存数为76G。
total:内存总数
used:已经使用的内存数
free:空闲内存数
shared:多个进程共享的内存总额
- buffers/cache:(已用)的内存数,即used-buffers-cached
+ buffers/cache:(可用)的内存数,即free+buffers+cached
Buffer Cache用于针对磁盘块的读写;
对操作系统来说free/used是系统可用/占用的内存;
对应用程序来说-/+ buffers/cache是可用/占用内存,因为buffers/cache很快就会被使用。
注:我们工作时候应该从应用角度来看(这台服务器看不到)。
free -g命令会以GB形式现实内存使用情况。
free -g4 硬盘查看
4.1 查看硬盘及分区信息
fdisk -l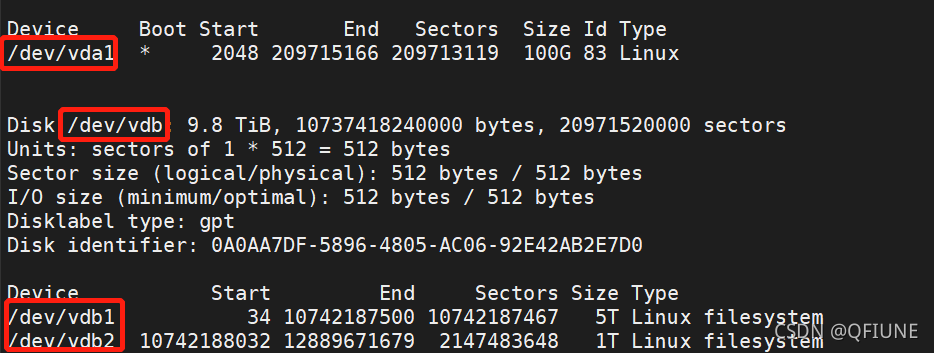 有两块硬盘,vda1(100G)和vdb(共10个T,有两个分区,一个vdb1,一个vdb2)
有两块硬盘,vda1(100G)和vdb(共10个T,有两个分区,一个vdb1,一个vdb2)
4.2 查看文件系统的磁盘空间占用情况
df -h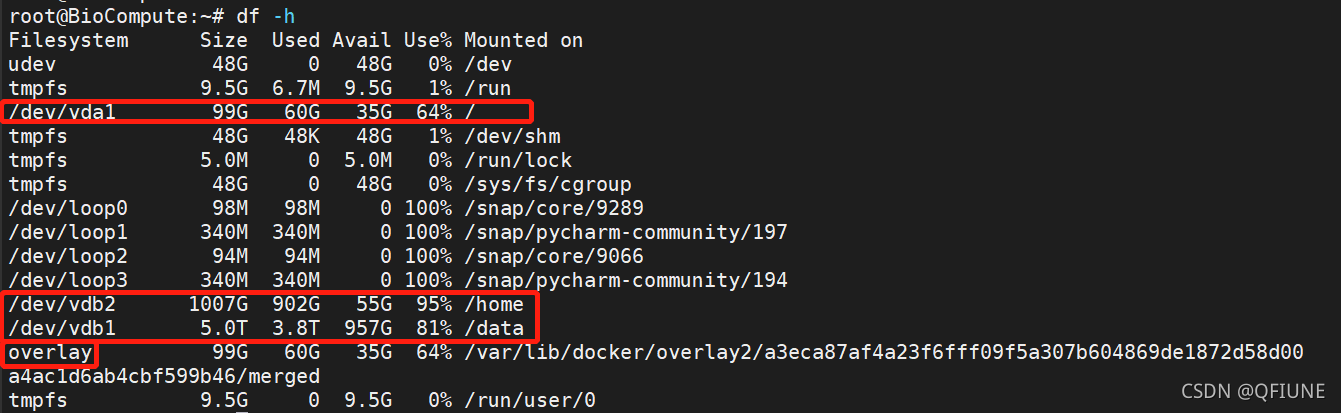
根目录被挂载在vda1硬盘上,/home被挂载在vdb2(1T),/data被挂载在vdb2(5T)
4.3 查看硬盘的I/O性能(每隔一秒显示一次,显示5次)
iostat主要用于监控系统设备的io负载情况,sostat首次运行时会显示自系统启动开始的各项统计信息,用户可以通过指定统计的次数和时间来获得所需的统计信息。
iostat -x 1 5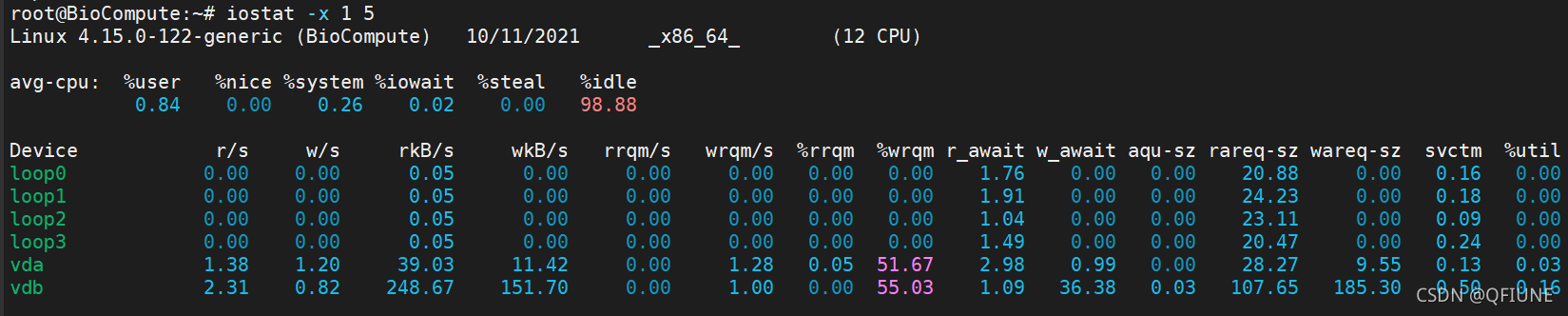
常关注的参数:
如%util接近100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。
如idle小于70%,I/O的压力就比较大了,说明读取进程中有较多的wait。
4.4 查看linux系统中某目录的大小
du -sh /root
如发现某个分区空间接近用完,可以进入该分区的挂载点,用以下命令找出占用空间最多的文件或目录,然后按照从大到小的顺序,找出系统中占用最多空间的前10个文件或目录:
cd /home/cqfnenu/
du -cksh *|sort -rn|head -n 10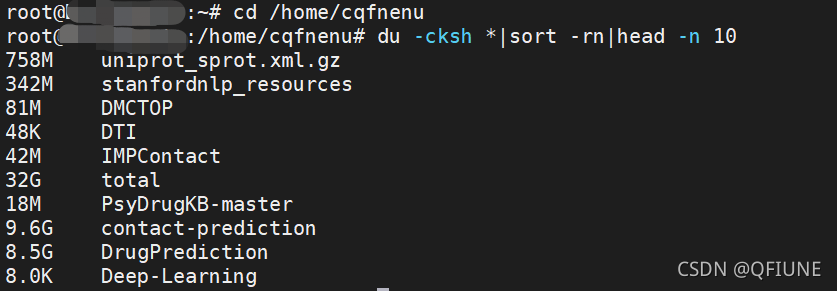
5 查看平均负载
有时候系统响应很慢,但又找不到原因,这时就要查看平均负载了,看它是否有大量的进程在排队等待。
load average:平均负载
平均负载(load average)是指系统的运行队列的平均利用率,也可以认为是可运行进程的平均数。
多核CPU的话,满负荷状态的数字为 "1.00 * CPU核数",即双核CPU为2.00,四核CPU为4.00。
一般的进程需要消耗CPU、内存、磁盘I/O、网络I/O等资源,在这种情况下,平均负载就不是单独指的CPU使用情况。即内存、磁盘、网络等因素也可以影响系统的平均负载值。
5.1 查看load average 数据
# 下面几个命令都可以看到 load average
top
uptime
w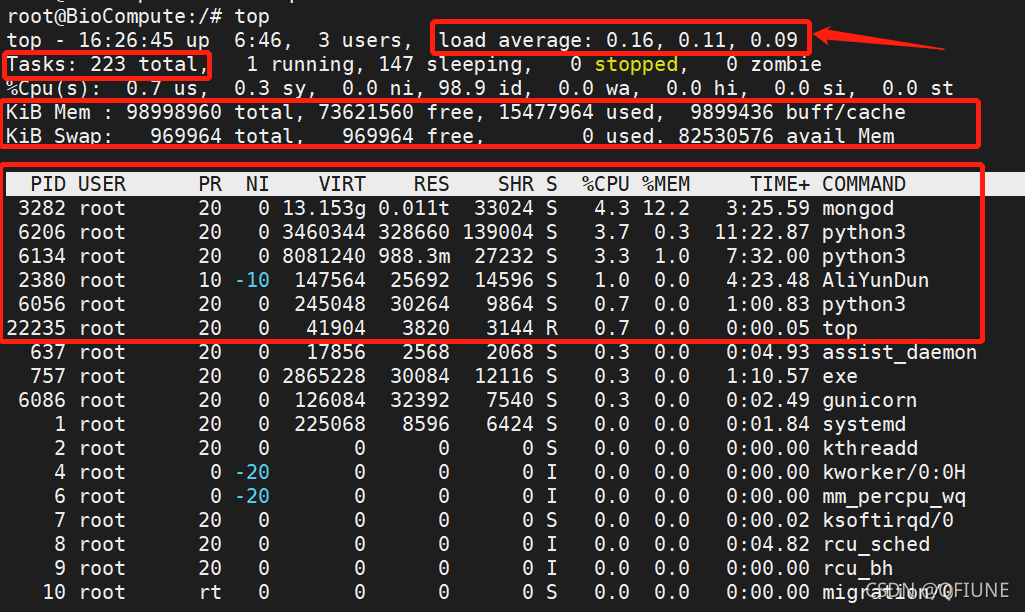
参数解释:
第一行:
16:26:45— 当前系统时间
6:46 — 系统已经运行了6小时46分钟(因为服务器重启过)
3 users — 当前有3个用户登录系统
load average: 0.16,0.11,0.09 — load average后面的三个数分别是1分钟、5分钟、15分钟的负载情况。
根据经验:我们应该把重点放在5/15分钟的平均负载,因为1分钟的平均负载太频繁,一瞬间的高并发就会导致该值的大幅度改变。阿里云服务器有1个CPU,12个内核,满载的情况为12。5/15分钟的平均负载超过12就表示过载了,长期过载会影响服务器性能,偶尔过载没关系。
第二行:
Tasks — 任务(进程),系统现在共有223个进程,其中处于运行中的有1个,147个在休眠(sleep),stoped状态的有0个,zombie状态(僵尸)的有0个。
第三行:cpu状态
0.5% us — 用户空间占用CPU的百分比。
0.3% sy — 内核空间占用CPU的百分比。
0.0% ni — 改变过优先级的进程占用CPU的百分比
99.3% id — 空闲CPU百分比
0.0% wa — IO等待占用CPU的百分比
0.0% hi — 硬中断(Hardware IRQ)占用CPU的百分比
0.0% si — 软中断(Software Interrupts)占用CPU的百分比
第四行:内存状态
98998960 total — 物理内存总量
15485936 used — 使用中的内存总量
73611328 free — 空闲内存总量
9901696 buff/cache — 缓存的内存量
第五行:swap交换分区
969964 total — 交换区总量
0 used — 使用的交换区总量
969964 free — 空闲交换区总量
4231276k cached — 缓冲的交换区总量
第六行是空行
第七行以下:各进程(任务)的状态监控
PID — 进程id
USER — 进程所有者
PR — 进程优先级
NI — nice值。负值表示高优先级,正值表示低优先级
VIRT — 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
RES — 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
SHR — 共享内存大小,单位kb
S — 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程
%CPU — 上次更新到现在的CPU时间占用百分比
%MEM — 进程使用的物理内存百分比
TIME+ — 进程使用的CPU时间总计,单位1/100秒
COMMAND — 进程名称(命令名/命令行)
uptime命令和w命令 ,个人觉得w命令比较友好,因为能看出是哪些账户在使用服务器。
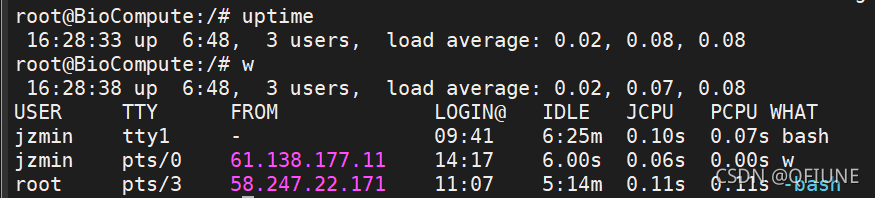
这里的 load average 的三个值分别指系统在最后 1/5/15分钟 的平均负载值。
根据经验:我们应该把重点放在5/15分钟的平均负载,因为1分钟的平均负载太频繁,一瞬间的高并发就会导致该值的大幅度改变。
5.2 vmstat命令来判断系统是否繁忙

# procs
r:等待运行的进程数。
b:处在非中断睡眠状态的进程数。
w:被交换出去的可运行的进程数。
# memeory
swpd:虚拟内存使用情况,单位为KB。
free:空闲的内存,单位为KB。
buff:被用来作为缓存的内存数,单位为KB。
# swap
si:从磁盘交换到内存的交换页数量,单位为KB。
so:从内存交换到磁盘的交换页数量,单位为KB。
# io
bi:发送到块设备的块数,单位为KB。
bo:从块设备接受的块数,单位为KB。
# system
in:每秒的中断数,包括时钟中断。
cs:每秒的环境切换次数。
# cpu
按cpu的总使用百分比来显示。
us:cpu使用时间。
sy:cpu系统使用时间。
id:闲置时间。5.3 其他命令
查看内核版本号:
uname -a
简化命令:uname -r
查看系统是32位还是64位的:
file /sbin/init
查看发行版:
cat /etc/issue
或lsb_release -a
查看系统已载入的相关模块:
lsmod
查看pci设置:
lspci

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









