







一、Pandas的函数应用
1,apply 和 applymap
(1)可直接使用NumPy的函数
示例代码:
# 导入numpy,别名np
import numpy as np
# 导入pandas,别名 pd
import pandas as pd
# Numpy ufunc 函数
df = pd.DataFrame(np.random.randn(5,4) - 1)
print(df)
print(np.abs(df))
显示结果:

(2)通过apply将函数应用到列或行上
指定轴的方向,默认axis=0,方向是列
指定轴方向,axis=1,方向是行
示例代码:
# 导入numpy,别名np
import numpy as np
# 导入pandas,别名 pd
import pandas as pd
# Numpy ufunc 函数
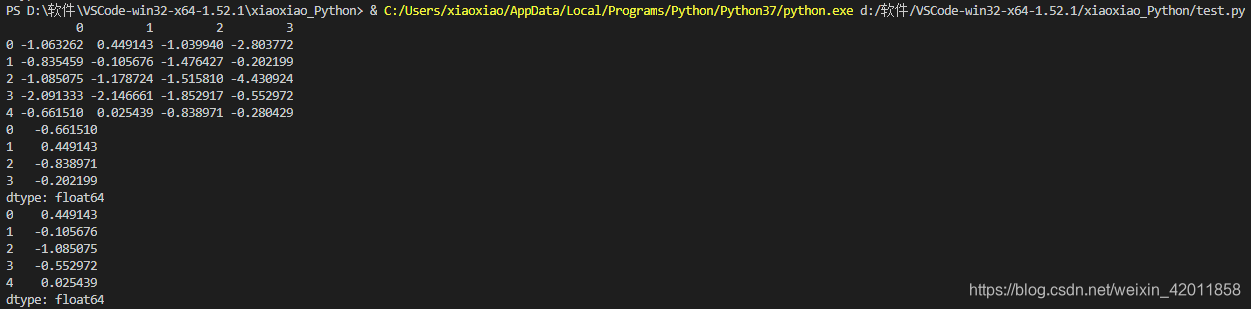
df = pd.DataFrame(np.random.randn(5,4) - 1)
print(df)
# 使用apply应用行或列数据
#f = lambda x : x.max()
print(df.apply(lambda x : x.max()))
print(df.apply(lambda x : x.max(), axis=1))
显示结果:
(3)通过applymap将函数应用到每个数据上
示例代码:
# 导入numpy,别名np
import numpy as np
# 导入pandas,别名 pd
import pandas as pd
# Numpy ufunc 函数
df = pd.DataFrame(np.random.randn(5,4) - 1)
print(df)
# 使用applymap应用到每个数据
f2 = lambda x : '%.2f' % x
print(df.applymap(f2))
显示结果:

2,排序
(1)索引排序
格式:sort_index()
含义:排序默认使用升序排序,ascending=False 为降序排序
Series操作
示例代码:
# 导入numpy,别名np
import numpy as np
# 导入pandas,别名 pd
import pandas as pd
# Series
s4 = pd.Series(range(10, 15), index = np.random.randint(5, size=5))
print(s4)
# 索引排序
s4.sort_index() # 0 0 1 3 3
显示结果:

DataFrame操作时注意轴方向
示例代码:
# 导入numpy,别名np
import numpy as np
# 导入pandas,别名 pd
import pandas as pd
# DataFrame
df4 = pd.DataFrame(np.random.randn(3, 5),
index=np.random.randint(3, size=3),
columns=np.random.randint(5, size=5))
print(df4)
df4_isort = df4.sort_index(axis=1, ascending=False)
print(df4_isort) # 4 2 1 1 0
显示结果:

(2)按值排序
格式:sort_values(by='column name')
含义:根据某个唯一的列名进行排序,如果有其他相同列名则报错。
示例代码:
# 导入numpy,别名np
import numpy as np
# 导入pandas,别名 pd
import pandas as pd
# DataFrame
df4 = pd.DataFrame(np.random.randn(3, 5),
index=np.random.randint(3, size=3),
columns=np.random.randint(5, size=5))
print(df4)
# 按值排序
df4_vsort = df4.sort_values(by=3, ascending=False)
print(df4_vsort)
显示结果:

3,处理缺失数据
(1)自动补充NaN
示例代码:
# 导入numpy,别名np
import numpy as np
# 导入pandas,别名 pd
import pandas as pd
df_data = pd.DataFrame([np.random.randn(3), [1., 2., np.nan],
[np.nan, 4., np.nan], [1., 2., 3.]])
print(df_data.head())
显示结果:

(2)判断是否存在缺失值:isnull()
示例代码:
# 导入numpy,别名np
import numpy as np
# 导入pandas,别名 pd
import pandas as pd
df_data = pd.DataFrame([np.random.randn(3), [1., 2., np.nan],
[np.nan, 4., np.nan], [1., 2., 3.]])
print(df_data.isnull())
显示结果:

(3)丢弃缺失数据:dropna()
根据axis轴方向,丢弃包含NaN的行或列。
示例代码:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











