









在1.7 向量化在Logistic回归梯度下降法中的应用(正向传播)中记录了如何通过向量化同时计算整个训练集m个样本的预测值a,本节中描述如何用向量化计算m个训练数据的梯度
原本计算梯度:
d
z
1
=
a
1
−
y
1
,
d
z
2
=
a
2
−
y
2
.
.
.
.
d
z
m
=
a
m
−
y
m
dz^1=a^1-y^1,dz^2=a^2-y^2....dz^m=a^m-y^m
dz1=a1−y1,dz2=a2−y2....dzm=am−ym
向量化:
-
现定义一个1×m的矩阵: d Z = [ d z 1 , d z 2 . . . . d z m ] dZ=[dz^1,dz^2....dz^m] dZ=[dz1,dz2....dzm]
-
在上一节1.7中,定义过: A = [ a 1 , a 2 . . . . a m ] A=[a^1,a^2....a^m] A=[a1,a2....am]
-
定义: Y = [ y 1 , y 2 . . . . y m ] Y=[y^1,y^2....y^m] Y=[y1,y2....ym]
-
基于以上定义,z的计算可以用一行代码实现:
d Z = A − Y = [ a 1 − y 1 , a 2 − y 2 . . . a m − y m ] dZ=A-Y=[a^1-y^1,a^2-y^2...a^m-y^m] dZ=A−Y=[a1−y1,a2−y2...am−ym]
矩阵中的每一个元素就是原本计算梯度中对应的每一个式子
在1.7中实现了对下图中下方的for循环向量化,将dw化为一个向量,目前还存在上面那个对训练集遍历的for循环

之前for循环的实现过程:
d
w
=
0
dw=0
dw=0
d
b
=
0
db=0
db=0
d
w
+
=
x
1
d
z
1
dw+=x^1dz^1
dw+=x1dz1
d
b
+
=
d
z
1
db+=dz^1
db+=dz1
d
w
+
=
x
2
d
z
2
dw+=x^2dz^2
dw+=x2dz2
d
b
+
=
d
z
2
db+=dz^2
db+=dz2
… …
… …
d
w
/
=
m
dw/=m
dw/=m
d
b
/
=
m
db/=m
db/=m
现在针对上述过程进行向量化:
处理db:
- d b = 1 m ∑ i = 1 m d z i db=\frac{1}{m}\sum_{i=1}^mdz^i db=m1i=1∑mdzi
- 所有的dz组成了一个行向量
d
Z
=
A
−
Y
=
[
a
1
−
y
1
,
a
2
−
y
2
.
.
.
a
m
−
y
m
]
dZ=A-Y=[a^1-y^1,a^2-y^2...a^m-y^m]
dZ=A−Y=[a1−y1,a2−y2...am−ym]
Python中实现: 1 m n p . s u m ( d Z ) \frac{1}{m} np.sum(dZ) m1np.sum(dZ),只需要把dZ这个变量传给np.sum函数就可以得到db
处理dw:
-
d
w
=
1
m
X
d
Z
T
dw=\frac{1}{m}XdZ^T
dw=m1XdZT
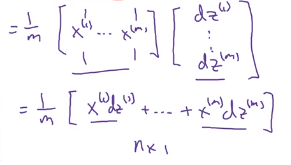
小结
回顾1.7和本节内容,总结如何实现一个logistic回归
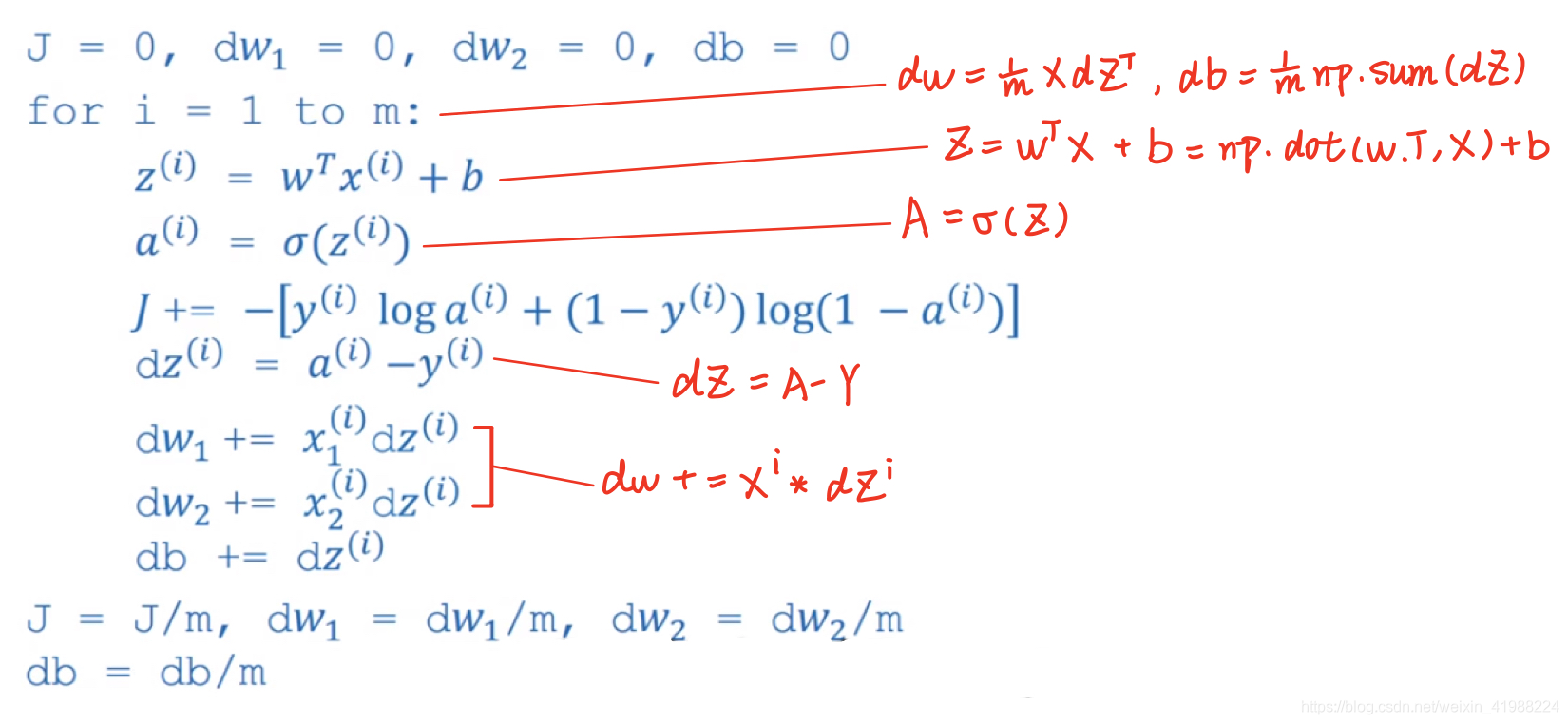
一次高度向量化的迭代:
Z=wTX+b=np.dot(w.T,X)+b
A=
σ
\sigma
σ(Z)
dZ=A-Y
dw=
1
m
\frac{1}{m}
m1XdZT
db=
1
m
\frac{1}{m}
m1 np.sum(dZ)
w:=w-αdw
b:b-αdb
如果要实现多次迭代,要在最前面加for循环,这个循环目前无法简化


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









