








论文地址:https://ieeexplore.ieee.org/document/9216604
源码地址:尚未开源
1 Main Idea
本文站在增量的角度, 认为模型是迭代地适应到新域。作者用了现有的无监督域自适应算法,来识别相对于他们真实标签有较高置信度的目标域样本。用了不同的方法分析模型的输出,以决定候选的样本。选择出来的样本用自标记(self-labeling)的方法加到源域训练集,重复这个过程直至所有的目标域样本都打上了标签。
《A DIRT-t approach to unsupervised domain adaptation》提出的虚拟对抗DA(virtual adversarial DA,即VADA)给损失函数加上了一个惩罚项,以惩罚跨越高密度特征区域的类别边界。《Conditional adversarial domain adaptation》提出的条件域对抗网络,使对抗学习以两种方式取决于判决信息:多线性条件(采集表征和预测之间的协方差)和熵条件(通过控制预测的不确定性来保证模型的迁移性)。《Domain separation networks》的训练目的是将输入表征映射至一个域相关的子控件,和一个域无关的子空间,来提高域不变特征的能力。《Associative domain adaptation》加强了源域和目标域表征在神经网络一个向量空间上的关系。《Drop to adapt: Learning discriminative features for unsupervised domain adaptation》用了对抗性dropout来提高域不变特征的判别能力。《Deepjdot: Deep joint distribution optimal transport for unsupervised domain adaptation》学习源域和目标域之间的分类器和对齐后的数据表征,用了一个基于最优运输理论损失函数的神经网络框架。
2 Incremental DANN
作者主要认为可以使用分类器![]() 置信度更高的目标域样本子集,并将它们添加到带标记的源域中,并假定输出就是真实的结果。这些样本在后面完完全地被视为源域的样本。然后重复训练DANN网络,用新的训练集fine-tune它的权重。这个过程迭代地反复进行,将更高置信度的带标记样本从目标域移动到源域,当目标域没有样本可移动时结束迭代的过程。
置信度更高的目标域样本子集,并将它们添加到带标记的源域中,并假定输出就是真实的结果。这些样本在后面完完全地被视为源域的样本。然后重复训练DANN网络,用新的训练集fine-tune它的权重。这个过程迭代地反复进行,将更高置信度的带标记样本从目标域移动到源域,当目标域没有样本可移动时结束迭代的过程。
在每一代中,任务的复杂度逐渐提高,因为先解决了更容易分类的样本(DANN置信度更高),留下那些未标记目标域集中更不相似的特征。当模型用包括目标域信息的带标记样本retrain的时候,域分类模块![]() 要变得更加specify。这令特征提取模块
要变得更加specify。这令特征提取模块![]() 遗忘掉区分目标域中更复杂样本的特征。
遗忘掉区分目标域中更复杂样本的特征。


在算法中,目标域![]() 的样本由标签分类器
的样本由标签分类器![]() 进行分类,然后选择一个大小为r的子集
进行分类,然后选择一个大小为r的子集![]() ,从目标域移动到源域。标签分类器
,从目标域移动到源域。标签分类器![]() 地作用是分类整一个起始目标域
地作用是分类整一个起始目标域![]() 。这个带标记的目标域数据集然后用来从头开始训练一个神经网络。
。这个带标记的目标域数据集然后用来从头开始训练一个神经网络。
3 Selection Policies
3.1 Confidence Policy

3.2 kNN Policy
通过k近邻规则来衡量特征空间的几何特质。 首先从源域集合S中用![]() 获得特征集合
获得特征集合![]() ;然后继续依据目标域集合的置信度水平来迭代。已知一个目标域样本,如果最近邻的k个源域样本符合标签分类器对应的标签,那么作者会选择该标签对应的prototype为目标域样本的prototype(if the label of the k-nearest samples of the source domain matches the label assigned by the label classifier Gy, then we will select the prototype)。否则会丢弃这个样本。所以,基于DANN给出的标签置信度和匹配源域分布的程度,把样本抽选出来。
;然后继续依据目标域集合的置信度水平来迭代。已知一个目标域样本,如果最近邻的k个源域样本符合标签分类器对应的标签,那么作者会选择该标签对应的prototype为目标域样本的prototype(if the label of the k-nearest samples of the source domain matches the label assigned by the label classifier Gy, then we will select the prototype)。否则会丢弃这个样本。所以,基于DANN给出的标签置信度和匹配源域分布的程度,把样本抽选出来。


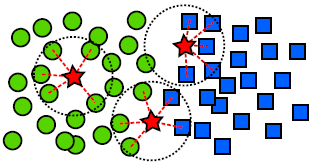
该方法的目的是挑选出那些特征在源域中具有相同类别的簇内目标域样本。如上图所示,左边的星号会被选中,并分类成绿色圆圈,以你为它最近邻的5个目标都是绿色圆圈,同样右上方的星号会被选中为蓝色方框。反之,中间的星号会被丢弃,因为它最近邻的5个目标同时属于两个类。
如果提高k的值,左边星号的依然会被选中(假如依然分类成绿色圆圈),因为它处在一个簇的中间。但是右边的红色星号因为在标签边界,最终会被丢弃。
3.3 Training a Classifier With the New Labeled Target Set
作者假设目标域集合的迭代结果有一部分会有标签上的噪声。为了减缓噪声带来的可能的影响,作者考虑了“标签平滑”(label smoothing),更不容易过拟合。
![]()
![]() 是一个较小的常数(平滑参数),L是类别的总数。因此除了最小化硬目标的交叉熵(minimizing cross-entropy with hard targets,0或1),还考虑了软目标。
是一个较小的常数(平滑参数),L是类别的总数。因此除了最小化硬目标的交叉熵(minimizing cross-entropy with hard targets,0或1),还考虑了软目标。
3.4 Insights Into the Learning Process
令域S和T的判别特征为![]() ,两者的元素代表定义各个域,用来模式识别的具体特征。因为这些特征可以用来判别类别和/或者识别域标签。假设有一个子集
,两者的元素代表定义各个域,用来模式识别的具体特征。因为这些特征可以用来判别类别和/或者识别域标签。假设有一个子集![]() ,具有两个域共有的特征。,代表了域不变性特征,DANN算法要学会用无监督的方式分类目标域样本。这也表明有一个含有与源域相关的子集
,具有两个域共有的特征。,代表了域不变性特征,DANN算法要学会用无监督的方式分类目标域样本。这也表明有一个含有与源域相关的子集![]() 和一个与目标域相关的子集
和一个与目标域相关的子集![]() ,这些子集对于域间的判别有帮助。
,这些子集对于域间的判别有帮助。
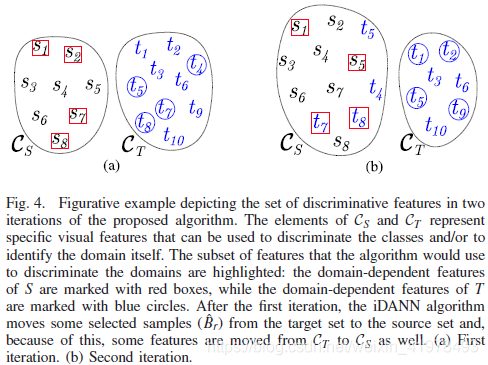
上图可视化地给出了![]() 在算法前两代的一种构图。作者highlight了特征的一个子集,域分类模块
在算法前两代的一种构图。作者highlight了特征的一个子集,域分类模块![]() 会使用这些特征来区分域标签,这就是域相关的特征。就是这些特征通过了GRL层,被迫被特征提取模块
会使用这些特征来区分域标签,这就是域相关的特征。就是这些特征通过了GRL层,被迫被特征提取模块![]() 忽略。这种运算可以让标签分类模块
忽略。这种运算可以让标签分类模块![]() 忽略域相关的特征,但是不能保证剩下的特征不会被学习到。
忽略域相关的特征,但是不能保证剩下的特征不会被学习到。
可能会有一些很容易区分出域标签的特征,例如背景颜色。在这种情况下,![]() 只需要域相关特征的子集,所以在第一步忽略了更复杂的域相关特征。
只需要域相关特征的子集,所以在第一步忽略了更复杂的域相关特征。
有一些特征依然会呆在![]() ,会依赖是否剩下的目标域样本是否用这些特征识别出来。在后面每一代,DANN需要找出新的域相关特征,因为最容易分类的那些已经不再用来区分域标签了。已知存在带(伪)标记的样本,包含目标域集合的公共特征(例如t5),这些特征会帮助分类无标记的目标域样本。
,会依赖是否剩下的目标域样本是否用这些特征识别出来。在后面每一代,DANN需要找出新的域相关特征,因为最容易分类的那些已经不再用来区分域标签了。已知存在带(伪)标记的样本,包含目标域集合的公共特征(例如t5),这些特征会帮助分类无标记的目标域样本。
在每一代中,iDANN会将域相关特征从目标域移动到源域,留下域无关特征或者难学习的域相关特征。在第一代中![]() 只需要容易区分域标签的特征,但在这些特征都迁移到源域后,
只需要容易区分域标签的特征,但在这些特征都迁移到源域后,![]() 会搜索其他更加复杂的。最后会导致GRL层使得
会搜索其他更加复杂的。最后会导致GRL层使得![]() 忘记更加复杂的域相关特征。
忘记更加复杂的域相关特征。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









