







 超级会员免费看
超级会员免费看
FANG:利用图表示利用社会背景进行假新闻检测
摘要重点:与之前具有目标性能的上下文模型不同,我们的重点是表示学习。与传导模型相比,FANG 在训练中具有可扩展性,因为它不需要维护所有节点,并且在推理时非常高效,无需重新处理整个图。
关注,订阅专栏,可领取原文和代码。
1 介绍
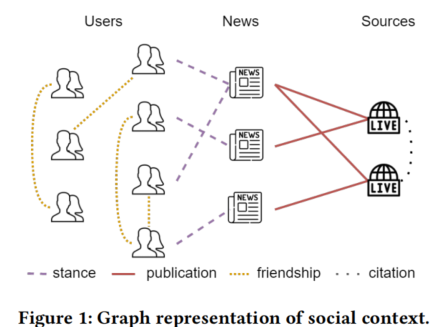
之前的工作提出了社会语境的部分表示,包括(i)新闻、来源和用户作为主要实体,以及(ii)立场、友谊和出版物作为主要互动[16,32,33,39]。然而,他们根本不太强调表示的质量、实体及其交互的建模和最小监督设置。自然地,新闻传播的社会语境可以表示为异质网络,其中节点和边分别表示社会实体及其相互作用。在对用户回声室或新闻媒体极化网络等现象的结构建模能力方面,网络表示比一些现有的基于欧几里得的方法[23,35]具有一些优势。图模型还允许实体通过(i)同质边,即用户-用户关系、源-源引用,(ii)异质边,即用户-新闻立场表达、源-新闻发布,以及(iii)高阶邻近性(即始终支持或拒绝某些来源的用户之间,如图1所示)交换信息。这使得异质实体的表示具有依赖性。不仅利用了假新闻检测,还利用了相关的社会分析任务,如恶意用户检测[7]和来源事实性预测[3]。
本文贡献
- 我们提出了一种新颖的图表示形式,可以对所有主要社会参与者及其互动进行建模(图 1)。
- 我们提出事实新闻图(FANG),这是一种归纳图学习框架,可以有效捕获社会结构和参与模式,从而改善表示- 句子质量。
- 我们报告使用 FANG 时在假新闻检测方面的显着改进,并进一步表明我们的模型在训练数据有限的情况 下具有鲁棒性。
- 我们表明 FANG 学习到的表示推广到相关任务,例如预测新闻媒体报道的真实性。
- 我们通过其循环聚合器的注意力机制证明了 FANG 的可解释性。
2 相关工作
略
图构建:
社交用户偏好与用户新闻消费习惯之间的正相关关系已经得到了已有研究[1]的认可。具体来说,社交媒体创造了一个回音室,在那里,个人的信仰可以通过在志同道合的社会群体[12]中的交流和重复不断得到加强。
3.1 基于社会语境的假新闻检测
表3总结了不同类型交互的特征,包括同构和异构。姿态是一种特殊的交互类型,因为它们不仅具有边标签和源/目的节点的特征,而且还具有时间特性,如表1中先前的例子所示。最近的工作强调了纳入时序的重要性,不仅对假新闻检测[26,35],而且对在线信息传播建模[14]。我们使用以下立场标签:中立支持,否定支持,否认,报告。主要的支持立场和否认立场与之前的研究一致(如[28]),而两种支持立场——中立支持和负面支持——则基于新闻事实性与被调用情绪之间的相关性[1]。当用户只是传播新闻文章而没有表达任何意见时,我们将报告立场标签分配给用户-新闻参与度。总之,我们使用立场来根据对新闻文章的观点来描述新闻文章,以及通过社交用户对各种新闻文章的观点来描述社交用户。
基于上下文的假新闻检测:给定一个社会背景𝐺=(𝐴,𝑆,𝑈,𝐸)由𝐴新闻文章,新闻来源𝑆、社会用户𝑈,和社会活动𝐸,基于上下文的假新闻检测被定义为二进制分类任务预测是否新闻文章𝑎∈𝐴是真实的还是假的,换句话说,𝐹𝐶:𝑎→{0,1}
![]()
3.2 基于社会背景的图构建
(A)新闻文章:文本[6,34,39,44]和视觉[18,43]特征被广泛用于新闻文章内容建模,或通过特征提取,无监督语义编码,或学习表示。我们使用无监督文本表示,因为它们的构建和优化相对高效。对于每一篇文章𝑎∈𝐴,我们构建一个TF。IDF从文章正文中提取[36]向量。通过对每个词的GloVe[30]的预训练嵌入与其TF进行加权,丰富了新闻的表示。IDF值,形成语义向量。最后,我们连接TF。将IDF和语义向量组成新闻文章特征向量𝒙𝑎。
(S)新闻来源:我们专注于使用新闻媒体网站的文本内容来表征新闻媒体来源[3,21]。与文章表示类似,对于每个源𝑠,我们构建源特征向量𝒙𝑠作为其TF的连接。IDF向量及其语义向量来源于首页和关于我们部分的单词,因为一些假新闻网站公开宣称其内容具有讽刺或讽刺意味。
(U)社交用户:网络用户作为社交媒体中假新闻和谣言的主要传播者已被广泛研究。如第2节所述,之前的工作[6,44]使用了诸如人口统计、信息偏好、社会活动和网络结构(如粉丝或朋友数量)等属性。Shu等[39]对用户画像进行特征分析,指出画像描述和时间轴内容派生信号的重要性。文字描述如“美国妈妈受够了反美左派和腐败。我相信美国宪法、自由企业、强大的军队和唐纳德·特朗普#maga”强烈表明了用户的政治偏见,并暗示了推广某些叙事的倾向。我们计算用户向量𝑥𝑢作为由TF组成的一对连接。IDF向量和从用户画像的文本描述派生的语义向量。
(E)社交关系:每一对社会用户(𝑣𝑖,𝑣𝑗)∈𝐴∩𝑆∩𝑈,我们添加一个边缘𝑒={𝑣𝑖,𝑣𝑗,𝑡,𝑥𝑒}的社交互动𝐸如果他们联系通过交互类型𝑥𝑒。具体来说,对于关注,我们检查用户𝑢𝑖是否关注了用户𝑢𝑗;在发布方面,我们查看新闻文章𝑎𝑖是否由来源𝑠𝑗发布;对于引用,我们检查源𝑠𝑖的主页是否包含到源𝑠𝑗的超链接。对于时间敏感的交互,即发表和立场,我们记录它们相对于文章最早发表时间的相对时间戳。
立场检测:获取一段文本相对于另一段文本的视角的任务称为立场检测。在假新闻检测的背景下,我们感兴趣的是用户对可疑新闻标题的回复立场。我们考虑了四种立场:中立情绪支持或中立支持,消极情绪支持或消极支持,否认和报告。在清理了表情符号、标点符号、停用词和url中的文本后,如果文章与文章标题匹配,则将其分类为新闻文章的逐字报道。我们训练一个立场检测器,将剩余的帖子分类为支持或拒绝。流行的立场检测数据集要么没有明确描述目标文本[8],目标数量有限[27,40],要么对源/目标文本的定义不同,如假新闻挑战中。
为了克服这一困难,我们构建了自己的用于社交媒体帖子和新闻文章立场检测的数据集,其中包含来自31个新闻事件的2527个带标签的源-目标句子对。对于每个带有参考标题的事件,标注者会得到相关标题和帖子的列表。他们标记了每个相关标题或帖子是否支持或否认参考标题的主张。除了参考标题相关的标题或标题相关的帖子句子对外,进一步对标题相关的帖子句子对进行二阶推理。如果这样的一对对对参考标题表达了类似的立场,我们推断出与标题相关的文章的支持立场,否则,我们推断出支持立场。表4和表5显示了关于数据集的示例注释和统计信息。用Cohen’s Kappa评估的注释者间协议为0.78,表明了实质性的协议。为了选择最佳立场分类器,我们使用各种预训练的大规模transformer在我们的数据集上对模型进行微调[9,22]。实验结果表明,RoBERTa[22]的准确率为0.8857,𝐹1得分为0.8379,精确率为0.8365,召回率为0.8395,效果最好,因此我们选择它作为立场分类器。
3.3 FANG框架
3.3.1 表征学习
让𝐺𝑟𝑎𝑝ℎ𝑆𝑎𝑔𝑒(·)是GraphSage节点编码功能。因此,我们现在可以获得任何用户和源节点𝑟的结构表示𝒛𝑢∈R𝑑为𝒛𝑟=𝐺𝑟𝑎𝑝ℎ𝑆𝑎𝑔𝑒(𝑟),其中𝑑是结构嵌入维度。对于新闻节点,我们用用户参与时序性进一步丰富了它们的结构表示,在上面第1节中,我们表明这在假新闻检测中是独特的。这可以表述为学习聚合函数𝐹(𝑎,𝑈),该函数将有问题的新闻𝑎及其参与的用户𝑈映射到捕获𝑎的参与模式的时间表示𝒗𝑡𝑒𝑚𝑝𝑎。因此,聚合模型(即聚合器)必须是时间敏感的。循环神经网络满足了这一需求:双向LSTM (Bi-LSTM)可以在前向和后向[15]的信息序列中捕获长期依赖。在Bi-LSTM之上,进一步纳入了一种注意力机制,专注于编码过程中的基本参与。注意力不仅希望提高模型质量,还希望提高其可解释性[9,24]。通过检查模型的注意力,了解哪些社交档案影响决策,模仿人类的分析能力。
我们提出的LSTM输入是用户-文章参与序列,
![]()
,设𝑚𝑒𝑡𝑎(𝑒𝑖)∈R𝑙=(𝑡𝑖𝑚𝑒(𝑒𝑖),𝑠𝑡𝑎𝑛𝑐𝑒(𝑒𝑖))是𝑒𝑖自新闻发布以来经过的时间和一个独热立场向量的连接。每个参与𝑒𝑖都有其表示,
![]()
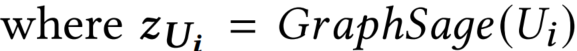
Bi-LSTM对参与序列进行编码,并输出两个隐藏状态序列:
- 前向,
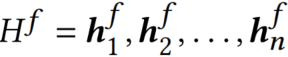
- 后向,
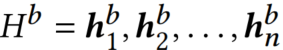
设𝑤𝑖是我们的Bi-LSTM编码器对前向(𝒉𝑖𝑓)和后向(𝒉𝑏𝑖)隐藏状态的注意力权重。这种注意力应该来自隐藏状态和新闻特征的相似性,即参与的用户与讨论内容的相关性,以及参与的特定时间和立场。因此,我们将注意力权重𝑤𝑖表示为:
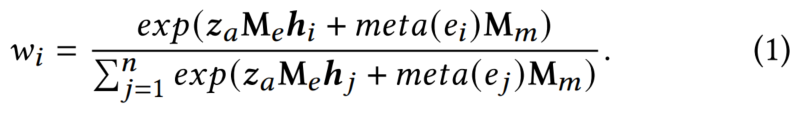
最后,我们将前向向量和后向向量连接起来以获得文章𝑎的时间表示
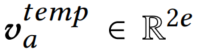
。通过显式设置2𝑒=𝑑,我们可以将新闻的时间和结构表示𝑎组合为单个表示:
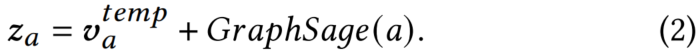
3.3.2 无监督邻近损失
我们从紧密联系的社会实体通常行为相似的假设中得出邻近损失。这是由回音室现象所激发的,在回音室现象中,社会实体倾向于与其他具有共同利益的实体互动,以加强和促进他们的叙事。这种回音室现象包括发布内容或事实相似的新闻的相互引用的新闻媒体源,以及对内容相似的新闻文章表达相似立场的社交朋友。因此,FANG应该将这些邻近的实体分配给嵌入空间中的一组邻近向量。本文还假设,松散联系的社会实体的行为通常与我们的观察不同,即社会实体高度极化,特别是在左右政治中[4]。FANG应该强调这些不同实体的表征是不同的。
定义上述特征最多的社交互动是用户-用户友谊、源-源引用和新闻-源发布。由于这些交互要么是(a)来源和新闻之间的交互,要么是(b)新闻之间的交互,因此将社会上下文图划分为两个子图,即新闻-来源子图和用户子图。在每个子图𝐺'中,我们制定以下邻近度损失函数:
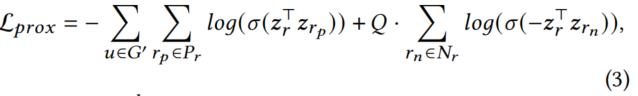
3.3.3 自监督立场损失
在立场方面,本文还为用户-新闻交互提出了一个类似的假设。如果用户表达了对一篇新闻文章的立场,他们各自的表示应该是接近的。对于每个立场𝑐,我们首先学习用户投影函数
![]()
和新闻文章投影函数
![]()
将R𝑑的节点表示映射到R𝑑𝑐的立场空间𝑐中的表示。
给定一个用户𝑢和一篇新闻文章𝑎,我们在立场空间𝑐中计算他们的相似性得分为
![]()
。如果𝑢表达了𝑐相对于𝑎的立场,我们就最大化这个分数,否则我们就最小化它。这是立场分类目标,使用立场损失进行了优化:
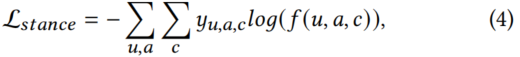
3.3.4 有监督的假新闻损失
通过有监督的假新闻损失直接优化假新闻检测的主要学习目标。为了预测文章𝑎是否为假,我们将其上下文表示作为其表示和其来源的结构表示的连接,
![]()
,然后将这种上下文表示输入到全连接层,其输出计算为
![]()
,其中𝑾∈r2𝑑×1和𝑏∈R是层的权重和偏差。输出值𝑜𝑎∈R最终通过sigmoid激活函数𝜎(·),并使用以下交叉熵假新闻损失L𝑛𝑒𝑤𝑠进行训练,定义如下:
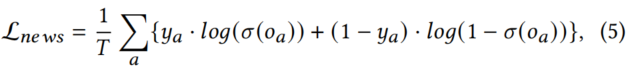
4 实验
略
5 讨论
为了更好地理解FANG在不同场景下的表现,我们现在回答以下研究问题(RQs):
- FANG在有限的训练数据下是否可以很好地工作
- FANG是否根据假新闻和真实新闻的互动时间差异来区分它们?
- FANG的表征学习效果如何?
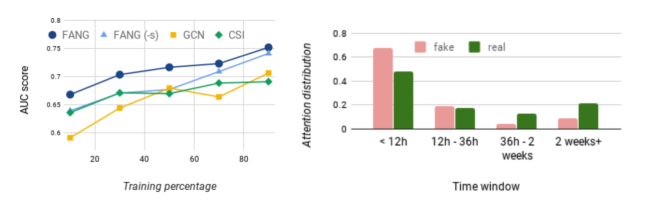
为了解决RQ2问题并验证我们的模型是否基于假新闻和真实新闻之间独特的时间模式做出决策,我们检查了FANG的注意力机制。我们将FANG在每个时间窗口内产生的注意力权重累积起来,并在不同的时间窗口内进行比较。图3(右)显示了假新闻和真实新闻的注意力随时间的分布。
5 局限
实体和交互特征在传递给FANG之前被构建,因此来自上游任务的错误,如文本编码或立场检测,可以传播到FANG。未来的工作可以在端到端框架中解决这个问题,其中文本编码[9]和立场检测可以联合优化。另一个限制是用于上下文假新闻检测的数据集可能很快就会过时,因为发布时的超链接和社交媒体痕迹可能不再可检索。


















 220
220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











