




 本文详细介绍了决策树的概念,包括信息熵、信息增益、增益率和基尼指数等划分选择标准,以及预剪枝和后剪枝两种剪枝策略。此外,还讨论了连续值处理和缺失值问题,并简要提到了多变量决策树及其简化方法。
本文详细介绍了决策树的概念,包括信息熵、信息增益、增益率和基尼指数等划分选择标准,以及预剪枝和后剪枝两种剪枝策略。此外,还讨论了连续值处理和缺失值问题,并简要提到了多变量决策树及其简化方法。
1.决策树概念
一棵决策树包含一个根结点、若干个内部结点和若干个叶结点;叶结点对应于决策结果,其他每个结点则对应于一个属性测试;每个结点包含的样本集合根据属性测试的结果被划分到子结点中;根结点包含样本全集.
决策树的生成是一个递归过程.
2.划分选择
随着划分过程不断进行,我们希望决策树的分支结点所包含的样本尽可能属于同一类别,即结点的"纯度" (purity) 越来越高.
a.信息增益
信息熵
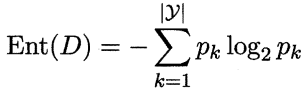
Ent(D) 的值越小,则 的纯度越高.
信息增益
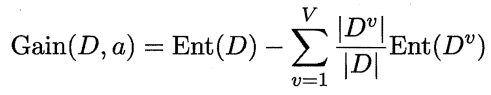
给分支结点赋予权重 IDVI/IDI,即样本数越多的分支结点的影响越大
ID3算法就是基于信息增益的决策树算法,信息增益越大,则意味着使用该属性来进行划分所获得的"纯度提升"越大.
b.增益率
由上式可见,信息增益准则对可取值数目较多的属性有所偏好,为减少这种偏好可能带来的不利影响,著名的 C4.5 决策树算法不直接使用信息增益,而是使用"增益率" (gain ratio) 来选择最优划分属性.
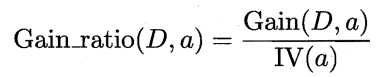
其中
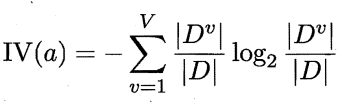
c.基尼指数
CART 决策树 使用"基尼指数" 来选择划分属性。
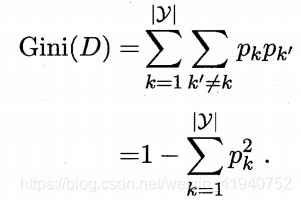
Gini(D) 越小,则数据集 的纯度越高.属性的基尼指数定义为
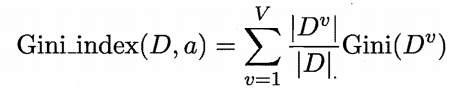
3.剪枝
剪枝(pruning) 是决策树学习算法对付"过拟合"的主要手段。决策树剪枝的基本策略有"预剪枝" (prepruning) 和"后剪枝"。
预剪枝是指在决策树生成过程中,对每个结点在划分前先进行估计,若当前结点的划分不能带来决策树泛化性能提升,则停止划分并将当前结点标记为叶结点。预剪枝基于"贪心"本质禁止这些分支展开给预剪枝决策树带来了欠拟含的风险
后剪枝则是先从训练集生成一棵完整的决策树,然后自底向上地对非叶结点进行考察,若将该结点对应的子树替换为叶结点能带来决策树泛化性能提升,则将该子树替换为叶结点。后剪枝过程是在生成完全决策树之后进行的 并且要白底向上
对树中的所有非叶结点进行逐考察,因此其训练时间开销比未剪枝决策树和预剪枝决策树都要大得多。
如何判别性能是否提升?即前一篇说的,留出一部分作为验证集,进行性能评估。
4.连续与缺失值
a.连续值处理
二分法:C4.5采用。对连续属性 α,例如西瓜的密度、含糖率等,我们考察包含n-1个元素的候选划分点集合.即把区间的中位点Ta出作为候选划分点.
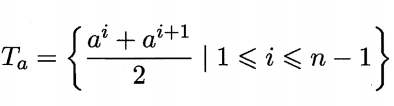
基于属性a,将集合划分为大于Ta的样本集T+,不大于Ta的样本集T-,后面就按离散值的方法处理。
需注意的是,与离散属性不同,若当前结点划分属性为连续属性,该属性还可作为其后代结点的划分属性.
例如在父结点上使用了"密度’’<0.381" ,不会禁止在子结点上使用"密度’’<0.294.
b.缺失值问题
我们需解决两个问题: (1) 如何在属性值缺失的情况 进行划分属性选择?
(2) 给定划分属性?若样本在该属性上的值缺失,如何对样本进行划分?
解决:将缺失后的样本集作为总样本集D进行计算信息增益,然后乘以缺失的样本集总样本数与总样本数的比值,西瓜书p87-88看计算例子(略)
5.多变量决策树
分类边界的每一段都是与坐标轴平行的,这样的分类边界使得学习结果有较好的可解释性,因为每一段划分都直接对应了某个属性取值.例如:
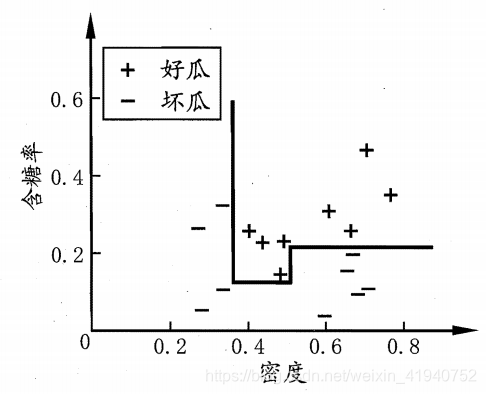
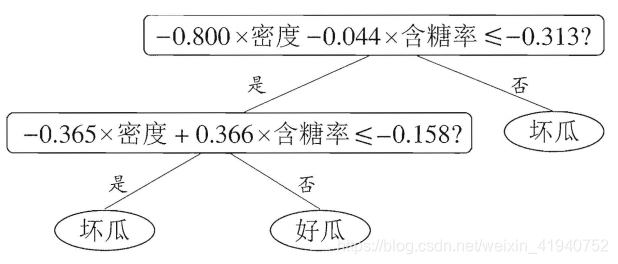
但此时的决策树会相当复杂,由于要进行大量的属性测试,预测时间开销会很大.若能使用斜的划分边界,则决策树模型将大为简化。如图:
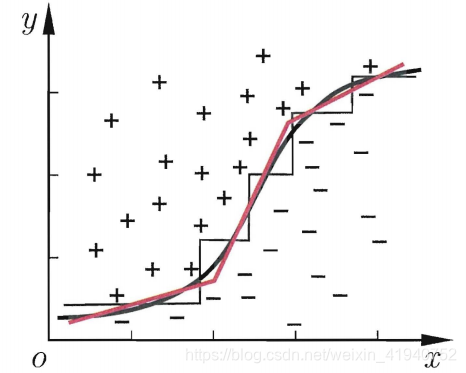
则决策树可转为斜线划分,如:
示例代码
# -*- coding: UTF-8 -*-
# DictVectorizer:数据类型转换
from sklearn.feature_extraction import DictVectorizer
# csv:原始数据放在csv文件中,该package为python自带,不需要安装
import csv
#引入数据预处理包、决策树包、读写字符串包
from sklearn import preprocessing
from sklearn import tree
from sklearn.externals.six import StringIO
#从csv文件中读取数据,并保存到allElectronicsData变量中
allElectronicsData = open(r'buy_or_not.csv','r')
# csv的reader方法按行读取数据
reader = csv.reader(allElectronicsData)
#next方法读取到csv文件的第一行数据
headers = next(reader)
#打印第一行数据
print(headers)
#建两个list,featureList装特征值,labelList装类别标签
featureList = []
labelList = []
#遍历csv文件的每一行
for row in reader:
#将类别标签加入到labelList中
labelList.append(row[len(row)-1])#一行的最后一列为标签
#下面这几步的目的是为了让特征值转化成一种字典的形式,就可以调用sk-learn里面的DictVectorizer,直接将特征的类别值转化成0,1值
rowDict = {}
for i in range(1,len(row)-1):
rowDict[headers[i]] = row[i]
featureList.append(rowDict)
print(featureList)
#实例化
vec = DictVectorizer()
dummyX = vec.fit_transform(featureList).toarray()
print("dummyX:"+str(dummyX))
print(vec.get_feature_names())
# label的转化,直接用preprocessing的LabelBinarizer方法
lb = preprocessing.LabelBinarizer()
dummyY = lb.fit_transform(labelList)
print("dummyY:"+str(dummyY))
print("labelList:"+str(labelList))
#criterion是选择决策树节点的标准,entropy信息熵,即ID3算法;默认标准是gini index,即CART算法。
clf = tree.DecisionTreeClassifier(criterion = 'entropy')
clf = clf.fit(dummyX,dummyY)
print("clf:"+str(clf))
#生成dot文件
with open("allElectronicInformationGainOri.dot",'w') as f:
f = tree.export_graphviz(clf,feature_names = vec.get_feature_names(),out_file = f)
#测试代码,取第1个实例数据,将001->100,即age:youth->middle_aged
oneRowX = dummyX[0,:]
print("oneRowX:"+str(oneRowX))
newRowX = oneRowX
newRowX[0] = 1
newRowX[2] = 0
print("newRowX:"+str(newRowX))
#预测代码
predictedY=clf.predict(newRowX.reshape(-1, 10))
print("printedY:"+str(predictedY))

















 792
792

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









