






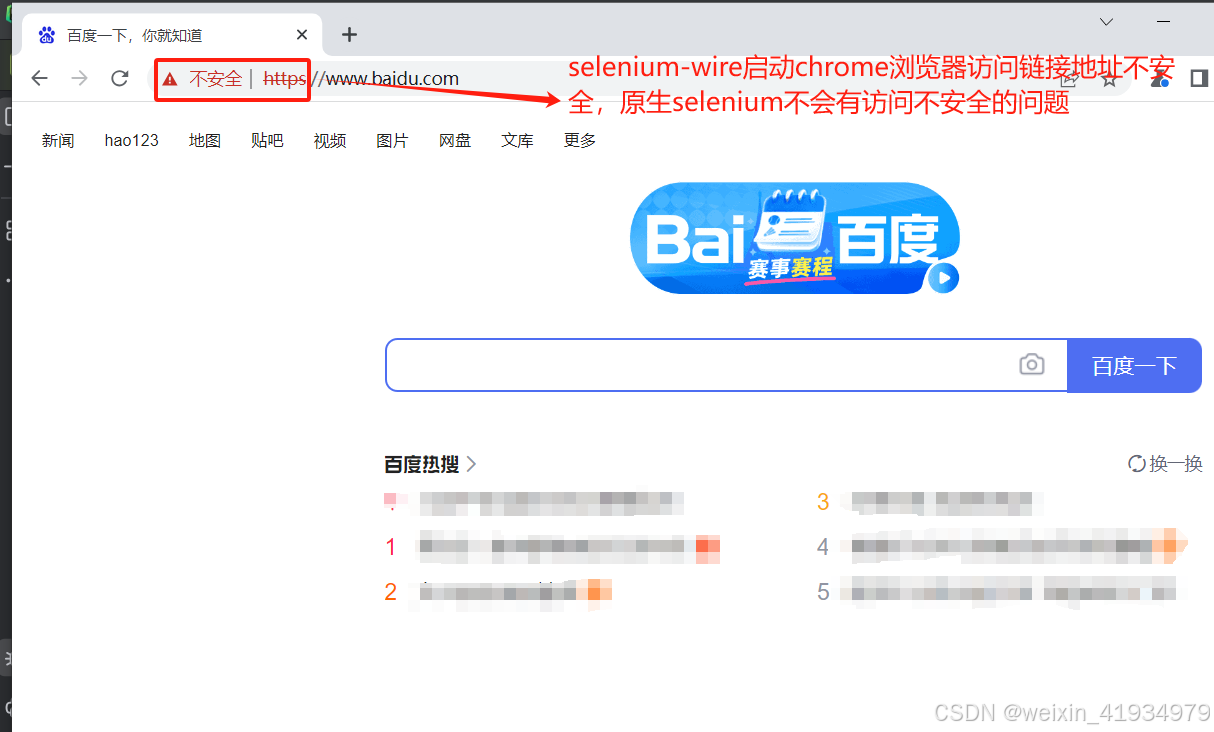
selenium-wire访问不安全如下:
pip安装selenium-wire
描述:这里用的是python3.12.2 selenium-wire==5.1.0
pip3.12 install selenium-wire
pip3.12 install blinker==1.7
pip3.12 install setuptools运行以下命令来获取证书
python -m seleniumwire extractcert
安装浏览器ssl证书
Windows上给chrome浏览器安装证书
方式一:
浏览地址栏输入:
chrome://settings/security方式二:
打开chrome浏览器(selenium-wire驱动的chrom浏览器)--》点击设置--》隐私和安全--》安全--》
管理设备证书--》受信任的根证书颁发机构
点击 受信任的根证书颁发机构 导入刚才执行命令获取的ca.crt(安全证书)






重新运行,成功解决

Linux 的系统,使用以下命令从终端安装证书
-i: 是ca.crt文件的路径
CentOS
yum install nss-toolscertutil -d sql:$HOME/.pki/nssdb -A -t TC -n "Selenium Wire" -i /usr/packages/ca.crtUbuntu
apt install libnss3-toolscertutil -d sql:$HOME/.pki/nssdb -A -t TC -n "Selenium Wire" -i /usr/packages/ca.crt
















 620
620

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









