







 本文探讨了在SeleniumUI自动化中遇到的元素失效问题,分析了原因并提出使用XPath作为不受元素属性、层级和网页结构影响的稳定定位方式。XPath通过路径表达式选取XML文档中的节点,介绍了基本类型、节点关系、XPath语法、谓语和通配符的使用,以及XPath在实际项目中的应用和IFrame处理方法。
本文探讨了在SeleniumUI自动化中遇到的元素失效问题,分析了原因并提出使用XPath作为不受元素属性、层级和网页结构影响的稳定定位方式。XPath通过路径表达式选取XML文档中的节点,介绍了基本类型、节点关系、XPath语法、谓语和通配符的使用,以及XPath在实际项目中的应用和IFrame处理方法。
为什么使用xpath
元素失效的场景
做过selenium UI自动化的同学会经常遇到元素失效的问题,主要集中以下三种情况
-
在A机器上可以,在B机器上不行
-
刚刚还能校验成功,网页刷新后就不行了
-
昨天还可以校验成功,今天就不行了
元素为什么会失效
-
元素没有id和class属性,需要依赖其他属性(其他属性稳定性比较差)
-
虽然有id和class属性,但是这些属性值可能改变
-
元素本身属性没有变化,但是网页的机构发生了变化,会导致元素的层级发生变化
-
元素特殊原因无法直接捕获
总的来说,定位条件产生变化和网页结构不稳定是元素失效的主要原因,那么我们是否能找到不受元素属性、层级、和网页结构影响又灵活稳定的定位方式呢,那就是xpath
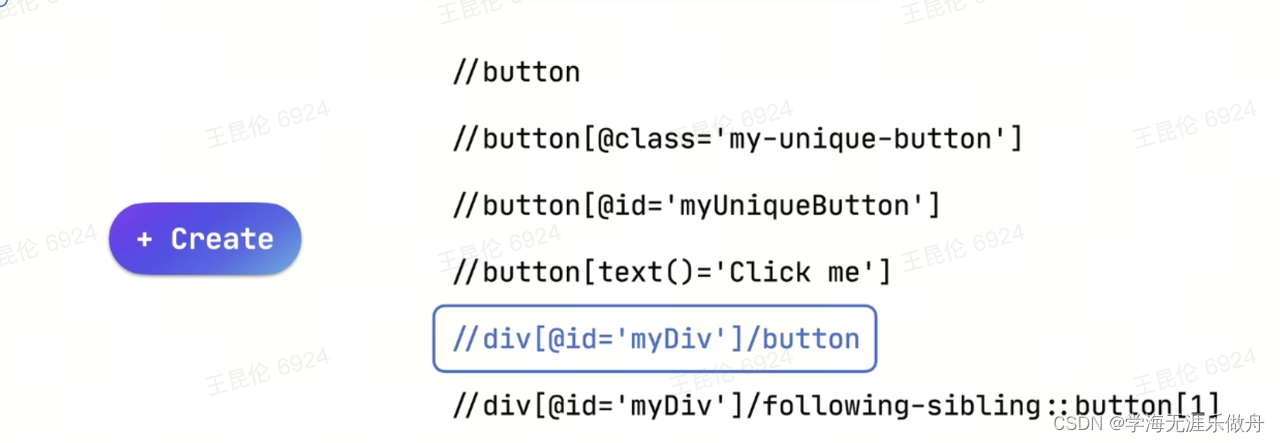
同一个按钮的多种定位方式
XPath 介绍
XPath (XML Path Language) 是一门在 XML 文档中查找信息的语言,可用来在 XML 文档中对元素和属性进行遍历。
XPath定位在爬虫和UI自动化测试中都比较常用,通过使用路径表达式来选取 XML 文档中的节点或者节点集,熟练掌握XPath可以极大提高提取数据的效率。。
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book>
<title lang="en">Harry Potter</title>
<author>JK.Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>基本类型
1、节点
标题:`<h1>、<h2>、<h3>、<h4>、<h5>、<h6>、<title>`
段落:<p>
链接:<a>
图像:<img>
样式:<style>
列表:无序列表<ul>、有序列表<ol>、列表项<li>
块:<div>、<span>
脚本:<script>
注释:<!--注释-->
2、文本数据
处于两个尖括号中的数据,即:>文本数据<
3、属性数据
由一个属借键和属性值组成更多HTML学习可以参考W3School文档:https://www.w3school.com.cn/html/in
节点关系
父(Parent)
每个元素以及属性都有一个父。
在下面的例子中,book 元素是 title、author、year 以及 price 元素的父:
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>子(Children)
元素节点可有零个、一个或多个子。
在下面的例子中,title、author、year 以及 price 元素都是 book 元素的子:
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>同胞(Sibling)
拥有相同的父的节点
在下面的例子中,title、author、year 以及 price 元素都是同胞:
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99&l 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









