







 本文介绍了如何使用Selenium Python库来模拟浏览器抓取淘宝网站的商品信息,因为淘宝网页的数据通过Ajax加载且参数复杂,直接分析API难以获取全部数据。通过Selenium可以完整获取网页内容,包括数据提取、清洗和存储到MongoDB的过程。
本文介绍了如何使用Selenium Python库来模拟浏览器抓取淘宝网站的商品信息,因为淘宝网页的数据通过Ajax加载且参数复杂,直接分析API难以获取全部数据。通过Selenium可以完整获取网页内容,包括数据提取、清洗和存储到MongoDB的过程。
1.数据提取前期网页分析
分析:淘宝网页数据也是通过Ajax技术获取的,但是淘宝的API接口参数比较复杂,可能包含加密密匙等参数;所以,想要通过自己构造API接口获取完整网页信息很难实现(可能只有部分信息),如下图:
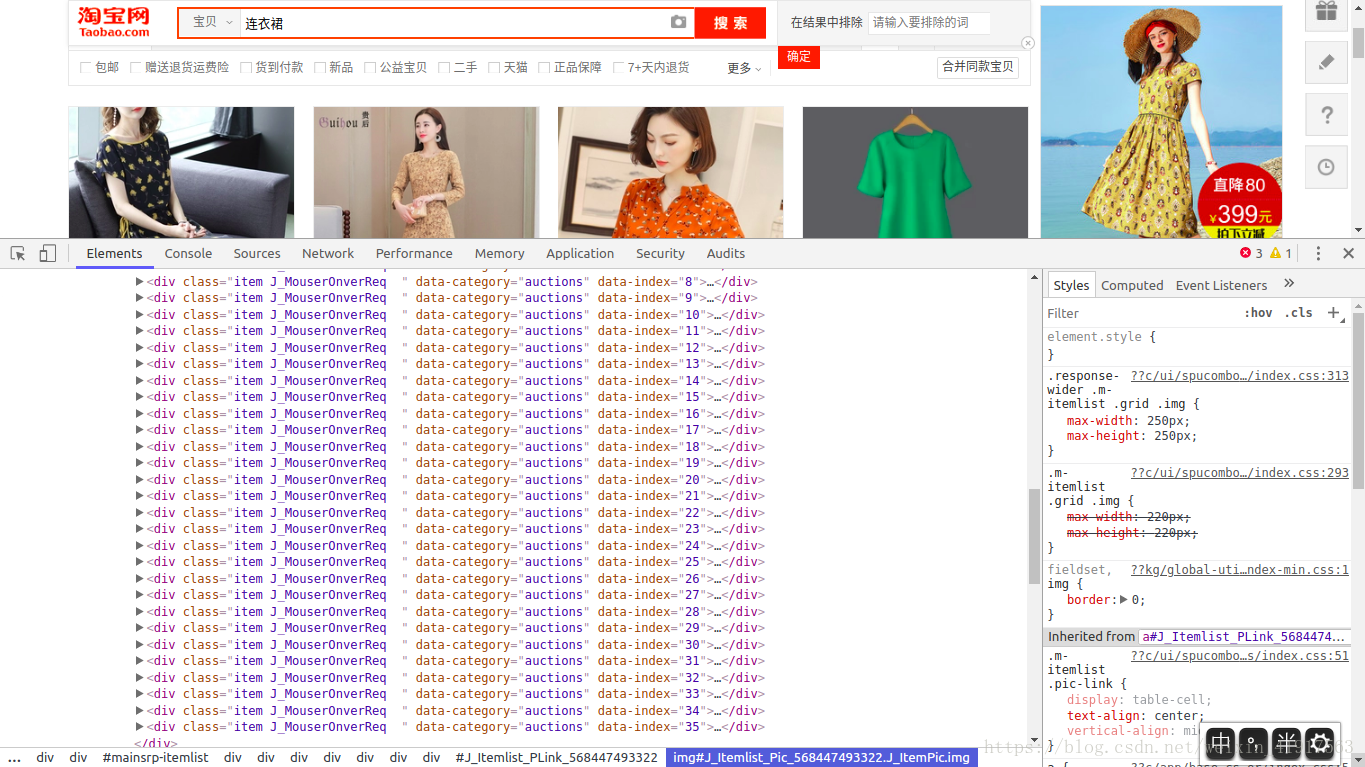
图一 实际的网页信息,每一网页有44条商品信息
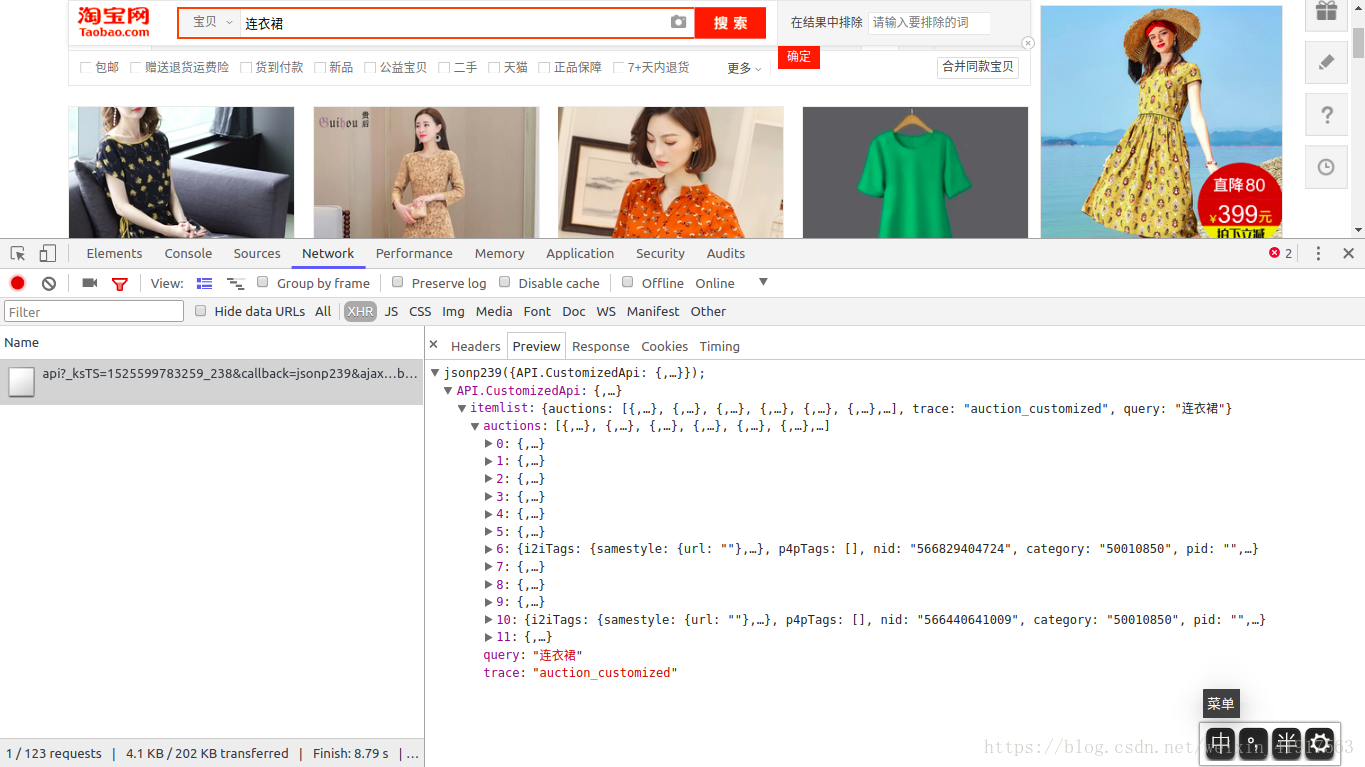
图二 实际后台的API接口可以找到,但信息不完整(只有11条商品信息),而且部分参数加密
所以,分析至此,不采用Ajax分析;直接使用Selenium模拟浏览器进行数据爬取
2.代码实现+数据清洗+数据存储,如下TaobaoSpider.py
#!/usr/bin/env python
# encoding: utf-8
"""
@version: 1.0
@Python version:2.7.14
@software: PyCharm
@file: TaobaoSpider.py
@time: 18-5-6 下午3:40
"""
import re
from pyquery import PyQuery as pq
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import p 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1390
1390

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









