







 本文深入探讨Git的存储对象,包括blob、tree和commit,以及Git的3个分区(工作目录、索引和Git仓库)。详细解析了提交过程、指针(HEAD、分支和Tag)的工作方式,同时解答了Git如何保证历史不被篡改、每次commit存储内容的策略以及文件权限和文件名存储位置的问题。理解这些原理有助于更高效地使用Git。
本文深入探讨Git的存储对象,包括blob、tree和commit,以及Git的3个分区(工作目录、索引和Git仓库)。详细解析了提交过程、指针(HEAD、分支和Tag)的工作方式,同时解答了Git如何保证历史不被篡改、每次commit存储内容的策略以及文件权限和文件名存储位置的问题。理解这些原理有助于更高效地使用Git。
Git原理初探
一、Git存储对象
Git中有三种存储的对象,它们分别是blob,tree和commit,每一种的每一个对象都用SHA1算法对其内容进行计算得到一个哈希值key,作为其唯一标识。可以使用命令:
git cat-file -t <key>
git cat-file -p <key>
分别去查看这个对象的类型和内容。注意:直接使用cat命令是查看到是被git压缩后的内容。它们存储的位置在目录:.git/object下。
1.blob
blob对象是Git中占用空间最大的对象,因为其直接对应一个文件内容,注意不包括文件名,和文件权限。每使用一次git add 就会在git仓库中新增blob对象。Git会根据文件的内容生成一个key指向这个blob。其类型和内容显示方式分别如下:


你一定想知道,这个key值是怎么来的,不急,接着往下看~
2.tree
tree对象是指一次项目快照,项目快照是指一个文件列表,每个条目包含了文件的权限,类型,文件内容的hash值,文件名。这个hash就会指向一个blob对象。同样根据tree的内容生成一个唯一的key。

3.commit
commit对象是指一次提交,提交的内容包括了上一个commit,作者,提交人,提交log,签名。同样会根据提交的内容生成一个key指向它。

4.初看一次提交的过程
(1)初始化一个git 仓库
git init
(2)添加两个文件
echo "111" > file1.txt
echo "222" > file2.txt
(3)git add
git add .
此条命令后,就可以看到在目录**.git/object**目录下出现了两个目录,这个目录以哈希值的前两位作为文件名,对所有对象进行了归档。

两个目录下分别存在两个blog对象,其内容恰为"111"和"222"。


(4)git commit
可以看到目录下又出现了两个对象,分别为一个tree对象和一个commit对象。
tree对象:
commit对象
5.小结
本小结介绍了Git中的三个基本存储对象,小结三类存储对象的关系如下图:
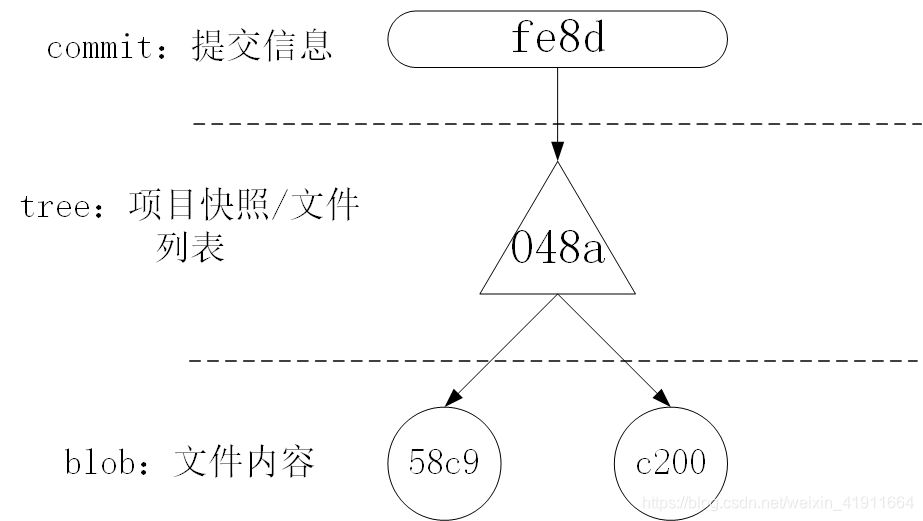
二、Git的3个分区
Git存在三个分区,分别为工作目录,索引,Git仓库。
(1)工作目录是指使用git add命令前,所有的修改存在的区域;
(2)索引就是一个tree对象,但其并未被存储到git仓库中。它记录了上一次add后的项目快照。
(3)Git仓库就是存储了所有的对象的地方。
在一次提交过程中,分区的变化可以分为三个阶段:git add前,git add后与git commit前以及git commit后。
1.阶段1:git add前
此时所有的修改都只存在于工作目录,如新增一个文件时,这个文件时为跟踪的,并不以blob的形式存在于git 仓库。
2.阶段2:git add后&&git commit前
当使用git add命令后,会有两步操作:
(1)被修改,添加或删除的文件将会生成一个新的blob对象,并存储到git仓库中。
(2)索引(暂存区)将从旧的blob对象指向新的blob对象
3.阶段3:git commit后
使用git commit命令后,则会有三步操作:
(1)索引区的内容将会生成一个新的tree对象,存储到git仓库中
(2)生成一个新的commit对象,指向这个tree对象,并存储到git仓库中
(3)HEAD将指向这个新的commit对象
看到这里,会不会有一种git原来是这样运行的想法!
三、Git的指针
ref是reference的缩写,而Git中有三类指针,HEAD,分支,Tag。没错,它们都是指针。不信,请看:
(1)分支
查看当前所在的分支是master

查看这个分支的内容是啥:
在目录**.git/refs/heads**下可以找到所有的分支,查看master的内容,我们惊喜的分线发现,这个id四层相识,没错它指向了commit,因此,实际上分支就是一个指向commit的指针。同样的Tag也是如此。

(2)HEAD
可以看到HEAD实际上指向的是一个分支,而分支实际上指向的就是一个commit,因此HEAD实际上指向的就是一个commit。

(3)git reflog
这条命令实际上记录了HEAD的变化历史,如果我们想要找到一个丢失了的分支或者commmit,我们就可以使用这条命令,配合命令:
git reset --hard commit-key
回到想要回去的分支。哈哈,这个是不"是(很)腻害~"。
四、有意思的问题
1.Git是如何保证历史不被篡改的?
答:想想看,当你修改一个提交内容后,这个提交对应的hash值就会改变,而这个hash将作为之后的提交的内容,因此下一个提交的hash值也会改变,这样,当前提交以及之后的提交的hash全部要改变。
2.每次commit,Git存储的是全新的文件快照还是变更部分?
答:全新的文件快照。如果使用变更部分作为存储,那么如果我们想要回复本次的文件快照,那么我们就要遍历之前的所有的快照,并依次应用变更,这样的操作就是O(n)的复杂度,而全新的,只要O(1)。
3.为什么文件权限和文件名存储在Tree Object而不是Blob Object?
答:文件权限和文件名与文件内容分离的方式,可以使用文件内容被复用。也就是说,当我们只更改了文件权限和文件名,却要重新创建一个Blob对象,众所周知,Blob对象所占用的存储空间是巨大的,这样显然不划算。因此分离的方式,本质上就是为了减少存储开销。
五、总结
本文从Git的3个基本概念——存储对象,分区和指针来讲解Git的基本原理,并列举了几个问题。
参考
本文大量参考了视频https://www.bilibili.com/video/av77252063里的技术分享。
shower thought
为什么要掌握Git的原理?也许有人说,git只是一个工具,我只要会使用简单的git命令进行提交就可以了。但是,事实果真如此吗?你可以保证自己在使用git的时候不会因为误操作而删除一个分支,你愿意明明可以通过git stash保存自己的修改的情况下还要通过文件的复制+git reset的低效的方式去应对突如其来的需求吗,当你在抓耳挠腮,苦苦等待不在工位上的支撑组同事的帮助时,已经耗费了太多的时间和精力。因此,为了更高效地使用git,也为了在解决问题的时候不依赖他人,掌握一定的git原理实际上就是在节省自己的时间。就像一个开发者必须掌握开发也需要会解决编译问题一样。引用侯捷的一句话,“源码之前,了无秘密”。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









