






关键点检测器和描述子是点云配准的两个主要组成部分。以往基于学习的关键点检测器依赖于每个点的显著性估计或最远点样本(FPS)来选择候选点,效率低下,不适用于大规模场景。针对大规模点云配准问题,提出了一种基于随机样本的关键点检测器和描述子网络(RSKDD-Net)。关键思想是使用随机抽样来有效地选择候选点,并使用基于学习的方法来联合生成关键点和描述符。为了解决随机抽样的信息丢失问题,我们采用了一种新的随机扩张聚类策略来扩大每个抽样点的接受域,并采用一种注意机制来聚集相邻点的位置和特征。此外,我们提出了一个匹配损失,以弱监督的方式训练描述符。在两个大规模室外激光雷达数据集上的大量实验表明,所提出的RSKDD-Net实现了最先进的性能,比现有方法快15倍以上。
点云配准是三维计算机视觉中的一个重要问题,它旨在估计两点云之间的最优刚性变换。3D关键点检测和描述是点云配准的两个基本组成部分。受众多手工制作的2D关键点探测器和描述符[1-3]的启发,研究人员提出了一些手工制作的3D关键点探测器[4-6]和描述符[7-11]用于点云。然而,图像中额外的RGB通道所包含的信息比没有RGB信息的点云欧氏坐标更丰富,这使得手工制作的3D关键点检测器和描述符的可靠性低于2D图像。
随着深度学习的快速发展,许多著作探索了点云中基于学习的三维描述符方法[12-15]。然而,由于缺乏关键点检测器[16]的ground truth数据集,基于深度学习的三维关键点检测方法鲜有研究。
3DFeatNet[17]和USIP[16]是两个开创性的基于学习的关键点检测器,但它们的效率考虑较少。3DFeatNet预测每个输入点的显著性,并根据预测的显著性选择关键点。逐点显著性估计需要相当长的时间,不适合实际应用。USIP依赖FPS生成候选关键点。而FPS的时间复杂度为O(n2),效率低,耗时长。因此,两者都是上述方法无法有效处理大规模点云,限制了其在自动驾驶等需要实时性能的场景中的应用。
基于上述观察,我们提出了一种基于随机样本的关键点检测器和描述子网络(RSKDD-Net),该网络能够有效地联合生成大规模点云的关键点和相应的描述子。本文在RSKDD-Net中引入随机样本的概念来提高我们的网络的效率,这在3DFeatNet和USIP中是没有考虑到的。随机采样是一种高效的方法,已应用于点云语义分割中以提高效率[18],但会导致相当大的信息损失。受扩张策略在二维图像[19]深度学习中的成功启发,我们提出了一种新的随机扩张策略来聚类邻近点,显著扩大了接受域。我们利用注意机制聚合相邻点的位置和特征,生成关键点,并利用注意特征图估计每个关键点的显著性不确定性。生成框架避免了3DFeatNet[17]中低效的点显著性估计。为了联合学习关键点检测器和描述子,将聚类和注意的特征映射进一步输入描述子网络以生成描述子。为了以弱监督的方式训练描述符,我们引入了匹配损失,它利用软分配策略来估计关键点的对应关系。网络结构如图1所示。
进行了大量的实验来评估我们的RSKDD-Net。结果表明,我们的方法在较短的计算时间内达到了最先进的性能。
总结而言,我们的主要贡献如下:
•我们提出了一种基于深度学习的方法来联合检测大规模点云配准的关键点并生成描述符。该方法的速度提高了15倍以上,达到了最先进的性能
•我们提出了一种新的随机扩张策略来扩大接受野,显著提高了关键点检测器和描述子的性能。此外,引入了一种注意机制来聚合相邻点的位置和特征。
•我们提出了一种基于软赋值策略的有效匹配损失,使描述符可以以弱监督的方式训练。
现有的点云关键点检测器和描述器方法可分为手工方法和基于学习的方法。
目前手工制作的3D关键点检测器和描述符主要受到2D图像中大量手工制作方法的启发。SIFT-3D[5]和Harris-3D[6]是广泛使用的2D探测器SIFT[2]和Harris[3]的3D扩展。内在形状特征(ISS)[4]选择在一个球区域中相邻点沿每个主轴有较大变化的点。对于关键点的描述,研究人员还开发了基于点几何特征的3D描述符,如点特征直方图(PFH)[7]、快速点特征直方图(FPFH)[8]和方向特征直方图(SHOT)[9]。手工制作的3D探测器和描述符的全面介绍可以在[20,21]中找到。
近年来,基于深度学习的方法被广泛应用于点云分析[22-29]。与我们的工作最相关的方法是3DFeatNet[17]和USIP[16]。与之前基于学习的描述符[12]不同,3DFeatNet提出了一种弱监督的3D描述符。该网络根据点云的距离对正负对进行采样,并利用三联体网络训练描述子。对于关键点检测,他们只是简单地预测点云中每个点的注意权值,并选择显著点,而没有进行更精确的优化。与3DFeatNet不同,USIP的重点是关键点检测器以及如何在完全无监督的情况下训练检测器。他们使用FPS对候选关键点进行采样,并使用SOM[25]组织点云。通过对原始候选点的偏移量和显著性不确定性的预测来选择关键点。USIP提出了概率倒角损失和点对点损失来训练网络完全无监督。但是,在USIP中对3DFeatNet和FPS每个点的显著性估计都是低效的。
我们提出的RSKDD-Net的网络结构如图1所示。首先将输入点云P∈RN×(3+C)(三维欧氏坐标和C个附加通道)输入到检测器网络中。利用随机扩张聚类对相邻点进行聚类,然后利用关注点聚合模块生成关键点X∈RM×3、显著性不确定性Σ∈RM和关注特征图。聚类和注意的特征映射被进一步输入描述符网络以生成相应的描述符。我们用概率倒角损失和点对点损失训练检测器网络,用提出的匹配损失训练描述子网络。
对于每个输入点云P∈RN×(3+C),我们首先随机抽样M个候选点。一般以候选点为中心,对M个簇进行k次kNN (nearest neighbor)搜索。随机抽样虽然有效,但会导致信息丢失和扩大接受范围field是弱化负面效应的有效策略。但是,简单地增大相邻点K的数量会增加时间和空间的复杂性。扩张是在许多领域扩大接受野的一种替代策略[30,19]。[31]在3D点云中引入了扩张点卷积(DPC)。与DPC不同,我们采用随机膨胀策略生成聚类,该方法的可视化解释如图2所示。假设为单个簇选择K个邻居点,膨胀比记为αd。我们首先搜索中心点的αd × K个相邻点,然后从中随机抽取K个点。该方法简单有效,将接收域从K扩展到αd × K,几乎不增加计算量。
注意力机制在点云学习中取得了很好的表现[32-36]。在本文中,我们提出了一种简单的注意机制来聚集邻居点,直接生成关键点,而不是像USIP[16]那样预测偏移量。由随机膨胀聚类得到M个聚类,每个聚类由K个点组成。考虑一个聚类,其中中心点和K个邻居点分别记为pi和{pi1,···,pik,···,pik}∈RK×(3+C)。用中心点减去相邻点的欧几里得坐标,得到相邻点的相对位置。此外,计算相邻点到中心点的相对距离作为簇的一个额外通道。因此,单簇的特征记为F i = {F i1,···,F ik,···,F ik}∈RK×(4+C)。然后将聚类输入到共享多层感知器(MLP)中,并输出一个特征映射(F i = {F i1,···,F ik,···,F ik}∈RK×Ca)。
使用带有Softmax函数的maxpool层预测每个相邻点的一维注意权值{wi1,···,wik,···,wik}∈RK×1。生成的关键点~ xi被计算为相邻点的欧几里得坐标的加权和。记邻居点的欧氏坐标为{xi1,···,xik,···,xik}∈RK×3,则该簇的输出关键点~ xi∈R3可计算为
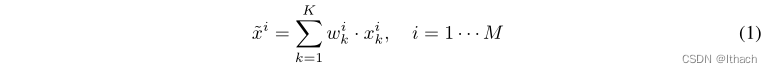
与USIP中的偏移量预测方法不同,我们的注意点聚合方法确保生成的关键点在输入聚类的凸包内。然后,赋予每个特征f ik一个相应的关注权重wik,得到一个关注特征映射~ f i∈RK×Ca as
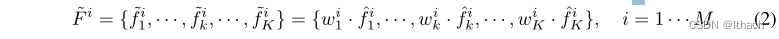
对注意的特征图进一步求和,为每个聚类输出一个全局特征~ f i∈RCa。
在此基础上,利用Softplus函数对各关键点的显著性不确定性σi进行预测。检测器网络的输出是M个具有相应显著性不确定性的关键点,也是具有注意特征映射{F 1,···,F M}的聚类{F 1,···,~ F M}。最后,在无最大抑制的情况下,选取显著性不确定性较低的关键点。
描述符的网络结构如图1底部一行所示。描述子网络的输入是来自检测器网络的随机膨胀簇{F 1,···,F M}和注意的特征映射{~ F 1,···,~ F M}。首先将聚类F i输入到共享MLP中获得每个相邻点的单个特征,然后应用maxpool层获得Cf维全局聚类特征。在此之后,复制全局聚类特征,然后与单个点特征和注意的特征映射~ F i连接。连接的特征映射进一步传递到另一个具有maxpool层的共享MLP中,以生成d维描述符。来自探测器网络的注意特征图显著提高了描述子的性能,我们将说明其在消融研究中的有效性。
源点云和目标点云分别记为S和T,源点云和目标点云的关键点分别记为XS和XT,对应的显著性不确定性分别记为ΣS和ΣT,描述符分别记为QS和QT。
同时给出了相对旋转R和平动t的ground truth。为了训练检测器,我们遵循USIP[16]使用概率倒角损失和点对点损失。利用概率倒角损失最小化源点云和目标点云中的关键点之间的距离,定义点对点损失来惩罚距离原始点云太远的关键点。概率倒角损耗和点对点损耗详见[16]。
我们提出匹配损失以弱监督的方式训练描述符。
3DFeatNet[17]中的三元组损失根据两点云的距离对正负描述子对进行采样,没有利用关键点的几何位置。与3DFeatNet不同,我们的匹配损失的关键思想是一种软赋值策略,它显式地估计描述符的对应关系。对于每个源关键点~ xSi∈XS和对应的描述子qSi∈QS,计算所有目标关键点与描述子的欧氏距离,记为dSi = {dSi1,···,dSij,···,dSiM},其中dSij = ?? ?qSi−qTj ??2 2。匹配分数向量记为sSi = {sSi1,···,sSij,···,sSiM},可计算为
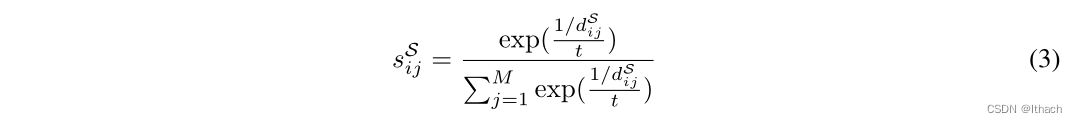
其中t为温度来锐化匹配分数的分布。那么对应的~ xSi关键点可以表示为所有目标关键点的加权和,
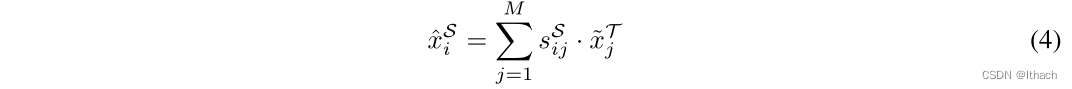
软赋值可以被认为是描述符上最近邻搜索的近似可推导版本。直观地说,与源关键点描述符更相似的目标关键点将得到更高的分数。当t→0时,软赋值将退化为确定性最近邻搜索。同样,我们也可以使用软分配策略为每个目标关键点计算相应的源关键点。进一步,根据每个关键点的显著性不确定性Σ i∈Σ,为每个关键点引入权重,
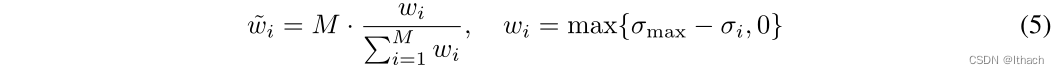
其中σmax为显著性不确定度预先定义的上界。最终的匹配损失旨在使估计的对应关键点之间的距离最小,可以表示为a
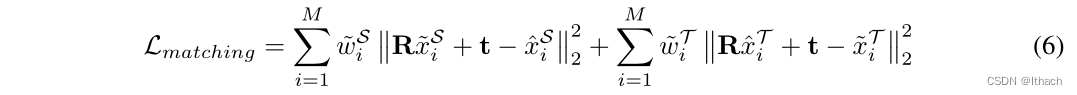
直观地说,匹配损失的减少将激励软赋值策略选择空间上较近的关键点作为匹配点,将匹配的描述符拉近,将不匹配的描述符拉远。此外,关键点权重的引入使得显著性不确定性较低的关键点在匹配损失中具有较高的权重。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









