







Abstract
大多数现有方法通过扩展用于3D对象检测或3D语义分割的模型来实现3D实例分割。然而,这些非直接方法有两个缺点:1)不精确的边界框或不令人满意的语义预测限制了整个3D实例分割框架的性能。2) 现有方法需要耗时的中间聚合步骤。为了解决这些问题,本文提出了一种基于Superpoint Transformer的端到端3D实例分割方法,称为SPFormer。它将点云中的潜在特征分组为superpoint,并通过查询向量直接预测实例,而不依赖对象检测或语义分割的结果。该框架中的关键步骤是一个带有transformer的新型查询解码器,它可以通过叠加交叉关注机制捕获实例信息,并生成实例的叠加掩码。通过基于叠加掩码的二分匹配,SPFormer可以实现网络训练,而无需中间聚合步骤,从而加快了网络速度。在ScanNetv2和S3DIS基准测试上的大量实验验证了我们的方法简洁而有效。值得注意的是,就mAP而言,SPFormer在ScanNetv2隐藏测试集上超过了最先进的方法4.3%,同时保持了快速的推断速度(每帧247毫秒)。
Introduction
3D场景理解被视为许多应用的基本要素,包括增强虚拟现实(Park等人2020)、自动驾驶(Zhou等人2020)和机器人导航(Xie等人2021)。通常,实例分割是3D场景理解中的一项具有挑战性的任务,其目的不仅是检测稀疏点云上的实例,还为每个实例提供清晰的遮罩。现有最先进的方法可分为基于提议的方法(Y ang等人2019年;Liu等人2020年)和基于分组的方法(Jiang等人2020年;Chen等人2021;Liang等人2021;Vu等人2022年)。基于建议的方法将3D实例分割视为自上而下的管道。他们首先生成区域建议(即边界框)如图1(b)所示,然后预测所提出区域中的实例掩码。Mask RCNN(He等人,2017)在2D实例分割领域的巨大成功鼓励了这些方法。然而,由于领域差距,这些方法在点云上举步维艰。在三维场中,边界框具有更大的自由度(DoF),增加了拟合的难度。此外,点通常只存在于物体表面的部分,这导致物体几何中心无法检测。此外,低质量区域建议会影响基于盒的二分匹配(Y ang等人2019),并进一步降低模型性能。相反,基于分组的方法采用自下而上的管道。他们学习逐点语义标签和实例中心偏移。然后,他们使用偏移点和语义预测聚合到实例中,如图1(c)所示。在过去两年中,基于分组的方法在3D实例分割任务中取得了很大的改进(Liang等人,2021;Vu等人,2022年)。然而,也有几个缺点:(1)基于分组的方法依赖于它们的语义分割结果,这可能导致错误的预测。将这些错误预测传播到后续处理会抑制网络性能。(2) 这些方法需要中间聚合步骤,增加训练和推理时间。聚合步骤独立于网络培训和缺乏监督,这需要额外的细化模块。通过上面的讨论,我们自然会想到一个超级框架,它可以避免缺点,同时从两种类型的方法中获益。在本文中,我们提出了一种基于Superpoint Transformer的端到端两阶段3D实例分割方法,称为SPFormer。SPFormer将点云中自下而上的潜在特征分组为叠加点,并通过查询向量作为自上而下的管道提出实例。在自底向上分组阶段,使用稀疏的3D U-net来提取自底向上地逐点特征。提出了一个简单的叠加点池层,将潜在的逐点特征分组为叠加点。叠加点(Landrieu和Simonovsky 2018)可以利用几何规律来表示同质相邻点。与之前的方法(Liang等人,2021)相比,我们的叠加特征是潜在的,避免了通过非直接语义和中心距离标签来监督特征。我们将叠加点视为3D场景的潜在中级表示,并直接使用实例标签来训练整个网络。在自顶向下的建议阶段,提出了一种新的带有变换器的查询解码器。我们利用可学习的查询向量从潜在的叠加特征中提出实例预测,作为自上而下的管道。可学习查询向量可以通过叠加交叉关注机制获取实例信息。图1(d)说明了这个过程,椅子的部分越红,查询向量的关注度就越高。通过携带实例信息和叠加特征的查询向量,查询解码器直接生成实例类、分数和掩码预测。最后,通过基于叠加点掩码的二分匹配,SPFormer可以实现端到端的训练,而无需耗时的聚合步骤。此外,SPFormer没有像非最大抑制(NMS)那样的后处理,这进一步加快了网络速度。SPFormer在ScanNetv2和S3DIS基准测试上都达到了最先进的水平。特别是,SPFormer在定性和定量测量以及推理速度方面同时超过了最先进的方法。具有新颖流水线的SPFormer可以作为3D实例分割的通用框架。总之,我们的贡献如下:
•我们提出了一种新的端到端两阶段方法,名为SPFormer,该方法在不依赖对象检测或语义分割结果的情况下,利用潜在的重叠特征来表示3D感觉。
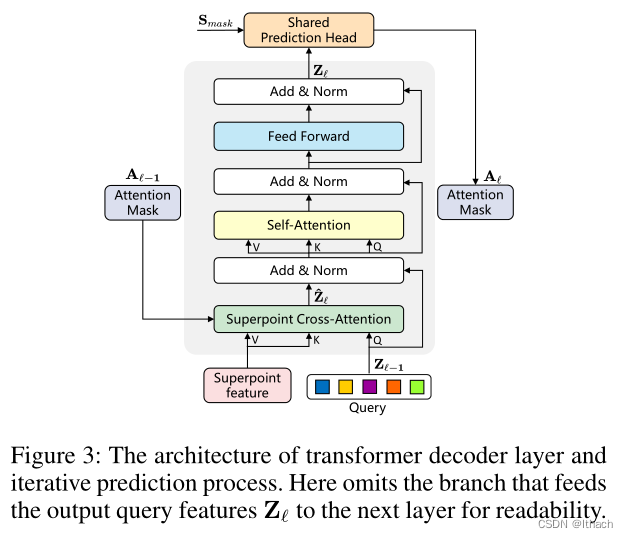
•我们设计了一个带有转换器的查询解码器,其中可学习的查询向量可以通过叠加交叉注意力来捕获实例信息。使用查询向量,查询去编码器可以直接生成实例预测。
•通过基于叠加点掩码的二分匹配,SPFormer可以实现网络训练,而无需耗时的中间聚合步骤,并且在推理过程中无需复杂的后处理。
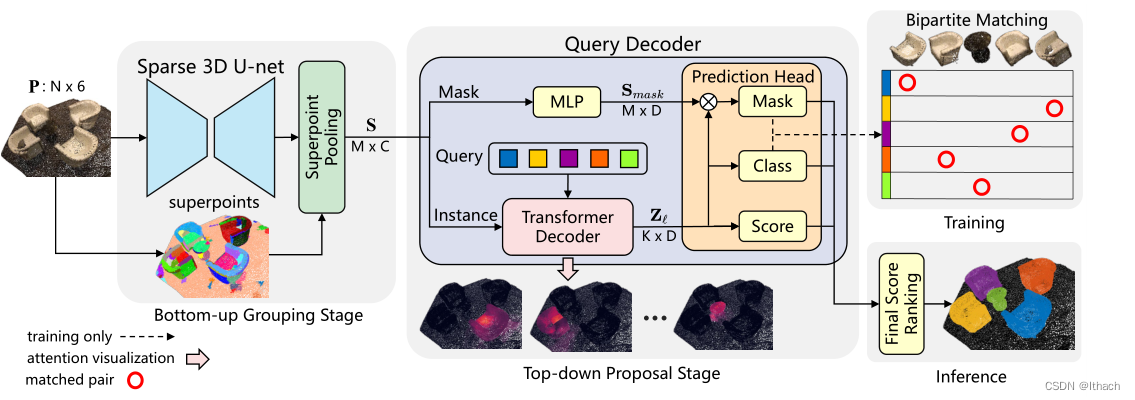
SPFormer的总体架构包括两个阶段。在自下而上的分组阶段,稀疏3D U-net从输入点云P中提取逐点特征,然后叠加池层将同质的相邻点分组为叠加特征S。在自上而下的建议阶段,查询解码器被分成两个分支。实例分支通过变换器解码器获得查询向量特征Z’。掩码分支提取掩码感知特征Smask。最后,预测头生成实例预测,并在训练/推理期间将其输入到二分匹配或排序中

















 909
909

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}