







 本文深入解析MapReduce中的Shuffle过程,介绍了数据如何从Mapper传递到Reducer的细节,包括环形缓冲区的应用、溢写机制、合并操作等关键技术点。
本文深入解析MapReduce中的Shuffle过程,介绍了数据如何从Mapper传递到Reducer的细节,包括环形缓冲区的应用、溢写机制、合并操作等关键技术点。
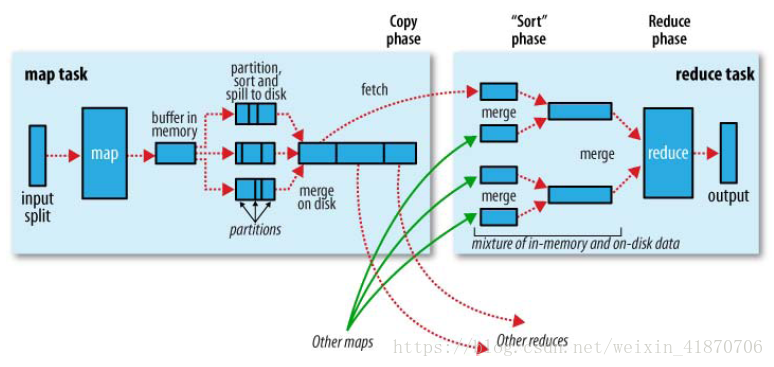
熟悉Mapreduce的同学,肯定对Map和Reduce的编写非常的6,那么从你的数据从Mapper类到Reducer类的传输要经过一个过程,这个过程就叫Shuffle,Shuffle过程是个无比重要的过程,它使你的数据从Mapper端出来之后更加整齐,规范,并且相同的Key的数据放在了一起输入到Reducer端,从某种意义上来说,Shuffle是MapReduce的心脏,是奇迹发生的地方。
Map端:
数据从Map端输出并不是简单的写到磁盘上,它利用缓冲的方式到内存中并且进行了预排序提升效率。
数据从map端出来之后先进入了一个环形内存缓冲区(是一种100M的byte数组,通过包装成intbuffer数据结构用于表示一个固定尺寸、头尾相连的缓冲区,适合缓存数据流。)用于存储任务输出,默认情况下,缓冲区的大小为100M,当然这个值可以通过参数来调节,一旦缓冲区的大小达到了阈值(默认缓冲区大小的80%,也可调),后台的进程便把缓冲区的数据溢写到磁盘上。
1:在缓冲区内的分区排序
分区-排序:根据数据最终要传的reducer把数据划分成相应的分区,在每个分区中,后来进程按键在内存中将数据进行了排序,如果有combiner函数,在分区排序之后,一些到磁盘之前要进行一次combinner,是map输出的数据更精简紧凑减少写到磁盘的数据和reducer的压力,也节省了网络IO资源。
2.环形缓冲区存内容
环形缓冲区实际是一个100M的byte数组,然后经过包装成intBuffer,它的写入分两部分,一是元数据信息的写入,一部分是key-value数据的写入,你可以将这个环形缓冲区理解为一个操场,先设定一个起点(原点),然后元数据写入和key-value值的写入背靠背反向进行写入,元数据主要是有4*4的16字节大小,包括的信息有partitons信息,key的起点位置,value起点位置,value的长度。
溢写:
每次内存缓冲区达到阈值以后,就会新建一个溢出文件(split file),所以到map任务写完最后一个输出记录之后,每个map任务会产生多个溢出文件的(如果溢出文件超过三个,则combiner会在输出文件写到磁盘之前再次运行,这个属性数量也可以设置,如果map溢写文件过少,不值得启动combiner产生的开销),但是在map任务完成之前,会将这些溢出文件合并成一个已经分区并且排序的输出文件,也有参数可以设置合并因子,调控一次可以合并多少个溢出文件,默认是10.
压缩输出文件:在将map输出文件到磁盘的过程中可以设置压缩文件和压缩格式,这样可以写入到磁盘速度更快,也可以减少reducer的数据量,并且节省磁盘空间,默认情况不压缩,可以设置参数mapreduce.map.output.compress设置为true,压缩的格式通过mapreduce.map.output.compress.codec指定。当然这些输出文件在reduce复制完成之后就删除了。
Reduce端:
map任务的输出文件一般是在tasktracker节点上的磁盘上,tasktracker要为分区文件运行reduce任务(reduce任务需要集群上若干个map任务的输出文件作为其特殊的分区文件),每个map运行的时间不同,所以在每个map任务完成时,reduce就开始复制其输出(每个map任务在完成之后,会通过心跳机制向applicationMaster汇报,所以applicationMaster知道每个输map输出与其主机的关系,reduce有一个专门的线程定期询问master来获取map输出主机的位置信息),reduce是通过少量的复制线程,并行取得map输出,默认是5个线程,可以通过mapreduce.reduce.shuffle.parallelcopies设置。
如果map的输出很小,就会复制到reduce任务的jvm内存,,越来越多的小map输出会使其占用大小越来 越大,一旦达到缓冲区阈值,这些小的map输出会被合并后溢写到磁盘中,如果有combiner,则在合并期间运行它来降低写入到硬盘的数据量
随着磁盘上reduce复制的副本增多,后台线程会将他们合并为更大的,排好序的文件(merge操作),为了合并,如果复制的文件是压缩的,则会在内存中解压后再进行合并。
复制完map的输出文件后,reduce任务进入了合并阶段,这个阶段将合并map输出,维持其顺序排序,这个阶段是循环的,比如reduce最终从map输出文件复制过来40个文件,而合并因子是10(默认设置可调),合并进行三趟,第一趟可能合并三个文件,第二趟,合并10个文件,第三趟合并10个文件,第四趟将前三部合并的三个大文件与最后剩下的7个没有合并的文件一起合并给reduce(减少写到磁盘的数据量)
在reduce阶段,对已排序输出中的每个键调用reduce函数,这个阶段的输出直接写到hdfs中。

















 213
213

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









