







书生模型实战系列文章目录
第一章 入门岛L0(Linux)
第二章 入门岛L0(python)
第三章 入门岛L0(Git)
第四章 基础岛L1(Demo)
第四章 基础岛L1(Prompt)
第四章 基础岛L1(RAG)
提示:以上内容可以看往期文章
第四章 基础岛L1(书生全链路开源介绍)
作业

提交作业


要点
要点:
-
🌟 开源开放体系涵盖数据收集、标注、训练、微调、评测、部署等全链路。
-
🚀 书生葡语大模型(英文名IN Turn LLM)多次开源,性能不断提升,达到国际先进水平。
-
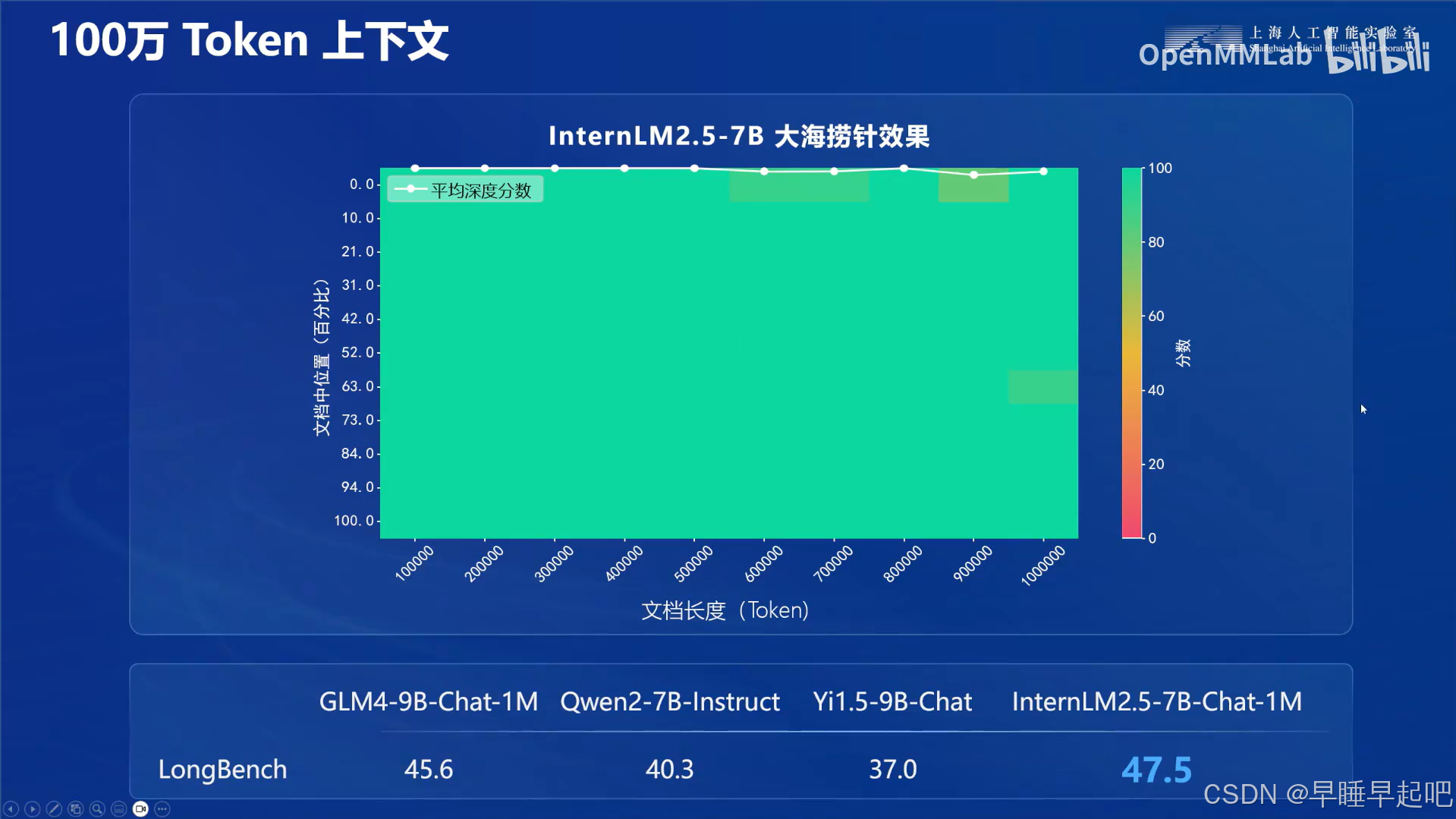
🔧 模型具备强大的推理能力,上下文记忆达到百万级别,支持自主规划和搜索。
-
📈 数据驱动,通过数据过滤、智能评估、指令生成等策略提升模型性能。
-
🛠️ 开源生态提供预训练框架、微调框架、部署工具、评测体系等,方便用户使用。
-
🏆 模型在推理能力、上下文记忆、自主规划等方面表现优异,可应用于多种场景。
-
📊 开源生态包含多种模态数据集,支持多种语言和任务类型。
-
🏢 实战营活动助力用户上手大模型开发,已有学员开发成功项目
超长上下文
基于规则和搜索解决复杂问题

开源模型体系

开源社区

大模型
自回归: 模型在生成下一个字符(token)时,会依赖之前生成的token,就像写故事一样,下一个plot依赖于之前的情节。这需要用到Attention ,它是模型理解上下文的一种方式,它需要记住(缓存)之前看到的词(k代表key,v代表value)。这会导致内存使用增加,因为模型需要同时记住很多信息。
Transformer中的注意力机制(Attention)在编码器(Encoder)和解码器(Decoder)中皆有应用,But它们的作用形式不大一致:
Encoder: 在编码器中,Self-Attention即每个词或者token都会关注整个输入序列的其他词,为的就是使得模型能够捕捉到输入序列内部长距离的依赖关系。 生成一个包含输入序列信息的表示。
Decoder: 与编码器不同的是,它的自注意力会屏蔽掉未来尚未生成的词,意思就是说主要用于token的生成当中,模型只关注之前已经生成的词,从而保证生成过程中的顺序性。
在深度学习中,使用不同的数值精度(如:FP16、BF16、FP32等)对模型训练和推理有着重要影响。这些精度会影响模型的计算效率,内存占用、以及最终的精度。
FP16(半精度浮点数): FP16使用16位表示浮点数,相比于32位的FP32,它可以减少内存带宽需求和加速计算。对于某些深度学习操作,使用FP16可以显著提高计算速度,尤其是在支持FP16计算的硬件上。在某些情况下,使用FP16可能会导致数值精度问题,比如梯度爆炸或梯度消失,尤其是在深度网络中。
FP32(单精度浮点数): FP32提供较高的数值精度,是深度学习中最常见的数值精度。它能够提供足够的精度,避免在训练过程中出现数值不稳定或梯度消失的问题。
BF16(Brain Floating Point): BF16是一种新的数值格式,旨在提供与FP32相似的动态范围,但只使用16位。它的设计目的是在保持FP32的动态范围的同时,减少内存和计算需求。
全链条开源开放体系之开源数据处理工具箱
①miner U高质量数据提取工具
②LabelLLM对话标注工具
③Label U图像领域标注工具
参考链接
https://www.bilibili.com/video/BV18142187g5/?spm_id_from=333.1245.0.0&vd_source=7658b43a2e9ae1c8300df7abad5e5b2c


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









