






 本文深入解析了B树和B+树的结构特点及其在数据库和文件系统中的应用,对比了两种树形结构的优劣,阐述了它们如何提高磁盘I/O效率。
本文深入解析了B树和B+树的结构特点及其在数据库和文件系统中的应用,对比了两种树形结构的优劣,阐述了它们如何提高磁盘I/O效率。
为什么要有B树
- 局部性原理:当一个数据被用到时,其附近的数据也通常会马上被使用。
- 同样的数据,红黑树(二叉树)阶数更大,B树更短,查找的效率越高。
B树
B树大量应用在数据库和文件系统中。
B树建立在二叉树和平衡二叉树的基础上。在二叉树中,每个结点只有一个元素。但是在B-Tree中,每个结点都可能包含多个元素,并且非叶子结点在元素的左右都有指向子结点的指针。
他的设计思想是,将相关数据尽量集中在一起,以便一次读取多个数据,减少磁盘操作次数。B树为系统最优化大块数据的读和写操作。B树算法减少定位记录时所经历的中间过程,从而加快存取速度。
B-Tree的特性有:
- 每个结点最多m个子结点
- 除根、叶结点,每个结点最少有m/2(向上取整)个子结点
- 如果根不是叶子结点,那根结点至少包含两个子结点
- 所有叶子结点都位于同一层
- 每个结点都包含k个元素(关键字),这里m/2 <= k < m (向下取整)
- 每个元素(关键字)左结点的值,都小于等于该元素(关键字)。右结点的值都大于等于该元素(关键字)
B-Tree的查询效率总是等价于二分查找,并不比平衡二叉树高。但是查询所经过的结点数量要少很多,也就意味着要少很多次的磁盘IO,这对性能的提升是很大的。
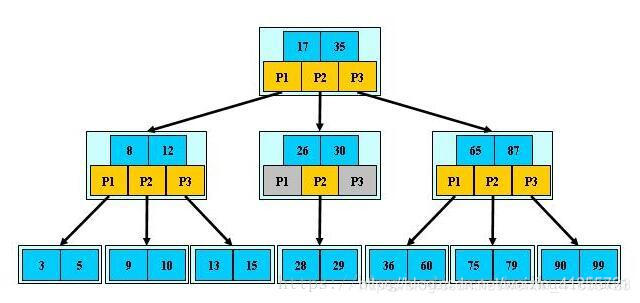
普通的B-Tree的结点中,元素就是一个个的数字。但是上图中,我们把元素部分拆分成了key-data的形式,key就是数据的主键,data就是具体的数据。这样我们在找一条数的时候,就沿着根结点往下找就ok了,效率是比较高的。
B树是二叉树的改进。
假定一个节点可以容纳100个值,那么3层的B树可以容纳100万个数据,如果换成二叉查找树,则需要20层!假定操作系统一次读取一个节点,并且根节点保留在内存中,那么B树在100万个数据中查找目标值,只需要读取两次硬盘。B 树可以看作是对2-3查找树的一种扩展,即他允许每个节点有M-1个子节点。
B+树
B+Tree是在B-Tree基础上的一种优化,使其更适合实现外存储索引结构。B+Tree与B-Tree的结构很像,但是也有几个自己的特性:
- 非叶子节点的子树指针与key个数相同
- 非叶子节点的子树指针P[i] 指向key值属于K[i],K[i+1]
- 所有的非叶子结点只存储关键字信息
- 所有具体数据都存在叶子结点中
- 所有叶子结点中包含了全部元素的信息
- 所有叶子节点之间都有一个链指针
即转化为
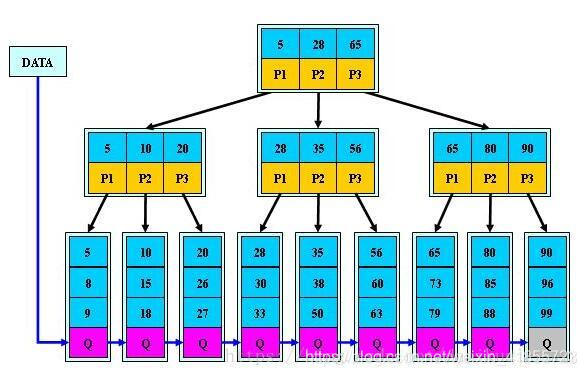
B树和B+树
首先,我们要知道,操作系统从磁盘读取数据到内存是以磁盘块为基本单位,位于同一个磁盘块的数据会被一次性读取除来,而不是需要什么取什么。即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据放入内存。
理论依据是计算机科学中著名的局部性原理:当一个数据被用到时,其附近的数据也通常会马上被使用。
预读的长度一般为页(page)的整倍数。页是计算机管理存储器的逻辑块,硬件及操作系统往往将主存和磁盘存储区分割为连续的大小相等的块,每个存储块称为一页(在许多操作系统中,页得大小通常为4k)。
B-Tree和B+Tree该如何选择呢?都有哪些优劣呢?
- B-Tree因为非叶子结点也保存具体数据,所以在查找某个关键字的时候找到即可返回。而B+Tree所有的数据都在叶子结点,每次查找都得到叶子结点。所以在同样高度的B-Tree和B+Tree中,B-Tree查找某个关键字的效率更高
- 由于B+Tree所有的数据都在叶子结点,并且结点之间有指针连接,在找大于某个关键字或者小于某个关键字的数据的时候,B+Tree只需要找到该关键字然后沿着链表遍历就可以了,而B-Tree还需要遍历该关键字结点的根结点去搜索。
- 由于B-Tree的每个结点(这里的结点可以理解为一个数据页)都存储主键+实际数据,而B+Tree非叶子结点只存储关键字信息,而每个页的大小有限是有限的,所以同一页能存储的B-Tree的数据会比B+Tree存储的更少。这样同样总量的数据,B-Tree的深度会更大,增大查询时的磁盘I/O次数,进而影响查询效率。
- B+树的非叶子节点不包含数据信息,所有内存页中能存放更多的key。数据存放得更加紧密,具有更好的空间局部性。因此访问叶子上关联的数据页具有更好的缓存命中率。
MySQL中InnoDB就是采用B+树的结构。
引用
https://www.e-learn.cn/content/qita/809639
https://www.cnblogs.com/nullzx/p/8729425.html

















 8
8

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









