






一、引言
在当今的数字化时代,用户评论对于了解产品的优点和缺点、用户需求以及市场趋势至关重要。本文将介绍作者如何通过爬虫技术获取某商城app的用户评论,并对其进行深入分析。
二、研究目的
本文的研究目的是利用爬虫技术获取商城app的用户评论,以便更好地了解用户对产品的看法、需求和市场趋势,废话不多说直接上代码
import requests
import csv
# 创建CSV文件
csv_file = open("comments.csv", mode="w", newline="", encoding="utf-8")
csv_writer = csv.writer(csv_file)
csv_writer.writerow(["commentLevel", "comment", "creationTime", "skuAttrs", "ipLocation"])
headers = {
"User-Agent": "Mozilla/5.0 (Linux; Android 13; 21091116AC Build/TP1A.220624.014; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/111.0.5563.116 Mobile Safari/537.36 VMall-APK/1.23.8.301/mdlType=21091116ACmdlType/",
"refer": "vmallClass",
"Origin": "https://mw.******.com",
"Referer": "https://mw.*******.com/",
"net-msg-id": "5e66f6c7032380d16938264811711571",
"x-nuwa-span-id": "5e66f6c723804474",
"x-nuwa-microservice-name": "APMS",
"Host": "openapi.*****.com"
}
url = "https://openapi.*******.com/rms/v1/comment/getCommentList"
# 爬取50页的数据
for page_num in range(1, 301):
params = {
"portal": "3",
"lang": "zh-CN",
"country": "CN",
"version": "12308301",
"pid": "10086009079805",
"extraType": "0",
"pageSize": "10",
"pageNum": str(page_num), # 更新pageNum参数为当前页数
"sortType": "1",
"showStatistics": "true"
}
response = requests.get(url, headers=headers, params=params)
resp = response.json()
for items in resp["data"]["comments"]:
level = items["commentLevel"]
comment = items["content"]
comment_time = items["creationTime"]
series = items["skuAttrs"]
ip = items["ipLocation"]
# 将评论数据写入CSV文件
csv_writer.writerow([level, comment, comment_time, series, ip])
# 关闭CSV文件
csv_file.close()
首先我们将数据简单处理一下 分为评论等级,内容,评论时间,型号颜色,以及ip地址。存入csv后我们进行数据分析
首先看一下购买力TOP10
import pandas as pd
from pyecharts.charts import Bar
from pyecharts import options as opts
# 读取包含数据的 CSV 文件
df = pd.read_csv("comments.csv",
names=["评价等级", "评论内容", "评论时间", "颜色型号配置", "ip地址"])
df = df.drop_duplicates()
# 统计IP地址的数量并选择前十个
ip_counts = df["ip地址"].value_counts().head(10)
# 创建柱状图
bar = (
Bar()
.add_xaxis(ip_counts.index.tolist()) # X轴数据为前十个IP地址
.add_yaxis("IP地址数量", ip_counts.tolist(), color="#5793f3")
.set_global_opts(
title_opts=opts.TitleOpts(title="购买遥遥领先TOP10"),
xaxis_opts=opts.AxisOpts(name="地区"),
yaxis_opts=opts.AxisOpts(name="数量"),
)
)
# 渲染图表
bar.render("top_10_ip_address_counts.html")
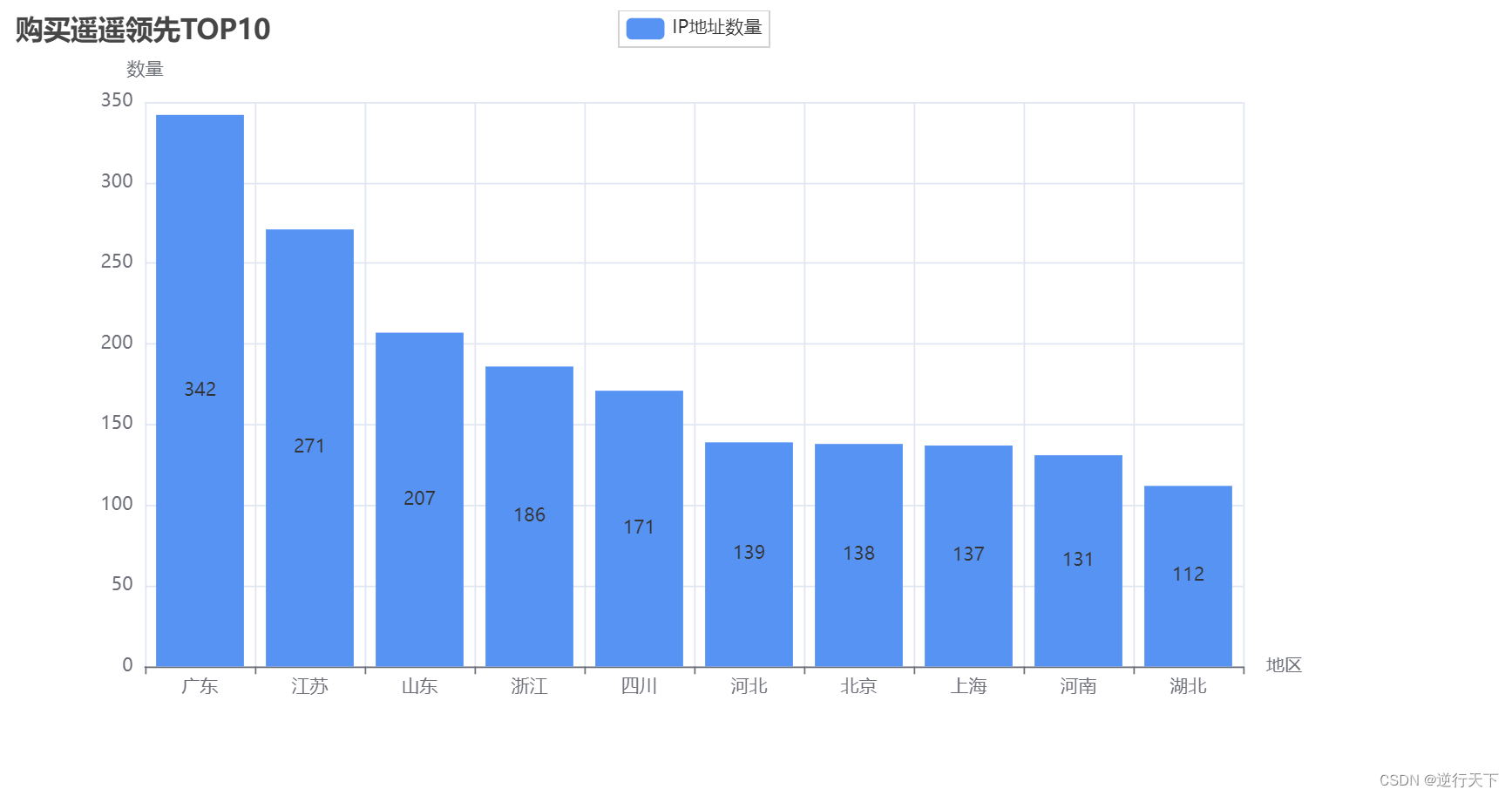
可以看到广东江苏山东浙江四川遥遥领先6666一波
下面分析一下评论内容不多说上代码
import pandas as pd
from collections import Counter
from pyecharts.charts import WordCloud
from pyecharts import options as opts
# 读取包含数据的 CSV 文件
df = pd.read_csv("comments.csv",
names=["评价等级", "评论内容", "评论时间", "颜色型号配置", "ip地址"])
df = df.drop_duplicates()
# 统计评论内容中的文字数量
comment_text = " ".join(df["评论内容"].tolist()) # 将评论内容连接成一个长字符串
words = comment_text.split() # 拆分字符串为单词列表
# 使用Counter统计每个文字的出现次数
word_counts = Counter(words)
# 找到出现最多的文字及其数量
most_common_word, most_common_count = word_counts.most_common(1)[0]
wordcloud = (
WordCloud()
.add("", [(word, count) for word, count in word_counts.items()], word_size_range=[20, 100])
.set_global_opts(
title_opts=opts.TitleOpts(title="评论内容中出现最多的文字"),
tooltip_opts=opts.TooltipOpts(formatter="{b}: {c}"),
)
)
# 渲染
wordcloud.render("most_common_wordcloud.html")



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









