







 本文介绍了Spark中RDD的持久化方法,包括cache和persist的使用,以及它们的区别。cache是默认存储在内存中的缓存,而persist允许自定义存储级别。此外,文章还探讨了CheckPoint检查点的重要性,它是将RDD数据写入磁盘以减少长血缘依赖的容错成本。checkpoint能切断血缘关系,提供更可靠的恢复方式。建议在checkpoint后配合cache提高性能。
本文介绍了Spark中RDD的持久化方法,包括cache和persist的使用,以及它们的区别。cache是默认存储在内存中的缓存,而persist允许自定义存储级别。此外,文章还探讨了CheckPoint检查点的重要性,它是将RDD数据写入磁盘以减少长血缘依赖的容错成本。checkpoint能切断血缘关系,提供更可靠的恢复方式。建议在checkpoint后配合cache提高性能。
假设我们在对RDD进行转化的时候,需要用同一个RDD得到两个结果,如下面代码所示。
val rdd = sparkContext.makeRDD(List(
("a",1),("a",2),("c",3),
("b",4),("c",5),("c",6)
),1)
val rdd1 = rdd.map(x => {
(x._1, x._2 + 1)
})
val reduceRDD = rdd1.reduceByKey(_+_)
val groupRDD = rdd1.groupByKey()
reduceRDD.collect().foreach(println)
println("xxxxxxxxxxxxxxxxx")
groupRDD.collect().foreach(println)
这里我们对rdd1使用了reduceByKey和groupByKey两个操作。看起来这并没有什么问题,对同一个RDD的数据使用两遍,实际的结果也没有问题。
(a,5)
(b,5)
(c,17)
xxxxxxxxxxxxxxxxx
(a,CompactBuffer(2, 3))
(b,CompactBuffer(5))
(c,CompactBuffer(4, 6, 7))
但实际上并不是没有问题的。
我们都知道,RDD本身是不存储数据的,只有在运行到行动算子时才会启动Job。这意味着上面的rdd1就像一条流水线一样,走过了一条路就无法调头执行另外一条路计算。
那么为什么结果没有问题呢?
那是因为RDD之间具有依赖关系,就算RDD的数据丢失,也可以根据血缘的依赖关系通过重新运算恢复数据分区。
但这就有很大的问题了。由于数据丢失了,RDD需要从元数据处重新计算一遍,这是极度耗费性能的。是否有将中间数据多用的方法呢?
这里我们就需要用到我们RDD的持久化方法了。
1. Cache缓存
RDD 通过 cache 或者 persist 方法将前面的计算结果缓存,默认情况下会把数据以缓存在 JVM 的堆内存中。但是并不是这两个方法被调用时立即缓存,而是触发后面的 action 算子时,该 RDD 将会被缓存在计算节点的内存中,并供后面重用。
val rdd = sparkContext.makeRDD(List(
("a",1),("a",2),("c",3),
("b",4),("c",5),("c",6)
),1)
val rdd1 = rdd.map(x => {
(x._1, x._2 + 1)
})
// 数据缓存。
rdd1.cache()
/ 可以更改存储级别
//mapRdd.persist(StorageLevel.MEMORY_AND_DISK_2)
val reduceRDD = rdd1.reduceByKey(_+_)
val groupRDD = rdd1.groupByKey()
reduceRDD.collect().foreach(println)
println("xxxxxxxxxxxxxxxxx")
groupRDD.collect().foreach(println)
cache和persist有什么区别?
实际上,cache 就是一种特定的persist。
def cache(): this.type = persist()
//进入persist()
def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)
StorageLevel意思是存储级别。
可以看到,cache就是设置为StorageLevel.MEMORY_ONLY的persist。这表示cache只缓存在内存中,而persist可以自行设置StorageLevel。
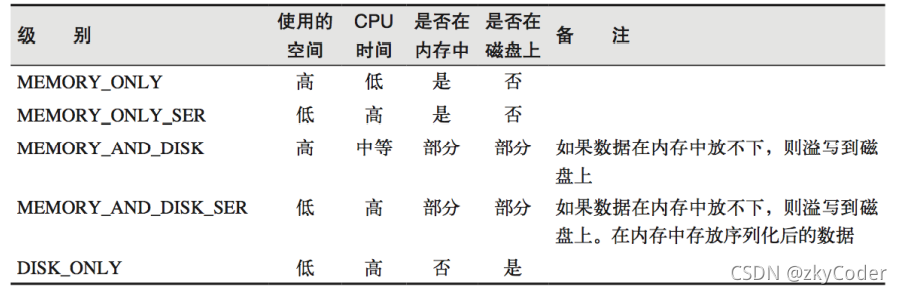
存储级别:
object StorageLevel {
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
这里2的意思是副本为2做存储。MEMORY_AND_DISK 表示优先内存,内存不足时存入磁盘持久化。
2. CheckPoint检查点
RDD的CheckPoint就是将RDD的中间结果写入磁盘。
由于血缘依赖过长会造成容错成本过高,这样就不如在中间阶段做检查点写入磁盘容错。如果检查点之后有节点出现问题,可以从检查点开始重做血缘,减少了开销。
对 RDD 进行 checkpoint 操作并不会马上被执行,必须执行 Action 操作才能触发。
由于RDD是不保存数据的,因此checkpoint操作会使得RDD重新计算一遍,因此性能最高的方法是将cache和checkpoint联合在一起使用。先把数据用cache缓存下来,再通过checkpoint实际保存到文件系统。
// 设置检查点路径
sparkContext.setCheckpointDir("./checkpoint1")
val rdd = sparkContext.makeRDD(List(
("a",1),("a",2),("c",3),
("b",4),("c",5),("c",6)
),1)
val rdd1 = rdd.map(x => {
(x._1, x._2 + 1)
})
// 增加缓存,避免再重新跑一个 job 做 checkpoint
rdd1.cache()
// 数据检查点:针对 rdd1做检查点计算
rdd1.checkpoint()
rdd1.collect().foreach(println)
Cache和CheckPoint的区别
- Cache 缓存只是将数据保存起来,不切断血缘依赖。Checkpoint 检查点切断血缘依赖。
- Cache 缓存的数据通常存储在磁盘、内存等地方,可靠性低。Checkpoint 的数据通常存储在 HDFS 等容错、高可用的文件系统,可靠性高。
建议对 checkpoint()的 RDD 使用 Cache 缓存,这样 checkpoint 的 job 只需从 Cache 缓存中读取数据即可,否则需要再从头计算一次 RDD。
参考:尚硅谷

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









