







原论文:Personalizing Dialogue Agents via Meta-Learning
Zhaojiang Lin*, Andrea Madotto*, Chien-Sheng Wu, Pascale Fung ACL 2019
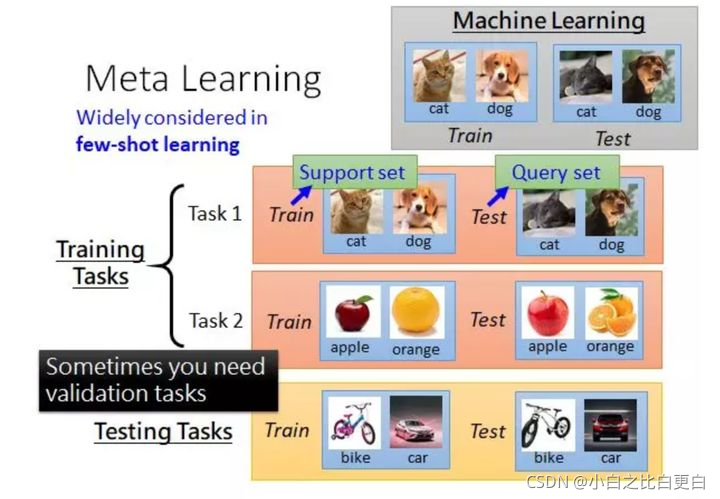
元学习基础
元学习的基础知识可以去看李宏毅老师的视频,讲得比较清晰。视频地址
摘要
问题:
现有的个性化对话模型使用人类设计的角色描述来提高对话的一致性。从现有对话框中收集这样的描述是昂贵的,并且需要手工制作功能设计。
贡献:
将模型不可知论元学习(MAML) 扩展到不使用任何人物描述的个性化对话学习。通过仅利用从同一用户收集的几个对话样本来学习快速适应新的角色,这与将响应限制在角色描述上是完全不同的。
结果:
在Persona-chat数据集上的经验结果表明,在自动评估指标和人类评估的流畅性和一致性方面优于基准模型。
作者的思路
一些相关技术就不写了。 从思路开始。
作者认为通过元学习算法学习不同的角色是不同的任务,这与优化模型来代表所有的角色是根本不同的。这篇论文的目标是学习一个与人物角色无关的模型,该模型能够快速适应给定对话的新人物角色。将这个任务描述为一个简单的学习问题。我们期望了解对话模型的初始参数,它可以通过使用少量对话快速适应特定人物的反应风格。
本文的主要贡献是将个性化对话学习作为一个元学习问题,这使得我们的模型可以通过有效地利用少数对话而不是人类设计来产生个性化的任务角色。
模型PMAL
根据历史对话、角色属性生成对话可以如下表示:
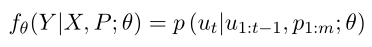
在PMAL中,目的是仅使用历史对话进行学习,避免收集数据的代价,因此将角色属性去掉。
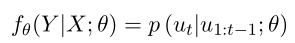
划分数据:
首先,将所有的对话划分为训练集、验证集、测试集。
然后在每一个训练回合中,在训练集中抽取相同大小的样本。
抽取的样本再分为训练和验证两个集。
训练流程:
数据划分好后就是如何训练,原文给出了训练的伪代码.
那么,训练时如何更新权重呢?
在每个任务中,有一个α是内部学习率(inner optimization),与机器学习类似,采用交叉熵损失。
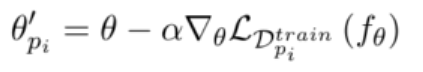
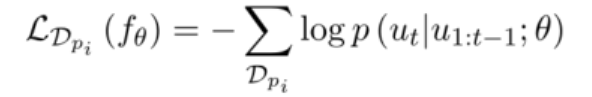
在每个任务外,β为外部学习率(meta-learning rate)。对于每一轮,可以理解,meta-learning的最终的目标是使得学习的每一个任务的损失之和达到最小。即:
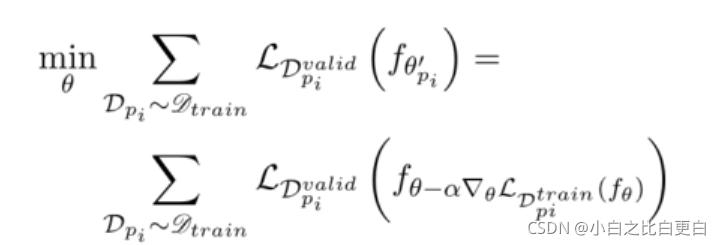
因此,在任务外部的更新如下:

这个过程需要二阶优化偏导数。

有一个让我很疑惑地地方,作者说原数据分成训练集、验证集和测试集,但是通篇没有看到验证集是干什么了?是用做development set了吗?
实验与结果
使用数据集:Personachat。数据集中平均每个角色描述有8.3个的对话。
实验结果:
C是c-score。
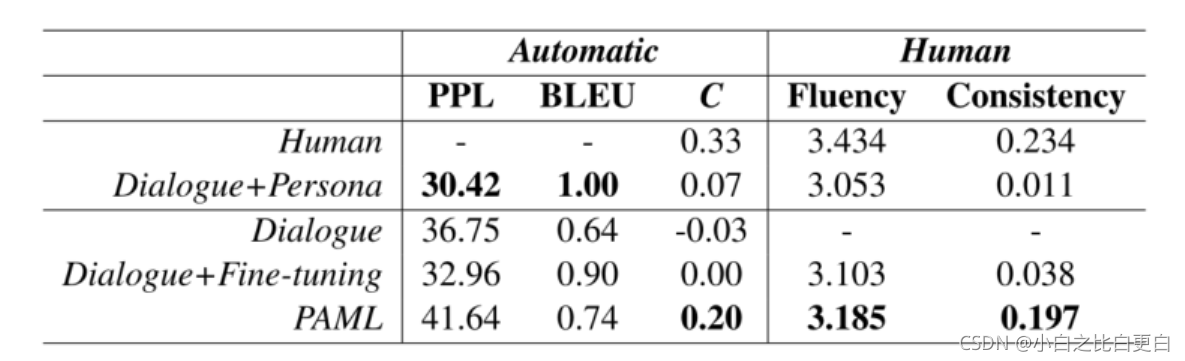
预训练模型使用标准Transformer架构和预训练的嵌入(Pennington et al.,2014)。对于基准模型的训练,使用了Adam (Kingma and Ba,2014)优化器和学习率策略,批量大小为32。在元模型训练中,使用SGD作为内优化器,Adam作为外优化器,学习率分别为α= 0.01和β= 0.0003,batch规模均为16。
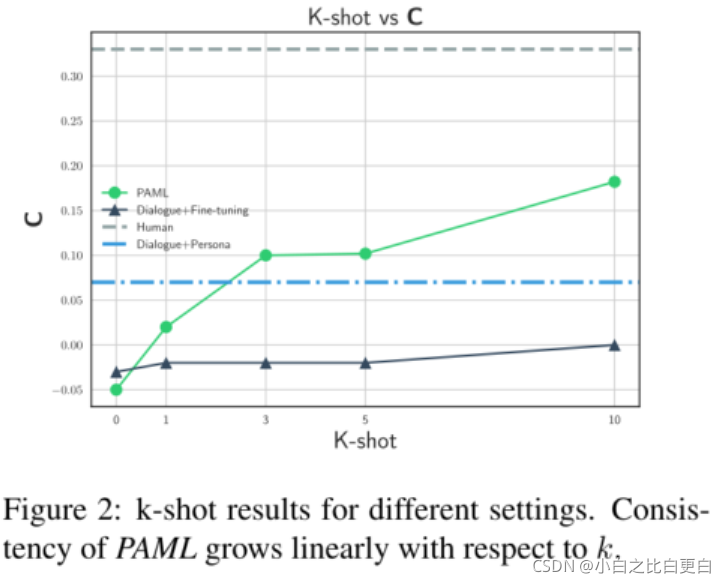
作者还采用了Few-shot Learning来测试模型。即每个任务采用不同多个样本进行训练的结果。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









