




 非平衡数据在实际预测任务中常见,如广告点击率、商品推荐和贷款违约预测。未处理可能导致高准确率但低实际效果。常用处理方法包括数据层面的过采样(如SMOTE)和欠采样(如Tomek link),以及算法层面的集成方法(如平衡随机森林)和代价敏感学习。过采样与欠采样结合能有效降低过拟合风险。
非平衡数据在实际预测任务中常见,如广告点击率、商品推荐和贷款违约预测。未处理可能导致高准确率但低实际效果。常用处理方法包括数据层面的过采样(如SMOTE)和欠采样(如Tomek link),以及算法层面的集成方法(如平衡随机森林)和代价敏感学习。过采样与欠采样结合能有效降低过拟合风险。
1、非平衡数据
常见的分类模型中一般假设分类类别的比例是均衡的,但是现实中常出现正负样本数量不均衡的情况,比如对广告点击情况进行预测(广告点击率是比较少的),商品推荐(推荐商品被购买的数量比较少),贷款违约预测(违约的情况比较少),那么就需要对非平衡数据进行处理。
如果不处理,比如正类占比99%,负类占比1%,那么预测的准确度至少在99%以上,这样的预测没有意义。
在类别不平衡的情况下,F值和AUC去评判模型分类的效果是不错的选择。
2、处理非平衡数据
- 数据层面:改变数据分布,从数据层面使得数据类别变得平衡。
- 算法层面:改进传统的算法,使得算法对少数类赋更大的权重。
3、数据层面
3.1 过采样
随机过采样
设置正负样本比率,对于少数类样本采用随机复制的方法,增加少数类样本。
优点:操作简单,只依赖于数据分布,不依赖其他信息。
缺点:数据中会出现较多重复的数据,容易发生分类器的过拟合。
SMOTE算法:将距离较近的少数类进行线性组合,产生新的样本,由于不是简单的复制,在一定程度上降低了过拟合的风险。
缺陷:每个少数类的携带信息不同,利用边界信息的样本产生样本,将产生噪声。
因此采用SMOTE与边界信息结合的方法产生新样本(borderlink smote算法)。
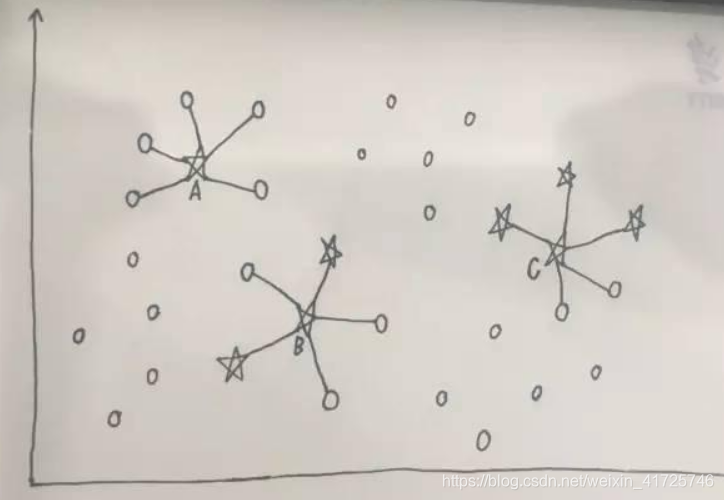
3.2 欠采样
随机欠采样
在保持少数类样本不变的情况下,设置征服类样本比率,随机剔除多数类样本。
优点:操作简单,只依赖于数据分布,不依赖其他信息。
缺点:会丢失部分多数类样本的信息。
Tomek link:将距离最近的两个不同类样本组成link对。
两种用法:
欠采样用法:去掉link对中多数类的那个样本。
数据清洗用法:去掉这样的link对,让数据区分更明显。
其他的欠采样算法:
nearmiss-1:多数类中,挑选与三个少数类平均距离最近的样本。(局部,距离)
nearmiss-2:多数类中,挑选与三个少数类平均距离最远的样本。(全局)
nearmiss-3:对于每个少数类,选择与它距离最近的若干个多数类样本。
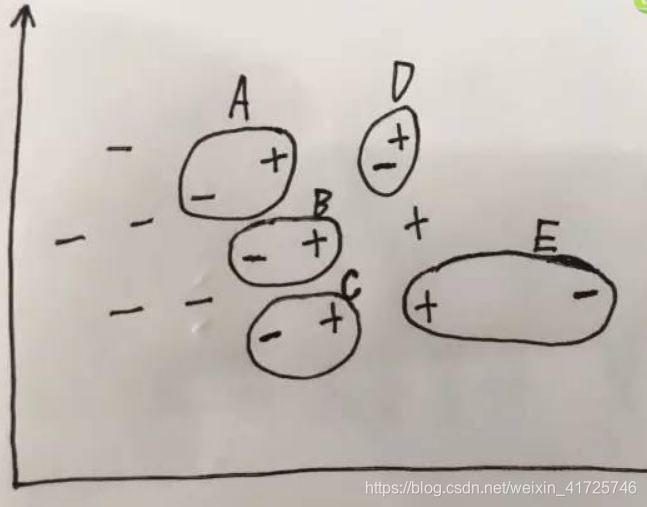
3.3 过采样与欠采样结合
SMOTE+Tomek link相结合的方法
通过SMOTE增加少数类样本,但是会存在少数类样本侵入多数类样本,容易造成过拟合;然后采用Tomek link的方法,剔除link对,这样可以有效的剔除噪声点和边界点,抗过拟合。
SMOTE+ENN算法也可以实现上述作用。
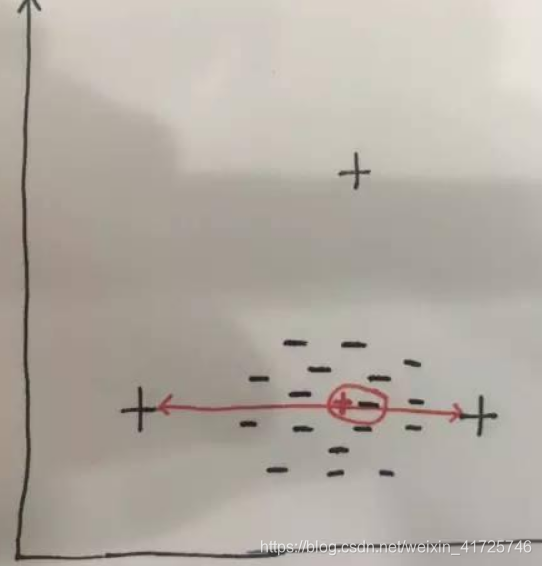
4、算法层面
集成方法
平衡随机森林的方法,该方法对正类和反类分别进行重采样,重采样多次后采用多数投票的方法进行集成学习。
将boosting算法与SMOTE算法结合成SMOTEBoost算法,该算法每次迭代使用SMOTE生成新的样本,取代原有AdaBoost算法中对样本权值的调整,使得Boosting算法专注于正类中的难分样本。
代价敏感方法
在大部分不平衡分类问题中,稀有类是分类的重点。在这种情况下,正确识别出稀有类的样本比识别大类的样本更有价值。反过来说,错分稀有类的样本需要付出更大的代价。代价敏感学习赋予各个类别不同的错分代价(Cost),它能很好地解决不平衡分类问题。以二分类问题为例,假设正类是稀有类,并具有更高的错分代价,则分类器在训练时,会对错分正类样本做更大的惩罚迫使最终分类器对正类样本有更高的识别率。如Metacost和Adacost等算法。

















 1121
1121

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









